Adaptação de Modelos de IA para Aplicativos Móveis: Privacidade e Eficiência com Dados Sintéticos e Federados

A evolução da inteligência artificial (IA) tem transformado a forma como interagimos com nossos dispositivos móveis. No entanto, adaptar modelos de linguagem de grande escala (LLMs) para aplicações móveis apresenta desafios significativos, especialmente quando se trata de preservar a privacidade dos usuários e garantir a eficiência do processamento.
Introdução à Adaptação de Domínio em IA para Dispositivos Móveis
Os modelos de linguagem de grande escala são poderosos, mas geralmente treinados em grandes conjuntos de dados genéricos que podem não refletir as especificidades de um domínio ou aplicação móvel. A adaptação de domínio visa ajustar esses modelos para que eles funcionem melhor em contextos específicos, como assistentes pessoais, aplicativos de tradução ou sistemas de recomendação em smartphones.
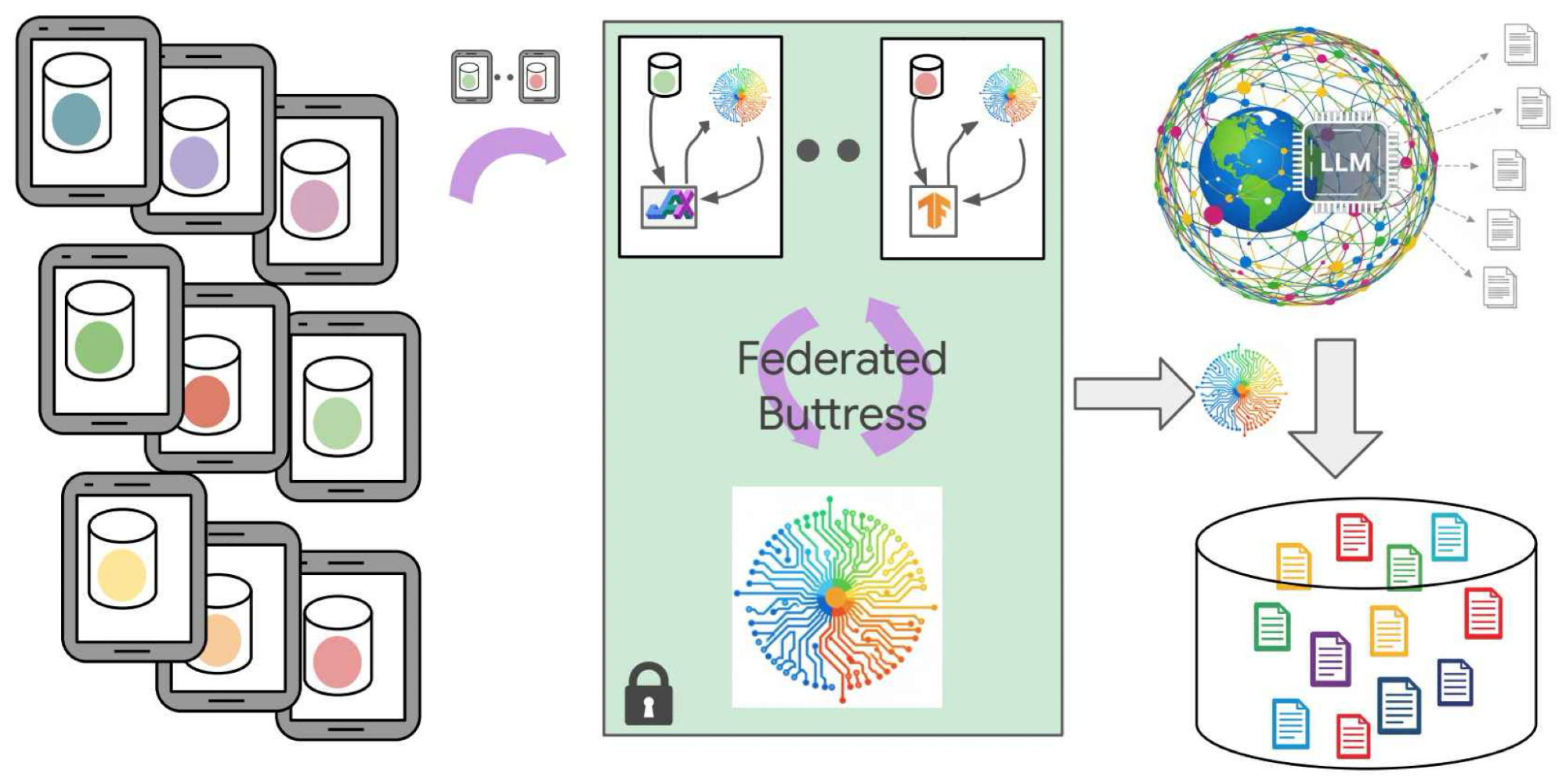
No entanto, essa adaptação tradicionalmente requer acesso a dados sensíveis do usuário, o que levanta preocupações sérias de privacidade. Além disso, o poder computacional limitado dos dispositivos móveis impõe restrições adicionais.
Privacidade Preservada com Dados Sintéticos e Aprendizado Federado
Para superar esses desafios, pesquisadores do Google propuseram uma abordagem inovadora que combina a geração de dados sintéticos com aprendizado federado, garantindo que a adaptação do modelo respeite a privacidade dos usuários e seja eficiente para dispositivos móveis.
Geração de Dados Sintéticos
Dados sintéticos são informações geradas artificialmente que imitam as características dos dados reais sem expor informações pessoais. Utilizando técnicas avançadas de IA generativa, é possível criar conjuntos de dados que refletem o comportamento e as necessidades do usuário, mas sem comprometer sua privacidade.
Aprendizado Federado
O aprendizado federado permite que o modelo seja treinado diretamente nos dispositivos dos usuários, enviando apenas atualizações do modelo para um servidor central, sem compartilhar os dados brutos. Isso reduz o risco de vazamento de informações sensíveis e melhora a segurança do processo.
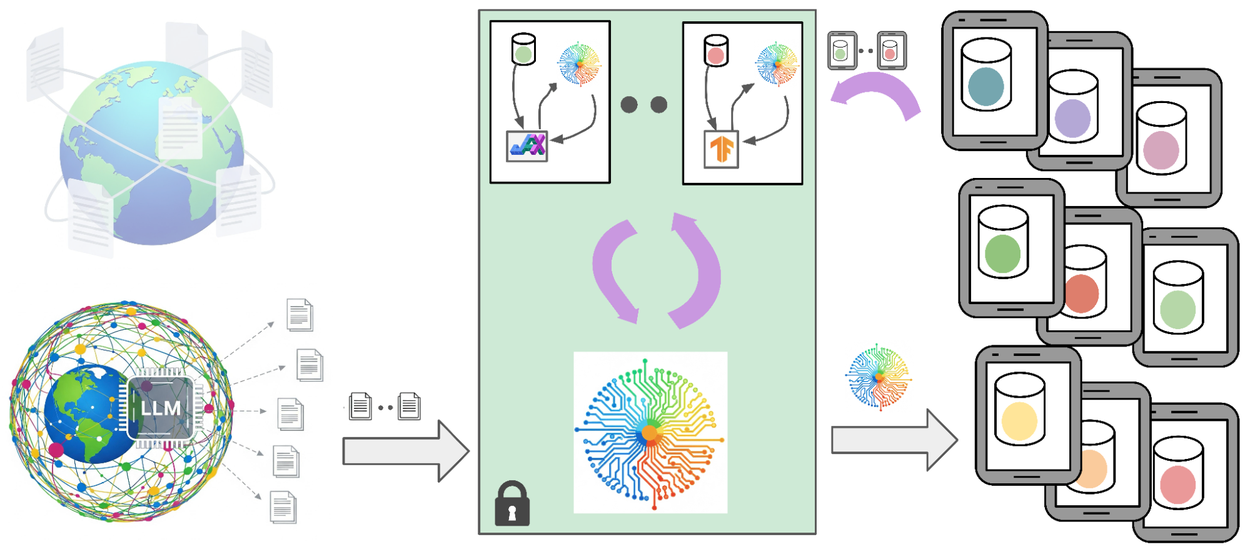
Benefícios da Abordagem para Aplicações Móveis
- Privacidade reforçada: Os dados pessoais nunca saem do dispositivo, e os dados sintéticos evitam exposição direta.
- Eficiência computacional: O uso de LLMs adaptados para dispositivos móveis otimiza o desempenho sem sacrificar a qualidade.
- Personalização: Modelos ajustados localmente oferecem respostas e funcionalidades mais alinhadas ao contexto do usuário.
- Escalabilidade: A combinação de dados sintéticos e aprendizado federado facilita a adaptação em larga escala sem comprometer a segurança.
Desafios e Perspectivas Futuras
Apesar dos avanços, ainda existem desafios a serem superados, como a complexidade de gerar dados sintéticos altamente representativos e a necessidade de otimizar ainda mais os modelos para o hardware móvel.
Além disso, garantir a transparência e a responsabilidade no uso desses métodos é fundamental para a confiança dos usuários e a adoção em massa.
Conclusão
A integração de dados sintéticos e aprendizado federado representa um avanço significativo na adaptação de modelos de linguagem para dispositivos móveis, equilibrando desempenho e privacidade. Essa abordagem abre caminho para aplicações de IA mais seguras, personalizadas e eficientes, alinhadas às demandas atuais de proteção de dados e experiência do usuário.
À medida que a tecnologia evolui, espera-se que essas técnicas se tornem padrão no desenvolvimento de soluções móveis baseadas em IA, promovendo uma nova era de inovação responsável.