DeepSeek-V4: modelo com contexto de um milhão de tokens otimizado para agentes inteligentes
O Hugging Face lançou o DeepSeek-V4, uma nova geração de modelos de linguagem que suportam janelas de contexto de até um milhão de tokens, com foco especial em tarefas que envolvem agentes inteligentes e longas interações. Embora seus resultados em benchmarks tradicionais não sejam os mais altos do mercado, a inovação está na arquitetura e na eficiência para lidar com contextos extensos, um desafio crítico para aplicações que exigem raciocínio complexo e uso contínuo de ferramentas.
O problema do cache KV em agentes de longa duração
Modelos que atuam como agentes — executando múltiplas chamadas a ferramentas e mantendo o histórico de interações — enfrentam limitações técnicas relacionadas ao cache de chaves e valores (KV cache) durante a inferência. Cada token adicional aumenta o custo computacional e o uso de memória, o que torna inviável manter longos históricos.
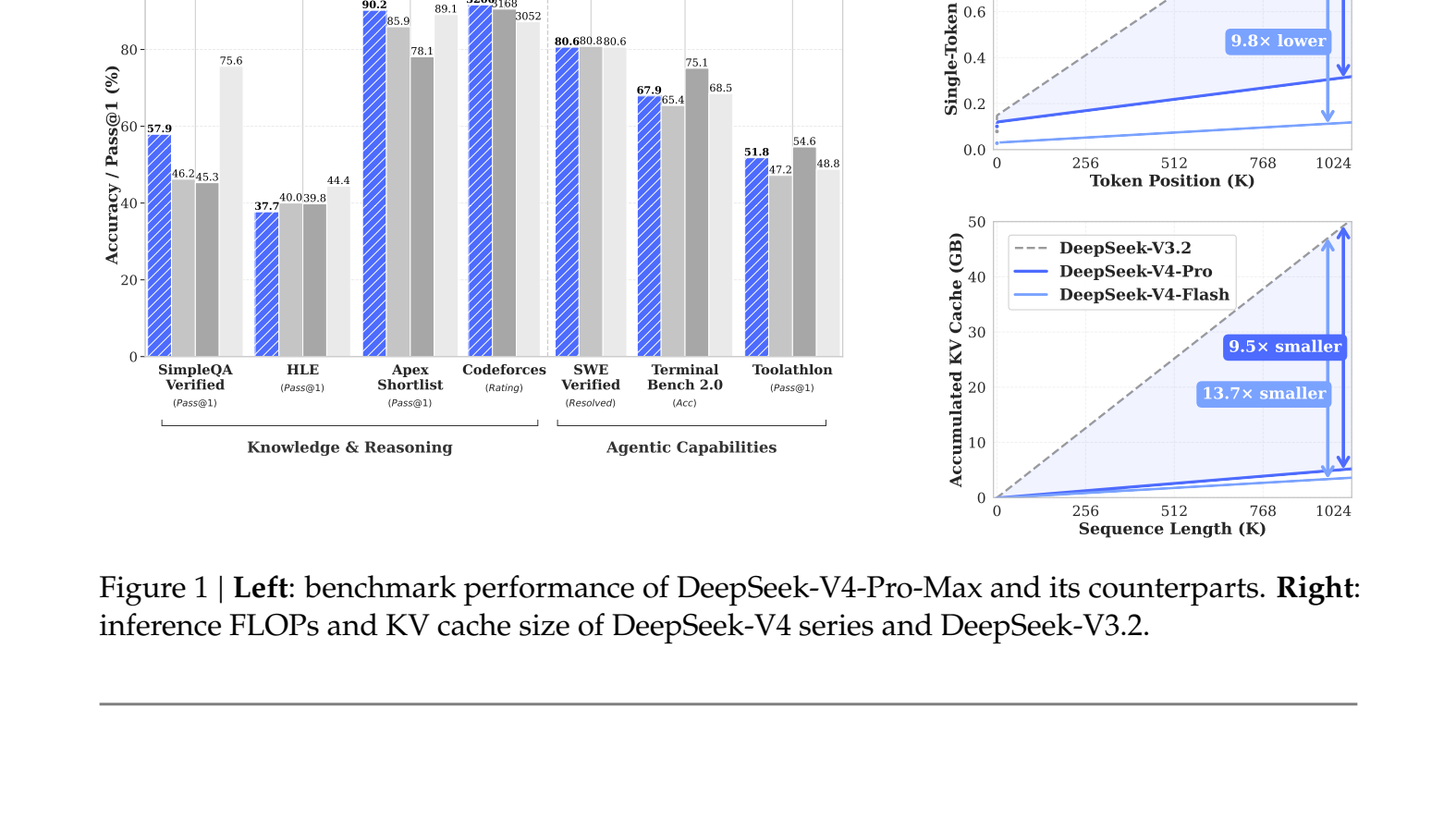
O DeepSeek-V4 resolve esse problema com uma redução significativa no uso de FLOPs (operações de ponto flutuante) e no tamanho do KV cache. Por exemplo, o modelo DeepSeek-V4-Pro usa apenas 27% dos FLOPs por token em comparação à versão anterior (V3.2) e 10% do tamanho do cache. A versão DeepSeek-V4-Flash é ainda mais eficiente, usando 10% dos FLOPs e 7% do cache, facilitando sua implantação para contextos muito longos.
Arquitetura híbrida de atenção: CSA e HCA
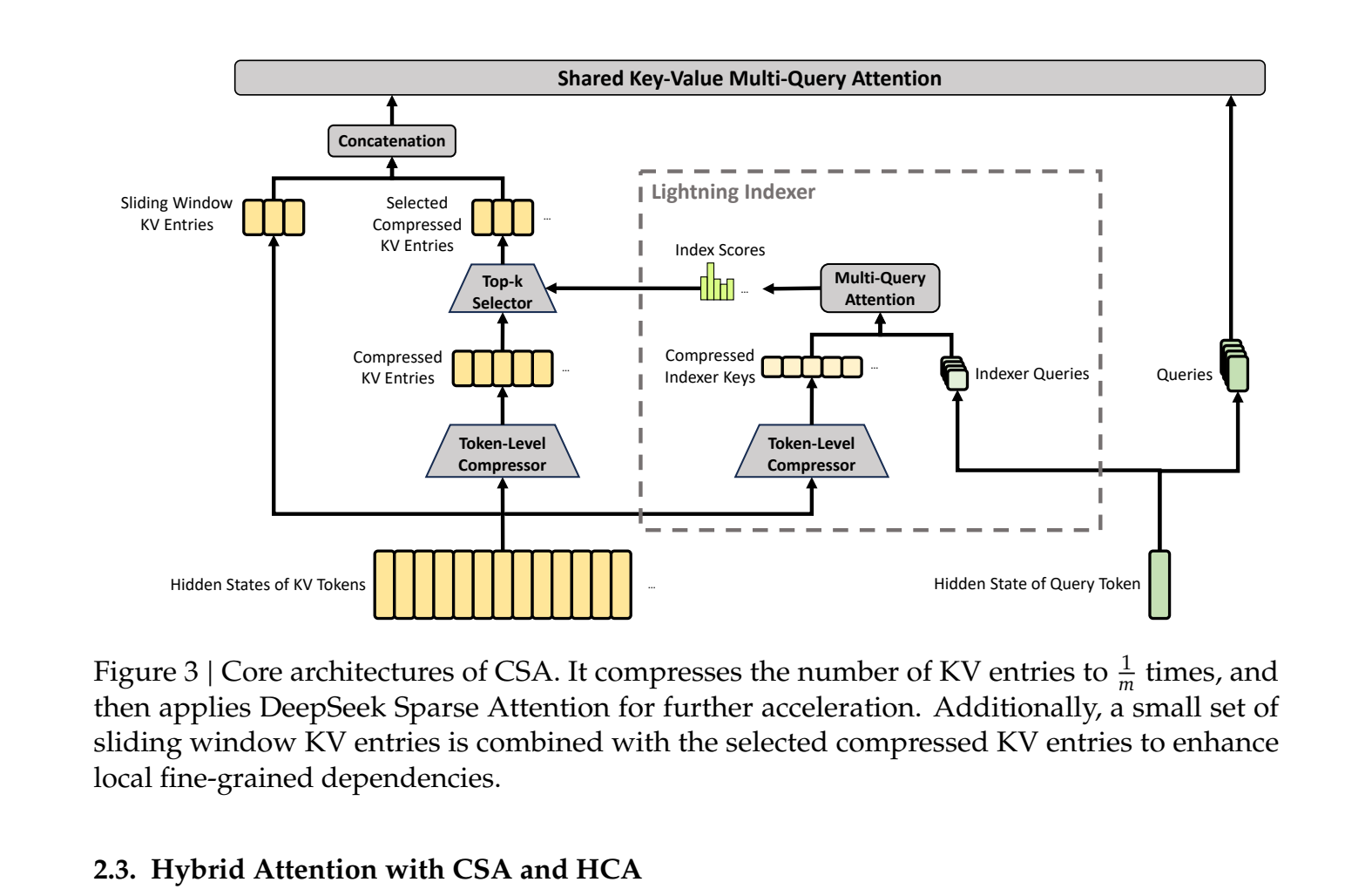
O ganho de eficiência do DeepSeek-V4 vem da combinação de dois mecanismos de atenção que se alternam nas camadas do modelo:
- Compressed Sparse Attention (CSA): comprime a sequência em blocos 4 vezes menores, selecionando de forma esparsa os blocos mais relevantes para cada consulta, reduzindo o espaço de busca e o custo computacional.
- Heavily Compressed Attention (HCA): comprime ainda mais (128 vezes) e aplica atenção densa sobre essa sequência comprimida, tornando a operação barata mesmo para sequências muito longas.
Essa alternância entre CSA e HCA, combinada com armazenamento em formatos FP4, FP8 e BF16, permite que o modelo mantenha um cache KV com apenas 2% do tamanho de arquiteturas tradicionais, viabilizando o processamento de até um milhão de tokens.
Inovações específicas para agentes inteligentes
Além da arquitetura, o DeepSeek-V4 introduz melhorias no pós-treinamento e na infraestrutura para otimizar o uso em agentes:
- Raciocínio intercalado em chamadas a ferramentas: o modelo mantém o histórico de raciocínio acumulado mesmo após múltiplas interações e chamadas a ferramentas, ao contrário da versão anterior que descartava esse histórico entre mensagens do usuário. Isso possibilita um pensamento contínuo e coerente em tarefas complexas.
- Esquema de chamadas a ferramentas com tokens dedicados: o uso do token especial
|DSML|e um formato XML para chamadas a ferramentas reduz erros de parsing comuns em formatos JSON, melhorando a robustez da comunicação entre o agente e as ferramentas externas. - DSec — sandbox para treinamento por reforço (RL): uma infraestrutura em Rust que permite executar ambientes variados (funções, containers, microVMs e VMs completas) com alta eficiência, suporte a retomada segura de treinamentos interrompidos e API unificada, acelerando o desenvolvimento e avaliação de agentes.
Desempenho em benchmarks para agentes
Nos testes voltados para agentes, o DeepSeek-V4-Pro-Max se destaca, mesmo que não tenha o melhor desempenho em benchmarks gerais de conhecimento:
- Terminal Bench 2.0: 67,9 pontos, superando GLM-5.1 (63,5) e K2.6 (66,7), ficando atrás apenas de GPT-5.4-xHigh (75,1) e Gemini-3.1-Pro (68,5).
- SWE Verified: 80,6% de tarefas resolvidas, praticamente empatado com Opus-4.6-Max (80,8) e Gemini-3.1-Pro (80,6).
- MCPAtlas Public: 73,6 pontos, segundo lugar atrás de Opus-4.6-Max (73,8).
- Toolathlon: 51,8 pontos, à frente de K2.6 (50,0), GLM-5.1 (40,7) e Gemini-3.1-Pro (48,8).
Além disso, no benchmark interno para tarefas de codificação em PyTorch, CUDA, Rust e C++, o modelo alcançou 67% de acerto, próximo ao Opus 4.5 (70%) e superior ao Sonnet 4.5 (47%). Em pesquisa com 85 desenvolvedores que usam o DeepSeek-V4-Pro diariamente, 52% consideram o modelo pronto para substituir suas ferramentas atuais.
Como usar o DeepSeek-V4
Quatro checkpoints estão disponíveis no Hugging Face Hub:
- DeepSeek-V4-Pro: 1,6 trilhões de parâmetros totais, 49 bilhões ativos, modelo instruct.
- DeepSeek-V4-Flash: 284 bilhões totais, 13 bilhões ativos, modelo instruct.
- DeepSeek-V4-Pro-Base: 1,6 trilhões de parâmetros, modelo base.
- DeepSeek-V4-Flash-Base: 284 bilhões, modelo base.
Os modelos instruct suportam três modos de raciocínio: Non-think (rápido, sem cadeia de pensamento), Think High (raciocínio explícito em blocos <think>) e Think Max (raciocínio máximo com prompt dedicado). O modo Think Max exige um contexto mínimo de 384 mil tokens.
Considerações finais e impacto prático
O DeepSeek-V4 representa um avanço importante para aplicações que demandam longas interações e raciocínio contínuo, especialmente agentes que integram múltiplas ferramentas e precisam manter histórico extenso. A arquitetura híbrida de atenção e as otimizações para cache KV tornam possível trabalhar com contextos muito maiores sem comprometer desempenho ou escalabilidade.
O suporte a um esquema robusto para chamadas a ferramentas e a infraestrutura DSec para treinamento por reforço indicam que o DeepSeek-V4 é uma plataforma madura para desenvolvimento de agentes inteligentes, com potencial para influenciar o futuro dos sistemas autônomos de IA.