Como otimizar o desempenho de grandes modelos de linguagem para múltiplas requisições simultâneas

Com o crescimento exponencial do uso de grandes modelos de linguagem (LLMs) em aplicações diversas, a demanda por respostas rápidas e eficientes para múltiplas requisições simultâneas se tornou um desafio crítico. Empresas e desenvolvedores buscam constantemente maneiras de maximizar o desempenho desses modelos, garantindo que a experiência do usuário seja fluida mesmo sob alta carga.
Entendendo o desafio das requisições concorrentes em LLMs
Os grandes modelos de linguagem, como os baseados em arquiteturas Transformer, são poderosos, porém computacionalmente intensivos. Quando múltiplos usuários ou processos solicitam respostas ao mesmo tempo, o sistema precisa gerenciar essas requisições de forma eficiente para evitar gargalos e atrasos.

Tradicionalmente, cada requisição é processada de forma isolada, o que pode levar a um uso ineficiente dos recursos e a um aumento do tempo de resposta. Para lidar com isso, técnicas de otimização específicas são necessárias.
Prefill e Decode: duas etapas essenciais no processamento de LLMs
O processamento de uma requisição em um LLM geralmente envolve duas fases principais:
- Prefill: é a etapa em que o modelo processa o texto de entrada para construir um contexto interno, preparando-se para gerar a resposta.
- Decode: é o momento em que o modelo gera token a token a saída, ou seja, produz a resposta final.
Essas duas fases são cruciais, mas também podem ser pontos de ineficiência quando múltiplas requisições são feitas simultaneamente.
Otimizando a performance com processamento concorrente
A proposta para otimizar o desempenho de LLMs diante de requisições concorrentes envolve a separação e o gerenciamento eficiente das fases de prefill e decode. A ideia central é processar o prefill de múltiplas requisições em lote, aproveitando a similaridade dos contextos e reduzindo o custo computacional.
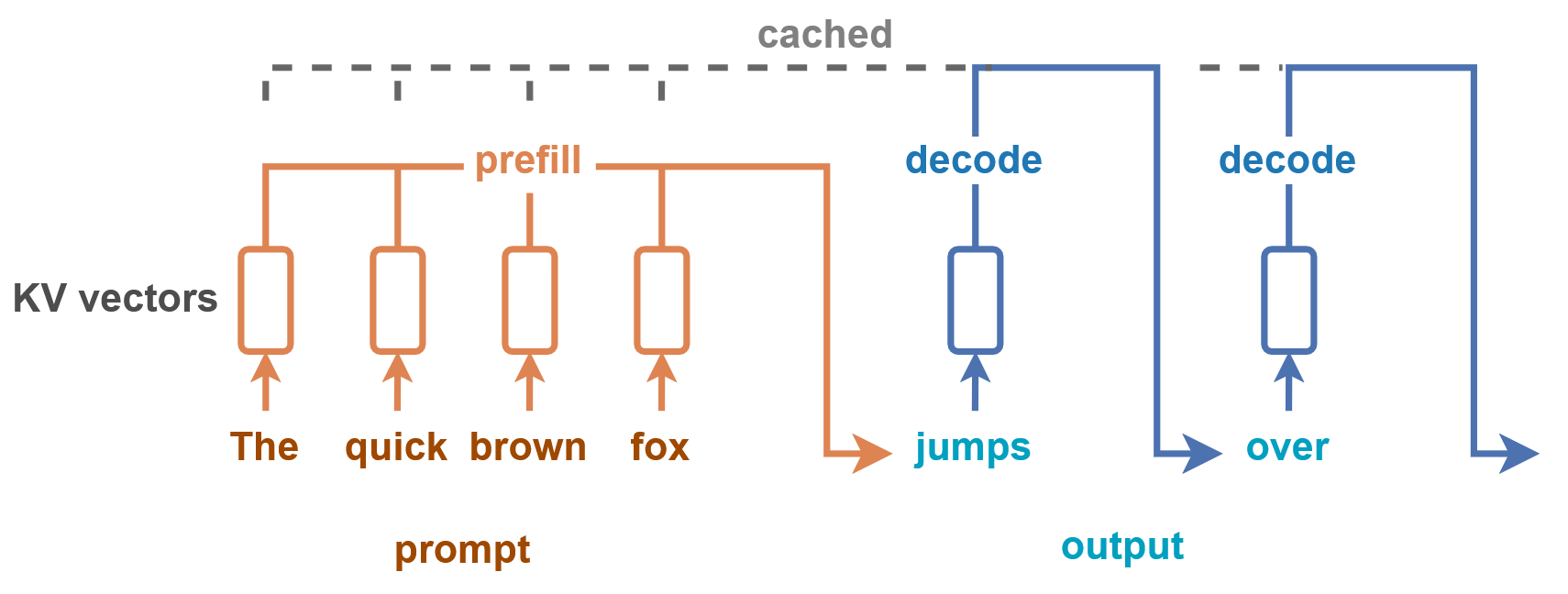
Já a etapa de decode, que é mais dinâmica e depende da geração token a token, pode ser gerenciada de forma assíncrona, permitindo que múltiplas respostas sejam geradas em paralelo sem bloqueios.
Benefícios dessa abordagem
- Redução do tempo de latência: ao agrupar o prefill, o modelo evita processar repetidamente partes semelhantes de contexto para diferentes requisições.
- Melhor utilização dos recursos: o processamento em lote maximiza o uso da GPU ou CPU, evitando ociosidade.
- Escalabilidade: permite que sistemas atendam a um maior número de usuários simultâneos sem degradação significativa na performance.
Implementação prática: o que considerar?
Para implementar essa otimização, é importante considerar:
- Gerenciamento de filas: organizar as requisições para que possam ser agrupadas eficientemente na etapa de prefill.
- Sincronização assíncrona: garantir que a etapa de decode possa ocorrer paralelamente, sem bloqueios entre as requisições.
- Balanceamento de carga: distribuir o processamento para evitar sobrecarga em determinados momentos.
- Monitoramento e métricas: acompanhar o desempenho para ajustar os parâmetros de batch e concorrência.
Conclusão
À medida que a inteligência artificial se torna cada vez mais presente em nossas vidas, a eficiência no processamento de grandes modelos de linguagem é fundamental para garantir experiências rápidas e satisfatórias. A técnica de separar e otimizar as fases de prefill e decode para requisições concorrentes representa um avanço importante nesse sentido.
Com essa abordagem, é possível atender a múltiplos usuários simultaneamente, utilizando melhor os recursos computacionais e reduzindo a latência das respostas. Para desenvolvedores e empresas que trabalham com LLMs, investir em estratégias de otimização como essa é essencial para se manter competitivo e oferecer serviços de alta qualidade.