Como Prompts Longos Impactam a Performance de Modelos de Linguagem e Como Otimizá-los

Nos últimos anos, os modelos de linguagem de grande porte (LLMs) têm revolucionado a forma como interagimos com a inteligência artificial. Seja para geração de texto, tradução automática ou assistentes virtuais, esses modelos são capazes de compreender e produzir conteúdos complexos. No entanto, à medida que os prompts — as instruções ou textos de entrada fornecidos ao modelo — se tornam mais longos, surgem desafios que impactam diretamente a performance e a capacidade de resposta desses sistemas.
Entendendo o impacto dos prompts longos
Um prompt longo pode parecer vantajoso, pois oferece mais contexto para o modelo, potencialmente gerando respostas mais precisas e relevantes. Contudo, essa extensão traz algumas consequências negativas:

- Bloqueio de outras requisições: Quando um modelo está processando um prompt extenso, ele pode ficar ocupado por um tempo maior, impedindo que outras solicitações sejam atendidas simultaneamente.
- Aumento do tempo de resposta: Quanto maior o prompt, mais recursos computacionais são necessários, o que pode elevar a latência e prejudicar a experiência do usuário.
- Limitações técnicas: Muitos LLMs têm um limite máximo de tokens que podem processar por vez. Prompts muito longos podem ultrapassar essa capacidade, forçando truncamentos ou cortes que comprometem a qualidade da resposta.
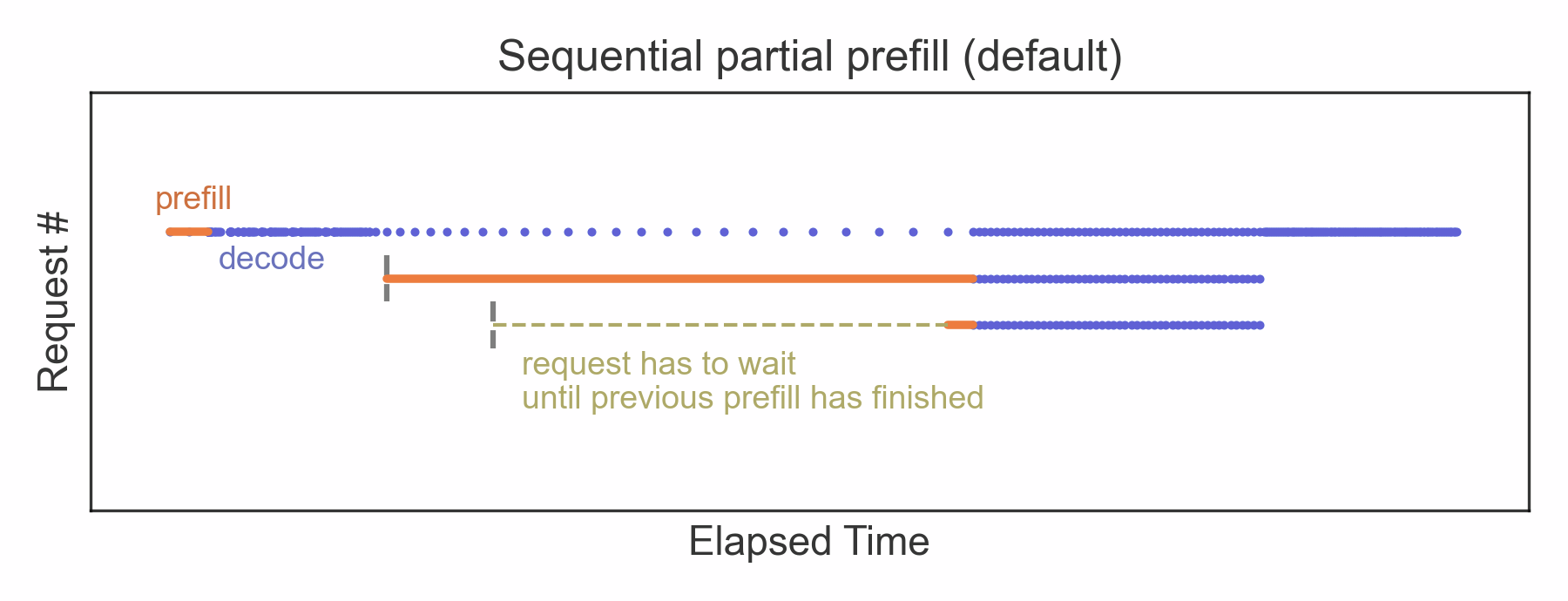
Por que os prompts longos bloqueiam outras requisições?
Os LLMs geralmente funcionam em ambientes onde o processamento é sequencial e baseado em lotes. Quando um prompt extenso é enviado, o modelo precisa analisar e gerar a resposta para todo o conteúdo antes de liberar o processamento para a próxima requisição. Isso significa que, durante esse período, outras solicitações ficam em espera, criando um gargalo.
Além disso, a infraestrutura que suporta esses modelos pode ter limitações de paralelismo e memória, o que agrava o problema. Em sistemas com alta demanda, esse bloqueio pode resultar em atrasos significativos e até falhas no atendimento.
Estratégias para otimizar a performance ao lidar com prompts longos
Felizmente, existem abordagens que podem minimizar os impactos negativos dos prompts extensos e melhorar a eficiência dos LLMs:
1. Divisão inteligente do prompt
Em vez de enviar um único prompt muito longo, divida o conteúdo em partes menores e processáveis. Isso permite que o modelo responda a cada segmento rapidamente, liberando recursos para outras requisições.
2. Resumo prévio do contexto
Utilize técnicas de sumarização para condensar o contexto antes de enviá-lo ao modelo. Um resumo bem elaborado mantém as informações essenciais e reduz o tamanho do prompt.
3. Cache de respostas
Para prompts que se repetem ou têm similaridades, implementar um sistema de cache pode evitar o processamento redundante, acelerando o tempo de resposta.
4. Ajuste do limite de tokens
Configure o modelo para limitar o número máximo de tokens processados, evitando que prompts muito longos causem sobrecarga ou truncamento inesperado.
5. Uso de modelos especializados
Em alguns casos, modelos menores e mais rápidos podem ser usados para tarefas preliminares, deixando os LLMs maiores para demandas que realmente necessitam de alta complexidade.
Benefícios da otimização para usuários e desenvolvedores
Ao implementar essas estratégias, tanto usuários finais quanto desenvolvedores se beneficiam:
- Melhor experiência do usuário: Respostas mais rápidas e precisas aumentam a satisfação e a confiança na tecnologia.
- Maior escalabilidade: Sistemas otimizados conseguem atender a um número maior de requisições simultâneas sem perda de qualidade.
- Redução de custos: Processamentos mais eficientes demandam menos recursos computacionais, o que pode resultar em economia financeira.
Conclusão
Embora prompts longos possam parecer uma forma natural de fornecer mais contexto para os modelos de linguagem, eles apresentam desafios significativos para a performance e escalabilidade dos sistemas. Compreender como esses prompts bloqueiam outras requisições e adotar estratégias inteligentes de otimização é fundamental para garantir que a inteligência artificial continue a oferecer respostas rápidas, precisas e eficientes.
Na evolução constante dos LLMs, a otimização do uso dos prompts é uma peça-chave para desbloquear todo o potencial dessas tecnologias e levar a experiência do usuário a um novo patamar.