Alinhamento de Modelos Visão-Linguagem com TRL: O Futuro da IA Multimodal

Nos últimos anos, a inteligência artificial tem avançado rapidamente, especialmente na área de modelos que combinam visão e linguagem. Esses modelos multimodais são capazes de interpretar imagens e textos simultaneamente, abrindo portas para aplicações inovadoras, desde assistentes visuais até sistemas de geração de conteúdo. Um dos desafios cruciais nesse campo é o alinhamento desses modelos para garantir que suas respostas sejam coerentes, precisas e seguras.
O que é o Alinhamento em Modelos Visão-Linguagem?
O alinhamento, no contexto de IA, refere-se ao processo de ajustar um modelo para que ele se comporte conforme as expectativas humanas, evitando respostas inadequadas, enviesadas ou irrelevantes. Para modelos que entendem tanto imagens quanto texto, esse processo é ainda mais complexo, pois envolve interpretar corretamente a informação visual e textual de forma integrada.
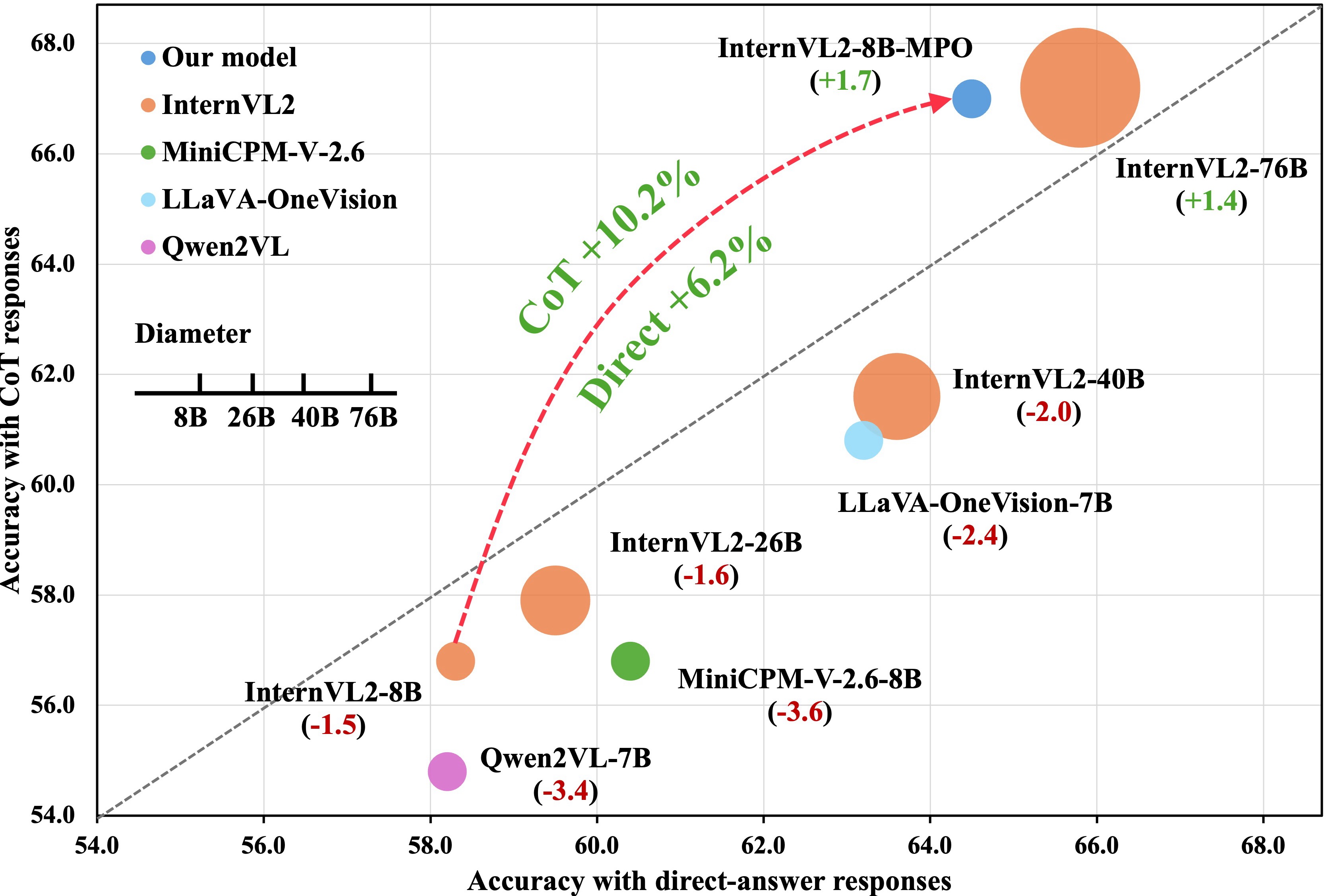
Por que o alinhamento é importante?
- Precisão: Garante que as respostas sejam corretas e relevantes.
- Segurança: Minimiza riscos de respostas ofensivas ou perigosas.
- Usabilidade: Melhora a experiência do usuário, tornando a interação mais natural.
TRL: Uma Abordagem Inovadora para o Alinhamento
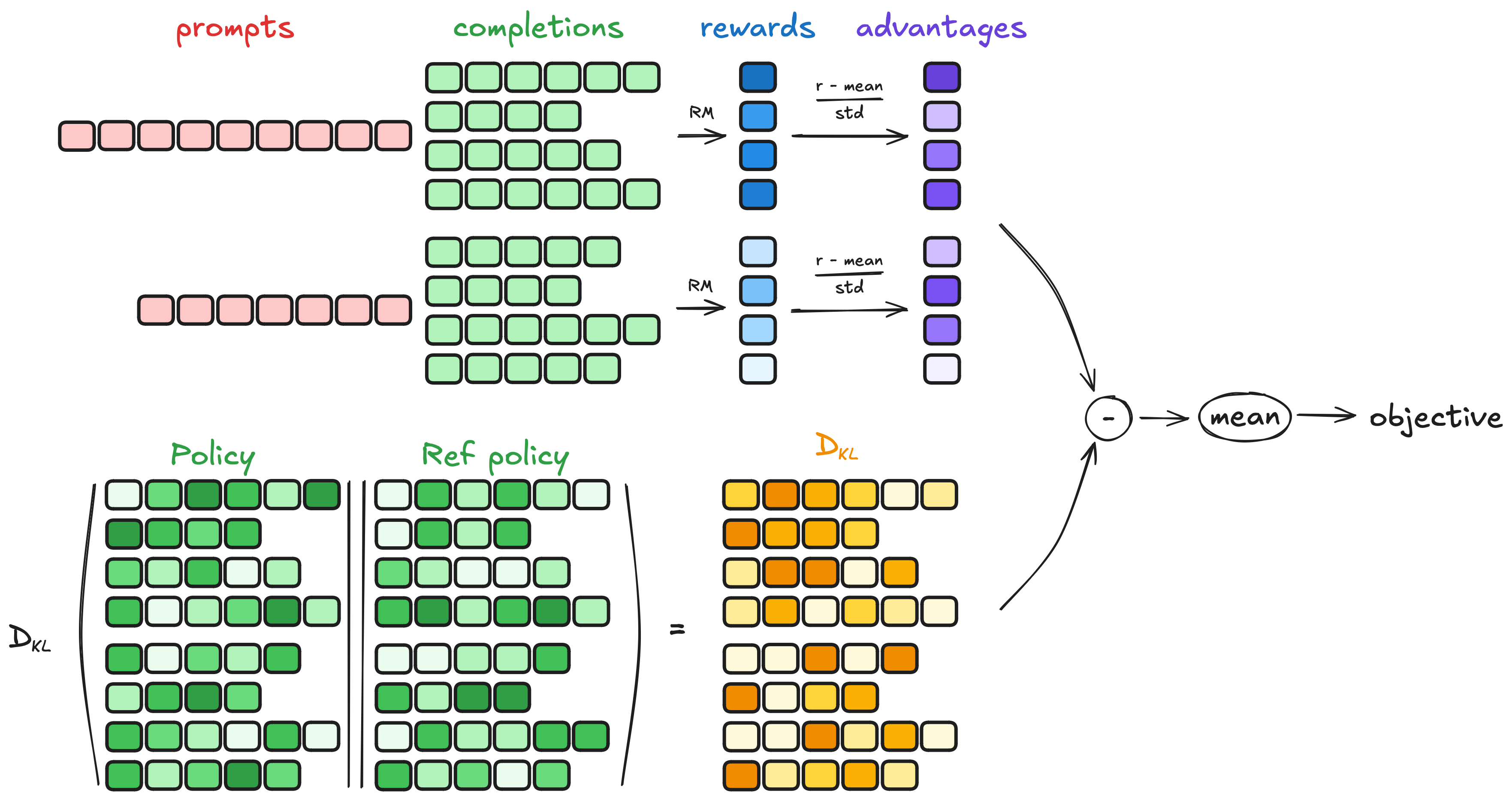
TRL (Transformer Reinforcement Learning) é uma técnica que vem ganhando destaque para alinhar modelos de linguagem e visão. Ela combina o poder dos transformadores, que são a base dos modelos modernos de IA, com aprendizado por reforço, permitindo que o sistema aprenda com feedbacks e melhore continuamente.
Como o TRL funciona?
O TRL utiliza um ciclo de treinamento onde o modelo gera respostas baseadas em imagens e textos, que são avaliadas por um sistema de recompensa. Esse sistema pode ser um conjunto de regras, um modelo avaliador ou até mesmo feedback humano. Com base nessa avaliação, o modelo ajusta seus parâmetros para maximizar as recompensas, aprimorando seu alinhamento.
- Etapa 1: O modelo recebe uma imagem e um prompt textual.
- Etapa 2: Gera uma resposta multimodal.
- Etapa 3: A resposta é avaliada e recebe uma pontuação.
- Etapa 4: O modelo ajusta seu comportamento para melhorar futuras respostas.
Benefícios do Alinhamento via TRL em Modelos Visão-Linguagem
Implementar o TRL para alinhamento traz diversos benefícios práticos e estratégicos:
- Melhora na qualidade das respostas: As respostas se tornam mais coerentes e contextualizadas.
- Redução de vieses: O aprendizado por reforço permite corrigir respostas enviesadas ao longo do tempo.
- Adaptação contínua: O modelo pode se ajustar a novos dados e contextos sem necessidade de retrainings extensivos.
- Experiência do usuário aprimorada: Interações mais naturais e confiáveis aumentam a satisfação.
Desafios e Considerações
Apesar dos avanços, o alinhamento via TRL ainda enfrenta desafios importantes:
- Complexidade computacional: O processo de aprendizado por reforço pode ser custoso em termos de recursos.
- Definição de recompensas: Criar métricas de avaliação que reflitam valores humanos é complexo e subjetivo.
- Escalabilidade: Adaptar o método para modelos cada vez maiores e mais complexos requer inovação contínua.
O Futuro dos Modelos Visão-Linguagem Alinhados
O uso do TRL para alinhamento representa um passo importante para tornar modelos multimodais mais confiáveis e úteis. Com a evolução dessa técnica, podemos esperar sistemas capazes de interpretar e interagir com o mundo visual e textual de maneira cada vez mais humana e segura.
Esses avanços abrirão portas para aplicações revolucionárias, como assistentes pessoais visuais, ferramentas de acessibilidade para pessoas com deficiência, sistemas de diagnóstico médico e muito mais.
Conclusão
O alinhamento de modelos visão-linguagem por meio do TRL é uma fronteira promissora na inteligência artificial. Ao combinar aprendizado por reforço com modelos transformadores, essa abordagem permite que sistemas multimodais evoluam de forma contínua, alinhando-se melhor às expectativas humanas e aumentando sua utilidade prática.
Para profissionais e entusiastas de IA, acompanhar esses desenvolvimentos é fundamental para entender o futuro da interação entre humanos e máquinas, que será cada vez mais multimodal e integrada.