Como Ajustar o Modelo FLUX.1-dev Usando Hardware Comum com a Técnica LoRA

Nos últimos anos, o avanço da inteligência artificial tem impulsionado a criação de modelos cada vez mais poderosos e complexos. No entanto, o treinamento e ajuste fino desses modelos geralmente exigem recursos computacionais robustos, inacessíveis para muitos desenvolvedores e entusiastas. Felizmente, técnicas inovadoras como o LoRA (Low-Rank Adaptation) estão democratizando esse processo, permitindo que modelos grandes sejam adaptados em hardware de consumo comum.
O que é o FLUX.1-dev e por que ajustá-lo?
O FLUX.1-dev é um modelo de linguagem avançado que tem ganhado destaque por sua capacidade de compreender e gerar texto com alta qualidade. Apesar de seu potencial, para aplicações específicas, é necessário realizar um ajuste fino, ou fine-tuning, para que o modelo se adapte melhor a contextos ou tarefas particulares.
Tradicionalmente, esse ajuste fino demanda GPUs de alto desempenho e muita memória, o que limita seu uso a grandes centros de pesquisa ou empresas com infraestrutura robusta. É aqui que o LoRA entra como uma solução eficiente e acessível.
Entendendo a técnica LoRA
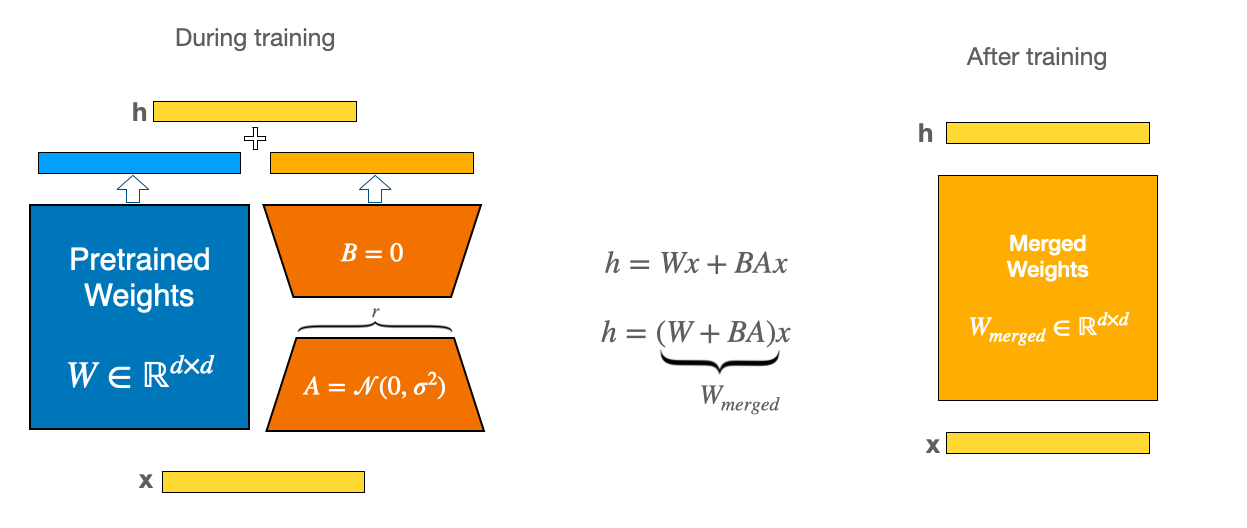
LoRA, ou Low-Rank Adaptation, é uma técnica que reduz significativamente os recursos necessários para o fine-tuning de grandes modelos. Em vez de atualizar todos os parâmetros do modelo, o LoRA propõe ajustar apenas um subconjunto deles, representados por matrizes de baixa classificação (low-rank matrices).
Essa abordagem traz diversas vantagens:
- Economia de memória: Apenas uma pequena fração dos parâmetros é atualizada, reduzindo o uso de memória.
- Velocidade: O processo de ajuste é mais rápido, pois menos cálculos são necessários.
- Facilidade de uso: Pode ser implementado em hardware comum, como GPUs de consumidores ou até mesmo em CPUs com otimizações.
Como realizar o fine-tuning do FLUX.1-dev com LoRA em hardware comum
Para ajustar o modelo FLUX.1-dev usando a técnica LoRA em um computador comum, siga os passos abaixo:
1. Preparação do ambiente
Antes de tudo, é necessário configurar o ambiente de desenvolvimento com as bibliotecas necessárias, como transformers e peft da HuggingFace, além de frameworks como PyTorch.
2. Carregamento do modelo base
O FLUX.1-dev deve ser carregado na sua versão pré-treinada. Isso pode ser feito diretamente via HuggingFace Hub, garantindo que você tenha o modelo original pronto para ser adaptado.

3. Aplicação do LoRA
Utilize a biblioteca PEFT (Parameter-Efficient Fine-Tuning) para aplicar o LoRA ao modelo. Isso envolve definir as matrizes de baixa classificação que serão treinadas, mantendo o restante do modelo congelado.
4. Preparação dos dados
Para o fine-tuning, é necessário um conjunto de dados específico para a tarefa desejada. Pode ser um corpus de texto personalizado, exemplos de perguntas e respostas, ou qualquer outro dataset relevante.
5. Treinamento
Com o modelo adaptado e os dados preparados, inicia-se o processo de treinamento. Graças ao LoRA, esse processo é viável em GPUs de consumo, como as séries NVIDIA RTX, ou até mesmo em CPUs com boa otimização.
6. Avaliação e salvamento
Após o fine-tuning, avalie o desempenho do modelo para garantir que ele atenda às expectativas. Em seguida, salve o modelo ajustado para uso futuro em aplicações específicas.
Benefícios e impactos dessa abordagem
O uso do LoRA para ajustar o FLUX.1-dev em hardware comum representa um grande avanço para democratizar o acesso à inteligência artificial de ponta. Entre os principais benefícios, destacam-se:
- Redução de custos: Não é mais necessário investir em servidores caros para realizar fine-tuning.
- Agilidade no desenvolvimento: Projetos podem ser prototipados e testados rapidamente.
- Inclusão: Pequenas empresas, startups e pesquisadores independentes podem explorar modelos avançados.
Conclusão
A técnica LoRA está revolucionando a forma como modelos grandes, como o FLUX.1-dev, são adaptados para tarefas específicas. Ao possibilitar o fine-tuning em hardware acessível, abre-se um novo horizonte para o desenvolvimento de soluções baseadas em inteligência artificial.
Para quem deseja explorar IA avançada sem depender de infraestrutura robusta, investir tempo em aprender e aplicar LoRA é um passo estratégico. Assim, o futuro da IA fica mais inclusivo, colaborativo e inovador.