Avaliações de IA: o novo gargalo computacional que desafia pesquisadores e indústria

O aumento exponencial dos custos em avaliações de IA
Nos últimos anos, a avaliação de modelos de inteligência artificial (IA) tem se tornado um desafio financeiro e computacional tão grande quanto o próprio treinamento dos modelos. De acordo com um relatório recente da Hugging Face, executar benchmarks em agentes de IA avançados já ultrapassa a barreira dos US$ 40 mil para dezenas de milhares de execuções, evidenciando que o custo da avaliação está se tornando o principal gargalo para a pesquisa e desenvolvimento na área.
Por que avaliar modelos de IA está tão caro?
Historicamente, o treinamento de modelos consumia a maior parte dos recursos computacionais. Porém, com a complexidade crescente dos agentes de IA, a avaliação passou a exigir múltiplas execuções longas, com variações em configurações, cenários e parâmetros. Isso resulta em custos multiplicados, que podem ultrapassar em muito o preço do próprio treinamento.
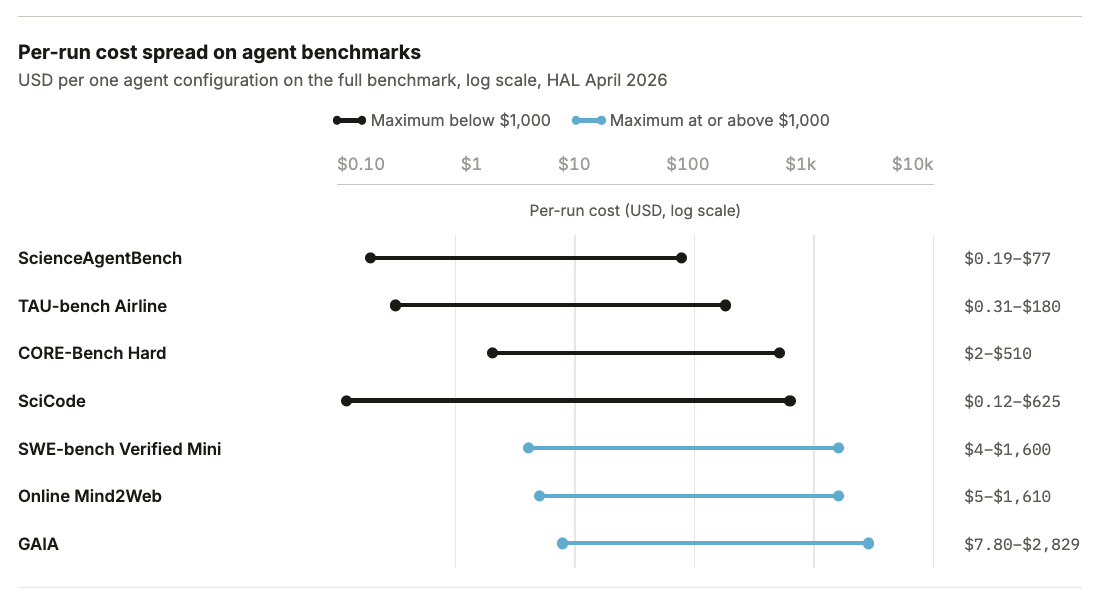
Por exemplo, a Holistic Agent Leaderboard (HAL) gastou cerca de US$ 40 mil para realizar 21.730 execuções (rollouts) de agentes em 9 modelos e 9 benchmarks diferentes. Uma única execução no modelo GAIA pode custar até US$ 2.829, sem considerar otimizações como cache. Além disso, variações simples na configuração do agente podem multiplicar o custo em até 33 vezes para tarefas idênticas.
Diferenças entre benchmarks estáticos, agentes e treinamento em loop
Benchmarks estáticos, que avaliam modelos com base em predições fixas, ainda conseguem ser comprimidos e otimizados para reduzir custos em até 100 a 200 vezes, mantendo a fidelidade dos rankings. Exemplos como o HELM da Stanford demonstram que, apesar de caros (com custos somados que podem ultrapassar US$ 100 mil), tais benchmarks permitem estratégias de avaliação em múltiplas etapas, filtrando candidatos com avaliações mais baratas antes de gastar recursos com execuções completas.
Por outro lado, benchmarks baseados em agentes são mais complexos e ruidosos. Cada execução envolve múltiplas interações, decisões e variações, dificultando a compressão e a redução de custos. A compressão máxima observada para esses benchmarks é de apenas 2 a 3,5 vezes, muito inferior aos benchmarks estáticos.
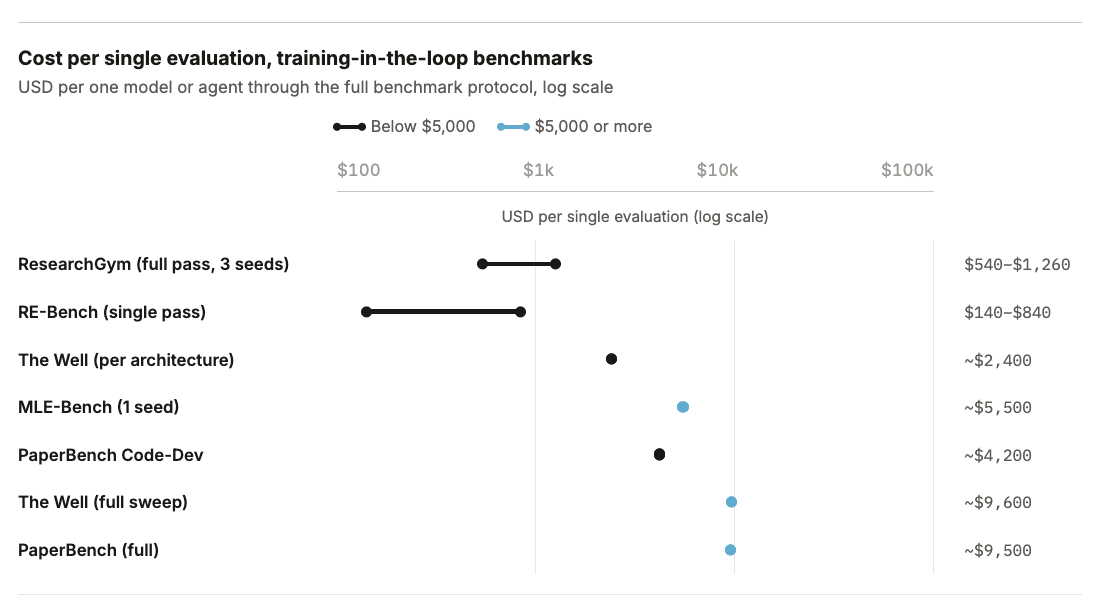
Finalmente, benchmarks que envolvem treinamento no loop, como o The Well e o PaperBench, exigem treinar modelos inteiros para cada avaliação, o que pode custar milhares de horas em GPUs de alta performance, traduzindo-se em custos de milhares a dezenas de milhares de dólares por avaliação. Nesses casos, o custo da avaliação supera o do treinamento.
O desafio da confiabilidade e a multiplicação dos custos
Além do custo base da avaliação, garantir a confiabilidade dos resultados exige múltiplas execuções para reduzir o ruído estatístico. Estimativas indicam que realizar 8 execuções por configuração pode multiplicar os custos em até 8 vezes. Por exemplo, a avaliação completa da HAL, que custa US$ 40 mil, pode ultrapassar US$ 320 mil para garantir confiabilidade estatística.
Esse aumento de custo é um desafio para pesquisadores acadêmicos e institutos de segurança em IA, que frequentemente não dispõem de orçamentos suficientes para avaliações robustas. Avaliações confiáveis exigem recursos que muitas vezes superam os disponíveis fora da indústria.
Consequências práticas para o campo de IA
- Barreira de responsabilidade: A alta despesa impede que grupos independentes avaliem modelos de ponta, limitando a transparência e a fiscalização externa.
- Divisão computacional: A diferença entre recursos da indústria e da academia se amplia não apenas no treinamento, mas também na capacidade de avaliação.
- Incentivos distorcidos: Leaderboards que não consideram custo podem incentivar o desperdício de recursos para obter ganhos mínimos em métricas de acurácia.
Para combater isso, algumas iniciativas, como a HAL, já implementam frentes de Pareto que equilibram custo e desempenho, promovendo comparações mais eficientes e realistas.
Links úteis para aprofundamento e ferramentas
- Artigo original da Hugging Face
- lm-eval-harness – Ferramenta para avaliação de modelos de linguagem
- HELM – Benchmark holístico para modelos de linguagem
- METR's RE-Bench – Relatório sobre avaliação em pesquisa e desenvolvimento de IA
- Preços da Hugging Face