Como Organizar a Memória de Agentes em Escala com Padrões de Namespace no AgentCore Memory da AWS
Desafios na Organização da Memória de Agentes de IA
Ao construir agentes de inteligência artificial que mantêm contexto entre sessões, os desenvolvedores enfrentam dificuldades para organizar a memória de forma eficiente. Sem uma estrutura adequada, a recuperação de contexto pode se tornar irrelevante e até gerar vulnerabilidades de segurança. Para que agentes baseados em Amazon Bedrock AgentCore Memory sejam eficazes, é necessário mais do que apenas armazenar dados: é essencial que a memória seja organizada, facilmente recuperável e protegida.
Namespaces: O Pilar da Organização e Segurança da Memória
Namespaces são caminhos hierárquicos que organizam os registros de memória de longo prazo dentro de um recurso AgentCore Memory. Funcionam de forma semelhante a diretórios em um sistema de arquivos, oferecendo uma estrutura lógica para armazenar dados, possibilitando a recuperação segmentada e facilitando o controle de acesso.
Por exemplo, as preferências de um usuário podem ser armazenadas em /actor/customer-123/preferences/, enquanto resumos de sessões específicas ficam em /actor/customer-123/session/session-789/summary/. Essa hierarquia permite que registros sejam recuperados exatamente no nível de granularidade desejado, seja por sessão, usuário ou grupos maiores.
Projetando Hierarquias de Namespace para Diferentes Estratégias de Memória
Cada estratégia de memória tem necessidades específicas de escopo e acesso, e o design do namespace deve refletir isso. A seguir, os principais padrões recomendados:
1. Memória Semântica e Preferências de Usuário
- Escopo: Por ator (usuário), consolidando fatos e preferências que persistem entre sessões.
- Exemplos de namespaces:
/actor/{actorId}/facts/para fatos semânticos/actor/{actorId}/preferences/para preferências do usuário
- Essa organização permite que informações acumuladas ao longo do tempo sejam facilmente recuperadas e consolidadas.
Em casos onde é necessário acessar informações agregadas de múltiplos usuários, pode-se inverter a hierarquia, colocando o tipo de memória no topo e o ator como filho, por exemplo, /customer-issues/{actorId}/. Assim, é possível consultar problemas comuns entre clientes sem perder a organização individual.
2. Memória de Resumo
- Escopo: Por sessão, já que os resumos capturam a narrativa e decisões específicas de uma interação.
- Exemplo de namespace:
/actor/{actorId}/session/{sessionId}/summary/ - Essa abordagem reduz o uso de tokens ao alimentar modelos de linguagem, ao invés de enviar todo o histórico da conversa.
3. Memória Episódica com Hierarquia de Reflexões
- Escopo: Episódios são vinculados a sessões específicas (
/actor/{actorId}/session/{sessionId}/episodes/), enquanto reflexões, que capturam aprendizados gerais, ficam em um nível superior (/actor/{actorId}/). - Esse modelo permite armazenar rastros completos de raciocínio, incluindo metas, passos e resultados, e ainda extrair insights que atravessam múltiplos episódios.
APIs para Recuperação de Memória e Padrões de Consulta
O AgentCore Memory oferece três APIs principais para recuperar dados, cada uma adequada a diferentes cenários:
- RetrieveMemoryRecords: Pesquisa semântica para encontrar memórias relevantes a uma consulta. Pode usar consultas diretas do usuário ou gerar consultas otimizadas via LLM.
- ListMemoryRecords: Lista memórias em um namespace específico, útil para exibir preferências ou realizar auditorias.
- GetMemoryRecord e DeleteMemoryRecord: Permitem acesso direto e remoção de registros específicos, facilitando a gestão da memória via interface do usuário.
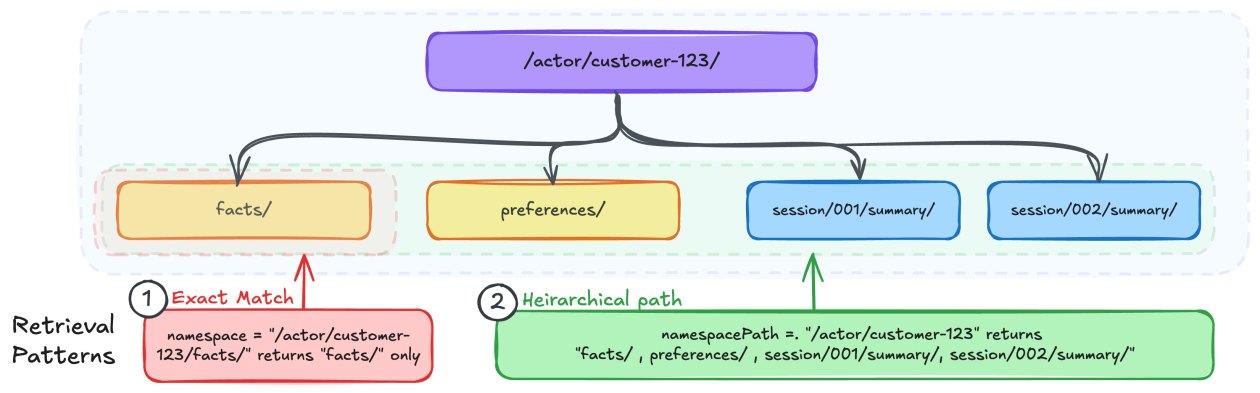
Namespace vs. NamespacePath: Entendendo o Escopo de Consulta
É fundamental distinguir entre os campos usados para escopo nas consultas:
- namespace: faz correspondência exata, retornando registros apenas do caminho especificado.
- namespacePath: realiza correspondência hierárquica, retornando registros de todos os subcaminhos dentro do especificado.
Por exemplo, consultar namespace="/actor/customer-123/facts/" traz apenas fatos daquele cliente, enquanto namespacePath="/actor/customer-123/" recupera fatos, preferências, resumos e outros dados daquele ator.
Controle de Acesso com Políticas IAM Baseadas em Namespace
Namespaces integram-se ao AWS Identity and Access Management (IAM) para controlar quem pode acessar quais memórias. Isso é realizado por meio de condições específicas nas políticas:
- Políticas de correspondência exata: usam
StringEqualscom a condiçãobedrock-agentcore:namespacepara restringir o acesso a um namespace específico, garantindo que usuários acessem apenas suas próprias memórias. - Políticas de correspondência hierárquica: usam
StringLikecombedrock-agentcore:namespacePathpara permitir acesso a todos os subcaminhos de um namespace, útil para acessos mais amplos dentro da hierarquia.
Exemplo de política para acesso restrito ao namespace de preferências de um usuário:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock-agentcore:RetrieveMemoryRecords",
"bedrock-agentcore:ListMemoryRecords"
],
"Resource": "arn:aws:bedrock-agentcore:us-east-1:123456789012:memory/mem-12345abcdef",
"Condition": {
"StringEquals": {
"bedrock-agentcore:namespace": "/actor/${aws:PrincipalTag/userId}/preferences/"
}
}
}
]
}
Conclusão e Recursos Complementares
Projetar namespaces adequados é essencial para garantir que agentes de IA construídos com Amazon Bedrock AgentCore Memory tenham uma memória eficiente, segura e escalável. A estrutura hierárquica facilita a recuperação segmentada e o controle de acesso, enquanto as APIs e políticas IAM permitem flexibilidade e segurança no gerenciamento dos dados de memória.
Para aprofundamento e exemplos práticos, consulte os links abaixo.