Aprimorando Modelos de Linguagem com Privacidade Diferencial no Nível do Usuário

Nos últimos anos, os grandes modelos de linguagem (LLMs) revolucionaram a forma como interagimos com a tecnologia, impulsionando avanços em processamento de linguagem natural, assistentes virtuais e sistemas de recomendação. No entanto, o treinamento e ajuste fino desses modelos frequentemente envolvem o uso de dados sensíveis de usuários, levantando preocupações significativas sobre privacidade.
O desafio da privacidade em LLMs
Os LLMs são treinados com vastas quantidades de dados textuais que podem conter informações pessoais. Durante o ajuste fino (fine-tuning), que é a etapa de especialização do modelo para tarefas específicas, a exposição a dados de usuários pode levar a vazamentos não intencionais de informações privadas. Isso torna crucial a adoção de técnicas que garantam a privacidade dos dados sem comprometer o desempenho do modelo.
Privacidade diferencial no nível do usuário: o que é?
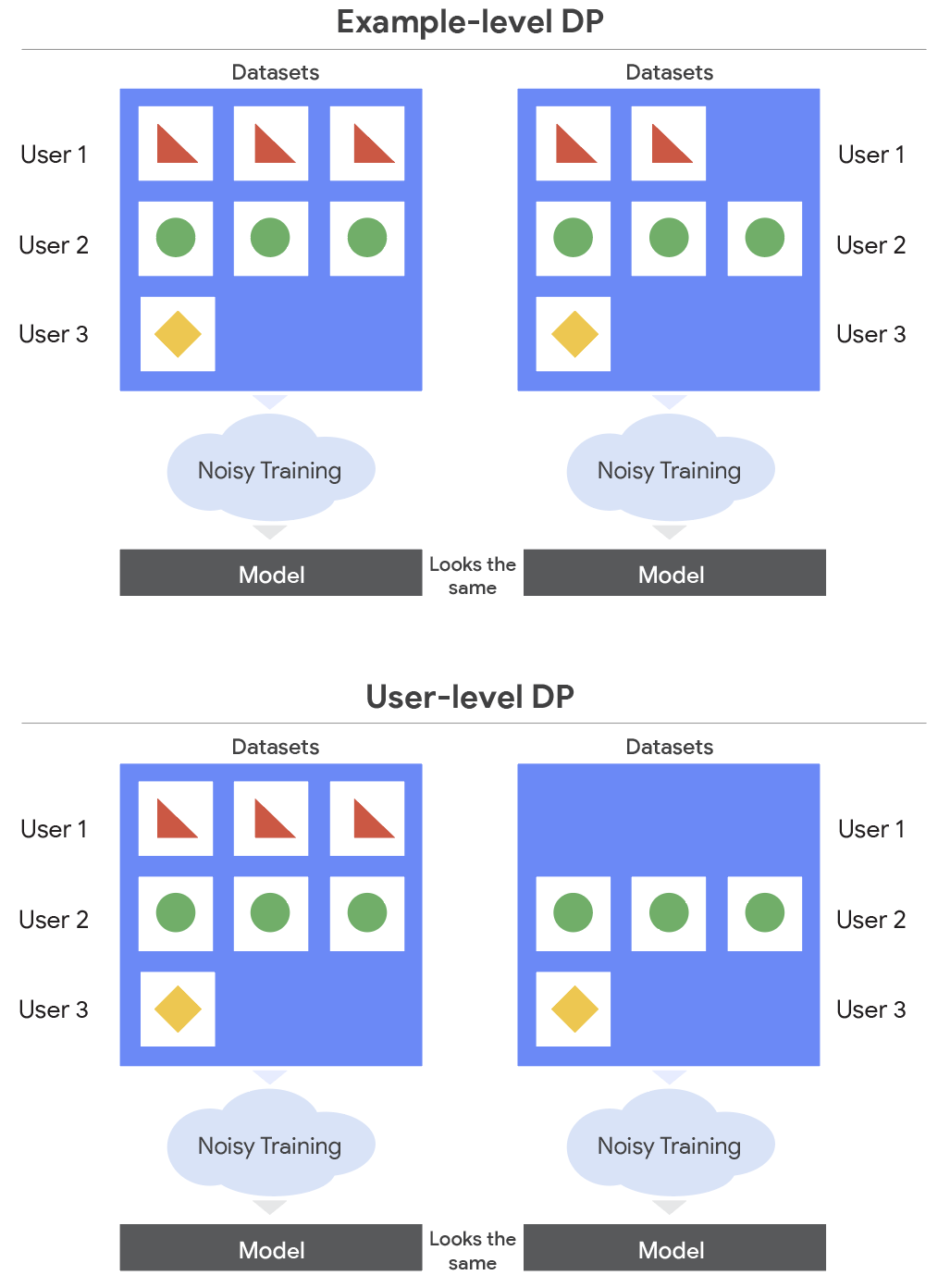
A privacidade diferencial é uma abordagem matemática que assegura que a saída de um algoritmo não revele informações específicas sobre qualquer indivíduo em um conjunto de dados. Quando aplicada no nível do usuário, essa técnica protege todos os dados associados a uma única pessoa, garantindo que o modelo não aprenda detalhes identificáveis de nenhum usuário individual.
Como funciona na prática?
- Ruído controlado: Durante o treinamento, são adicionadas pequenas perturbações (ruído) aos gradientes ou parâmetros para dificultar a extração de dados pessoais.
- Limitação de influência: O impacto dos dados de cada usuário no modelo final é restrito, evitando que informações sensíveis sejam memorizadas.
- Garantias matemáticas: A privacidade diferencial fornece limites formais sobre o quanto o modelo pode revelar sobre qualquer dado individual.
Contribuições recentes do Google Research
Pesquisadores do Google Research desenvolveram algoritmos avançados para realizar o fine-tuning de LLMs com privacidade diferencial no nível do usuário. Suas principais contribuições incluem:
- Escalabilidade: Métodos que permitem aplicar privacidade diferencial em modelos muito grandes, mantendo eficiência computacional.
- Equilíbrio entre privacidade e utilidade: Técnicas que minimizam a perda de desempenho do modelo mesmo com as restrições de privacidade.
- Segurança robusta: Mecanismos que previnem abusos e vazamentos de dados durante o processo de treinamento.
Por que isso importa para o futuro da IA?
À medida que a Inteligência Artificial se torna cada vez mais integrada ao nosso cotidiano, proteger a privacidade dos usuários é fundamental para manter a confiança e a ética no desenvolvimento tecnológico. A aplicação de privacidade diferencial no ajuste fino de LLMs abre caminho para:
- Modelos mais seguros: Reduzindo riscos de exposição de dados pessoais.
- Conformidade regulatória: Atendendo a legislações de proteção de dados como a LGPD e GDPR.
- Inovação responsável: Incentivando o uso de dados reais sem comprometer a privacidade.
Conclusão
O avanço das técnicas de fine-tuning de LLMs com privacidade diferencial no nível do usuário representa um marco importante para a Inteligência Artificial. Ao garantir que modelos poderosos possam ser treinados e adaptados sem expor informações sensíveis, essa abordagem equilibra inovação e responsabilidade. Para desenvolvedores, pesquisadores e usuários, essa é uma notícia promissora que reforça o compromisso com a segurança e a ética na era digital.
Fique atento às próximas atualizações do IA em Foco para entender como essas tecnologias continuarão a transformar o cenário da Inteligência Artificial.