ConvApparel: Avanços para Medir e Reduzir o Realismo em Simuladores de Usuário para IA Conversacional

Desafio dos simuladores de usuário em IA conversacional
Os agentes de inteligência artificial conversacional modernos, especialmente aqueles baseados em grandes modelos de linguagem (LLMs), conseguem realizar tarefas complexas com múltiplas interações, como fazer perguntas esclarecedoras e oferecer assistência proativa. Contudo, eles ainda enfrentam dificuldades em manter conversas longas, frequentemente esquecendo restrições ou gerando respostas irrelevantes.
Para melhorar esses sistemas, o método ideal envolve treinamento contínuo e feedback, o que tradicionalmente depende da interação com usuários humanos reais. Porém, testes com humanos são caros, demorados e de difícil escala. Por isso, a comunidade de pesquisa em IA vem adotando simuladores de usuário — agentes baseados em LLMs que atuam como usuários humanos em roleplays.
Apesar dos avanços, esses simuladores ainda apresentam um "realismo gap" (lacuna de realismo), manifestado por comportamentos atípicos como paciência excessiva, conhecimento irrealista e respostas pouco naturais. Para construir simuladores confiáveis, é essencial medir e reduzir essa lacuna.
ConvApparel: um novo conjunto de dados e framework para avaliação
O Google Research apresenta o ConvApparel, um dataset inovador com mais de 4.000 conversas humanas com agentes de IA no domínio de compras de roupas, totalizando cerca de 15.000 turnos de diálogo. O diferencial do ConvApparel está no protocolo de coleta de dados com dois agentes distintos:
- Agente "Good": projetado para ser um assistente útil e eficiente, com capacidades robustas de busca.
- Agente "Bad": intencionalmente pouco útil, confuso e com buscas degradadas, provocando frustração.
Esse setup permite capturar um amplo espectro de comportamentos humanos, desde satisfação até irritação profunda, fornecendo uma base rara para validar simuladores não apenas em aspectos superficiais, mas também em sua capacidade de adaptação.
Além disso, os participantes reportaram, a cada turno, sentimentos como satisfação, frustração e probabilidade de compra, criando um rico conjunto de anotações para validar experiências em primeira pessoa.
Framework de avaliação de simuladores: três pilares
Com o ConvApparel, os pesquisadores desenvolveram um framework de avaliação que compreende três componentes principais:
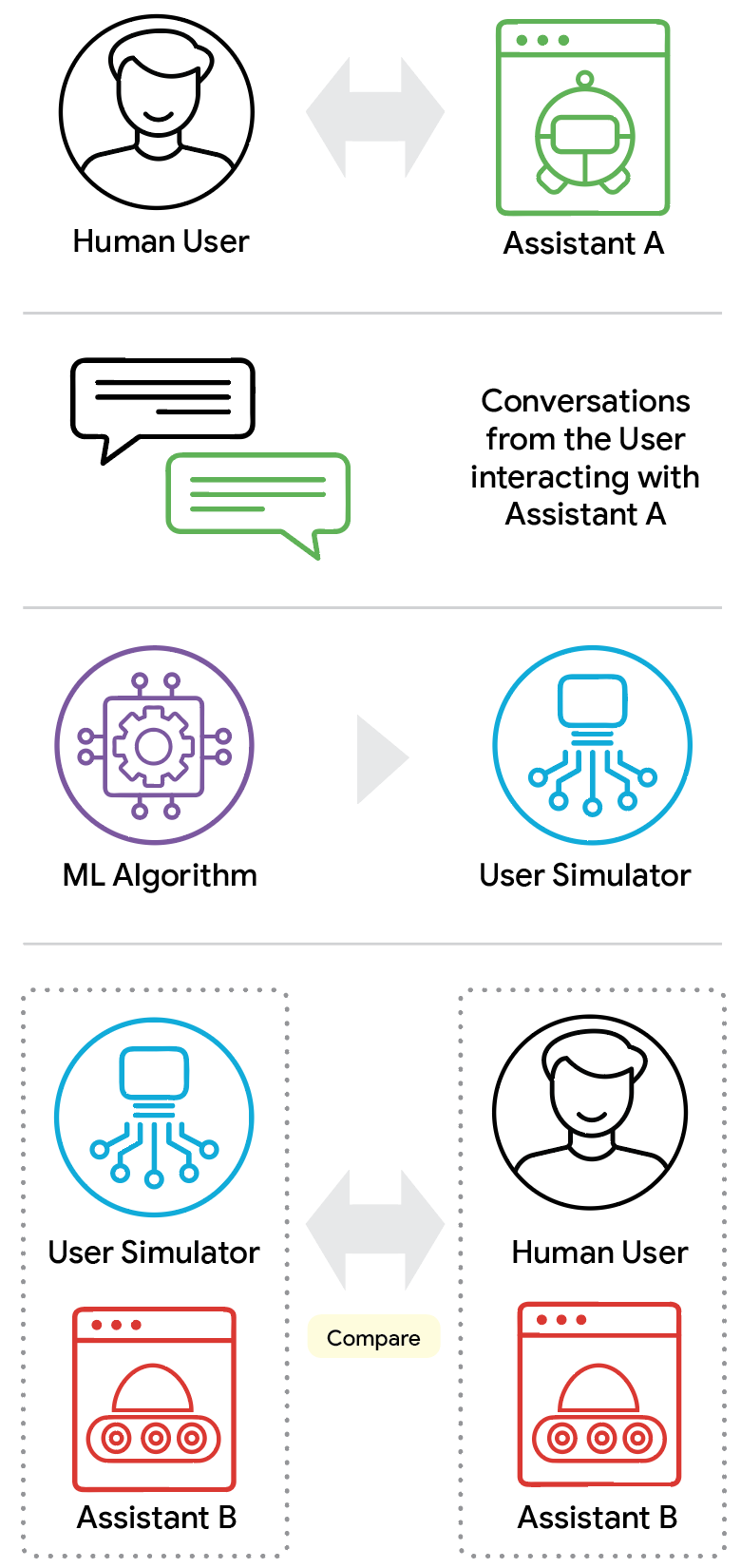
- Alinhamento estatístico populacional: compara estatísticas agregadas das conversas simuladas e humanas, como duração, palavras por turno e tipos de atos de diálogo (ex: rejeição de recomendação).
- Pontuação de similaridade humana: um discriminador automático treinado para distinguir conversas reais de simuladas gera uma pontuação indicando o quão "humana" uma conversa parece, capturando nuances estilísticas.
- Validação contrafactual: testa a capacidade do simulador de reagir a situações inesperadas, fazendo-o interagir com o agente "Bad" que não foi visto durante o treinamento. Simuladores de alta fidelidade devem exibir aumento de frustração e rejeição, assim como os humanos.
Estudo comparativo entre simuladores baseados em Gemini
Foram avaliados três tipos de simuladores baseados na família de modelos Gemini:
- Simulador baseado em prompt: usa instruções comportamentais de alto nível sem treinamento específico.
- Simulador de aprendizado em contexto (ICL): utiliza exemplos semânticos similares retirados do dataset ConvApparel durante a geração, aumentando a precisão.
- Simulador de fine-tuning supervisionado (SFT): modelo Gemini 2.5 Flash treinado diretamente com as transcrições humanas do ConvApparel para alinhar seu comportamento com o público-alvo.
Cada simulador gerou 600 conversas, divididas igualmente entre agentes "Good" e "Bad", permitindo comparação detalhada com o comportamento humano.
Principais descobertas e limitações
- Realismo detectável: o discriminador identificou quase todas as conversas simuladas como sintéticas, mesmo as de melhor qualidade apresentaram artefatos como gramática impecável e turnos previsíveis.
- Vantagem dos métodos baseados em dados: simuladores ICL e SFT alinharam-se melhor às estatísticas humanas, embora o realismo completo ainda não tenha sido alcançado.
- Robustez na validação contrafactual: enquanto o simulador baseado em prompt falhou em adaptar seu comportamento ao agente "Bad", os simuladores ICL e SFT mostraram uma adaptação realista, aumentando frustração e rejeição conforme esperado.
Esses resultados indicam que, apesar dos avanços, criar simuladores que capturem fielmente a complexidade do comportamento humano permanece um desafio aberto.
Importância prática e próximos passos
Simuladores de usuário confiáveis são fundamentais para o desenvolvimento de agentes conversacionais robustos e eficazes, especialmente em sistemas de recomendação conversacionais (CRS). Treinar agentes apenas com simuladores pouco realistas pode comprometer a performance real diante de usuários humanos.
O ConvApparel e seu framework de avaliação oferecem ferramentas para medir e reduzir a lacuna de realismo, incluindo a inovadora validação contrafactual que testa a adaptação do simulador a novas dinâmicas conversacionais.
Futuros trabalhos deverão explorar o uso desses simuladores para treinar agentes CRS do zero e avaliar seu desempenho real, fechando o ciclo de desenvolvimento e quantificando o nível de "humanidade" necessário para agentes de IA eficazes.