Cascatas Especulativas: A Revolução Híbrida para Inferência Mais Rápida e Inteligente em Grandes Modelos de Linguagem

Nos últimos anos, os Grandes Modelos de Linguagem (LLMs) têm transformado a forma como interagimos com a inteligência artificial, possibilitando avanços impressionantes em geração de texto, tradução automática, assistentes virtuais e muito mais. No entanto, a eficiência na inferência desses modelos ainda representa um desafio significativo, especialmente quando buscamos respostas rápidas e precisas em aplicações do mundo real.
Introdução às Cascatas Especulativas
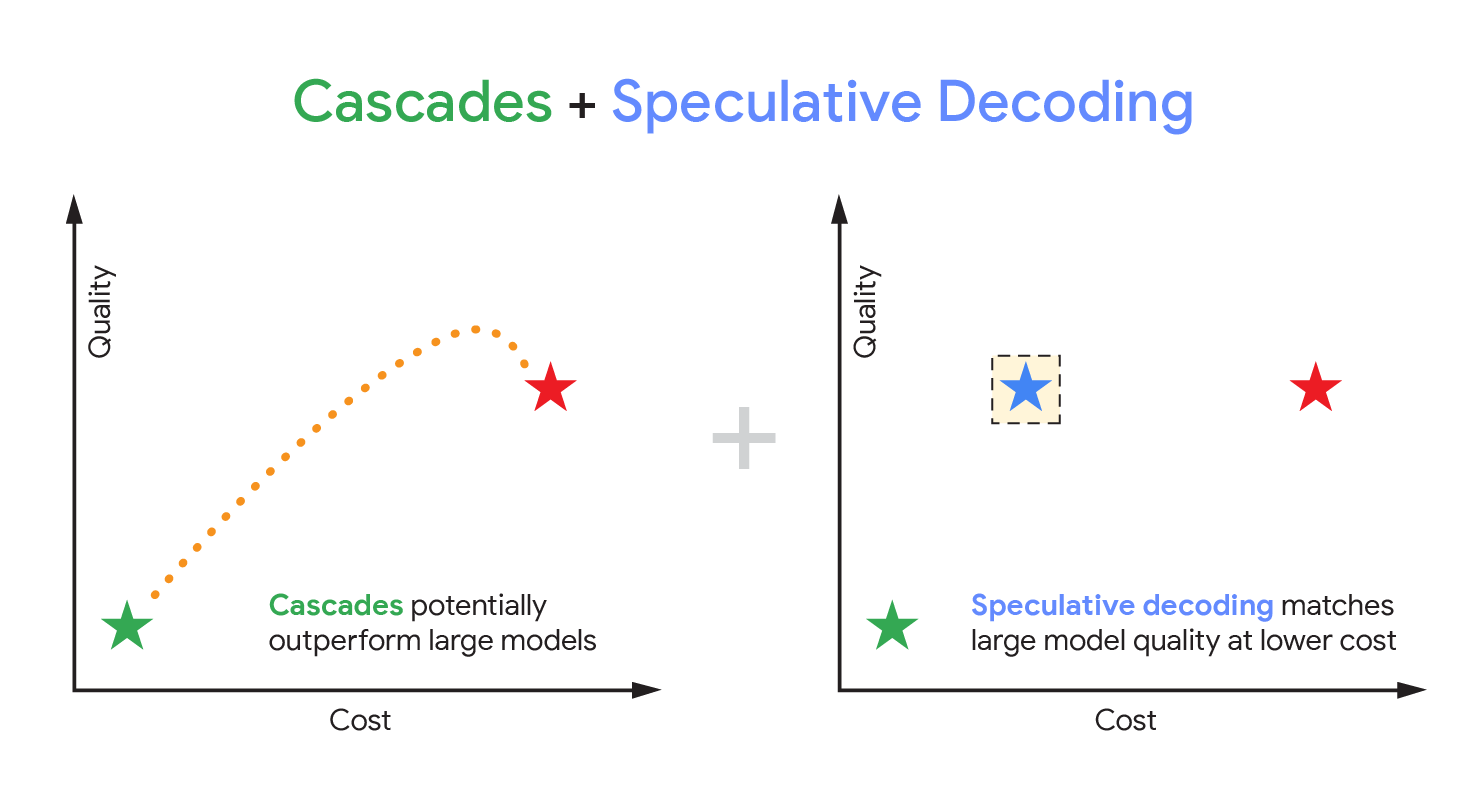
Pesquisadores do Google Research desenvolveram uma abordagem inovadora chamada cascatas especulativas (speculative cascades) que combina o melhor de dois mundos: a velocidade de modelos menores e a precisão de modelos maiores. Essa técnica híbrida promete acelerar a inferência em LLMs, tornando a geração de texto mais eficiente sem comprometer a qualidade.
O Desafio da Inferência em LLMs
Grandes modelos de linguagem, como o GPT-4 e outros similares, possuem bilhões de parâmetros que demandam enorme poder computacional para gerar respostas. Isso pode resultar em latências elevadas e custos altos, especialmente em aplicações que exigem respostas em tempo real.
Por outro lado, modelos menores são mais rápidos e econômicos, mas normalmente apresentam desempenho inferior em termos de coerência e qualidade do texto gerado.
Como equilibrar velocidade e qualidade?
É exatamente essa questão que as cascatas especulativas buscam resolver. A ideia central é utilizar um modelo menor para gerar uma previsão inicial rápida, que é então verificada e refinada por um modelo maior, garantindo que o resultado final mantenha a excelência esperada.
Como Funcionam as Cascatas Especulativas?
- Modelo Especulativo (Menor): gera rapidamente uma sequência inicial de tokens (palavras ou fragmentos de texto).
- Modelo Verificador (Maior): avalia a sequência proposta para confirmar sua validade ou corrigi-la, garantindo a qualidade do output.
- Processo Iterativo: se o modelo verificador rejeitar a sequência, o modelo especulativo gera uma nova tentativa, acelerando a convergência para uma resposta correta.
Essa dinâmica permite que a inferência aproveite a agilidade do modelo menor para explorar possibilidades, enquanto o modelo maior atua como um guardião da precisão e coerência.
Benefícios da Abordagem Híbrida
- Redução do tempo de resposta: ao evitar que o modelo maior precise gerar toda a sequência do zero, a inferência se torna mais rápida.
- Economia de recursos computacionais: o modelo maior é acionado apenas para validação e ajustes, diminuindo o custo energético e financeiro.
- Manutenção da qualidade: a supervisão do modelo maior assegura que o texto final não perca em qualidade, mesmo com a participação do modelo menor.
- Flexibilidade: a técnica pode ser adaptada para diferentes tipos de LLMs e aplicações, desde chatbots até sistemas de geração de conteúdo.
Implicações para Segurança, Privacidade e Prevenção de Abusos
Além dos ganhos em desempenho, as cascatas especulativas também podem contribuir para a segurança e a prevenção de abusos na IA generativa. Como o modelo maior atua como verificador, ele pode ser configurado para detectar e bloquear conteúdos inadequados, enviesados ou maliciosos gerados pelo modelo menor.

Essa camada adicional de controle é fundamental para garantir que as aplicações baseadas em IA respeitem normas éticas e protejam os usuários contra riscos relacionados a privacidade e segurança.
Desafios e Futuro das Cascatas Especulativas
Embora promissora, essa abordagem ainda enfrenta desafios, como a necessidade de balancear a complexidade do modelo verificador para não se tornar um gargalo e a adaptação para diferentes domínios de aplicação.
Entretanto, a pesquisa continua avançando, e espera-se que as cascatas especulativas se tornem uma técnica padrão para otimizar inferência em LLMs, democratizando o acesso a soluções de IA mais rápidas, econômicas e seguras.
Conclusão
As cascatas especulativas representam uma inovação significativa na área de inteligência artificial generativa, oferecendo uma solução inteligente para o dilema entre velocidade e qualidade na inferência de grandes modelos de linguagem. Ao combinar modelos menores e maiores em um processo colaborativo, essa técnica abre caminho para aplicações mais eficientes, acessíveis e confiáveis.
No cenário atual, onde a demanda por respostas rápidas e precisas cresce exponencialmente, as cascatas especulativas podem ser o diferencial que impulsiona a próxima geração de soluções em IA.
Fique ligado no blog "IA em Foco" para mais novidades e análises sobre as tendências que estão moldando o futuro da inteligência artificial!