Desvendando o KV Cache: Construindo do Zero no nanoVLM para IA mais Ágil

Nos últimos anos, a Inteligência Artificial (IA) tem avançado rapidamente, especialmente no campo dos modelos de linguagem. Uma das inovações que tem ganhado destaque é o uso do KV Cache (Key-Value Cache) para otimizar a geração de texto em modelos como o nanoVLM. Neste artigo, vamos explorar o que é o KV Cache, sua importância para modelos de linguagem e como sua implementação do zero pode transformar a eficiência do nanoVLM.
O que é KV Cache e por que ele importa?
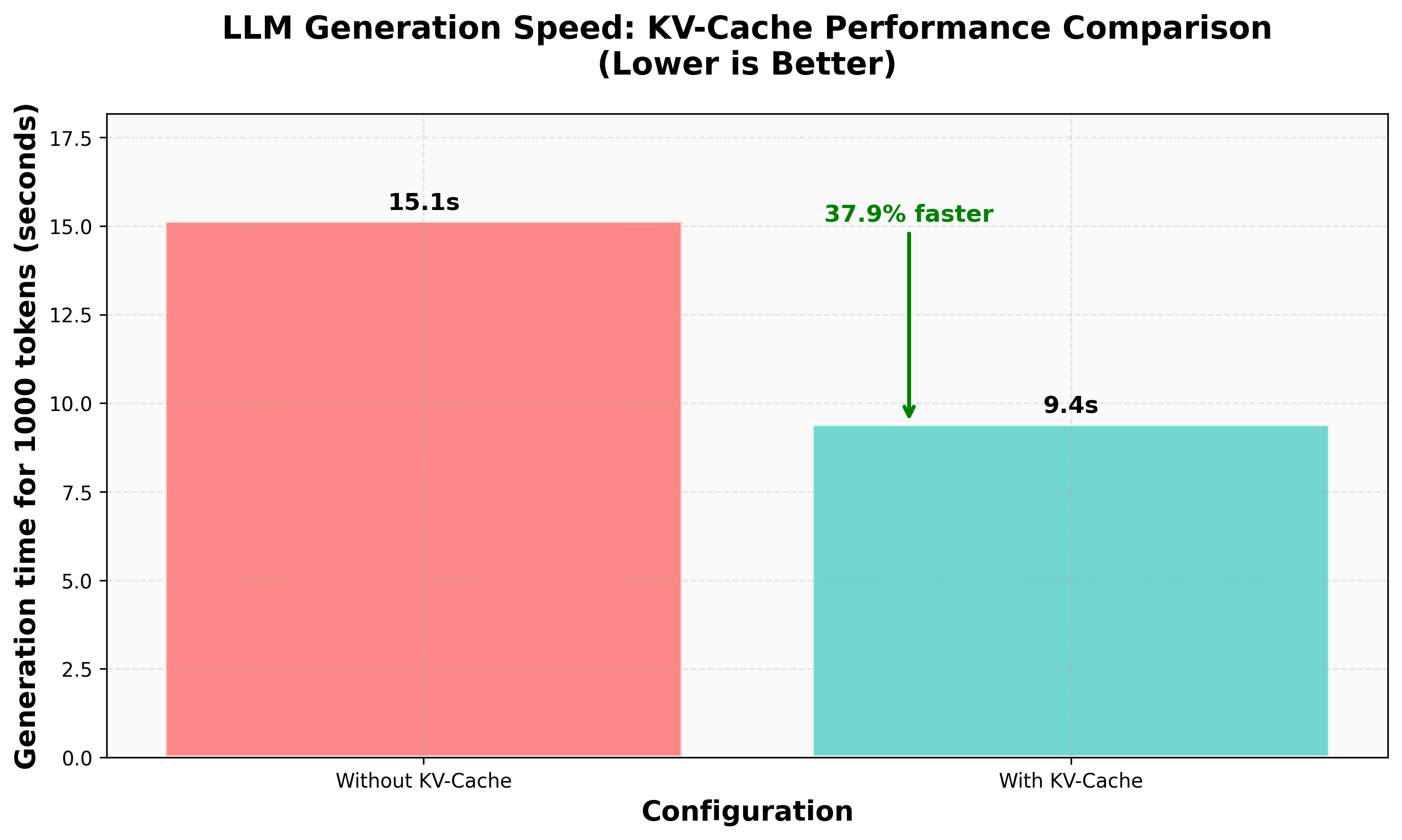
O KV Cache é uma técnica utilizada para armazenar informações intermediárias durante o processo de geração de texto em modelos de linguagem baseados em transformadores. Em vez de recalcular todas as representações internas a cada passo, o modelo armazena as chaves (keys) e valores (values) gerados anteriormente, permitindo que o processo seja muito mais rápido e eficiente.
Como funciona o KV Cache?
- Chaves (Keys): Representações que ajudam o modelo a identificar quais partes da entrada são relevantes.
- Valores (Values): Dados que carregam informações contextuais importantes para a geração da próxima palavra ou token.
- Cache: Armazena essas chaves e valores para evitar recomputações desnecessárias.
Ao reutilizar essas informações, o modelo reduz drasticamente o tempo de inferência e o consumo computacional, o que é essencial para aplicações em tempo real e dispositivos com recursos limitados.
nanoVLM: Um modelo leve com grande potencial
O nanoVLM é um modelo de linguagem visual e multimodal projetado para ser compacto e eficiente, ideal para dispositivos com capacidade computacional reduzida. Apesar de seu tamanho reduzido, ele mantém uma performance impressionante, especialmente quando otimizado com técnicas como o KV Cache.
Desafios na implementação do KV Cache no nanoVLM
Implementar o KV Cache do zero no nanoVLM não é uma tarefa trivial. É necessário compreender profundamente a arquitetura do modelo e como ele processa informações para garantir que o cache seja armazenado e acessado corretamente. Além disso, é fundamental garantir que a implementação seja eficiente para não comprometer a leveza do modelo.
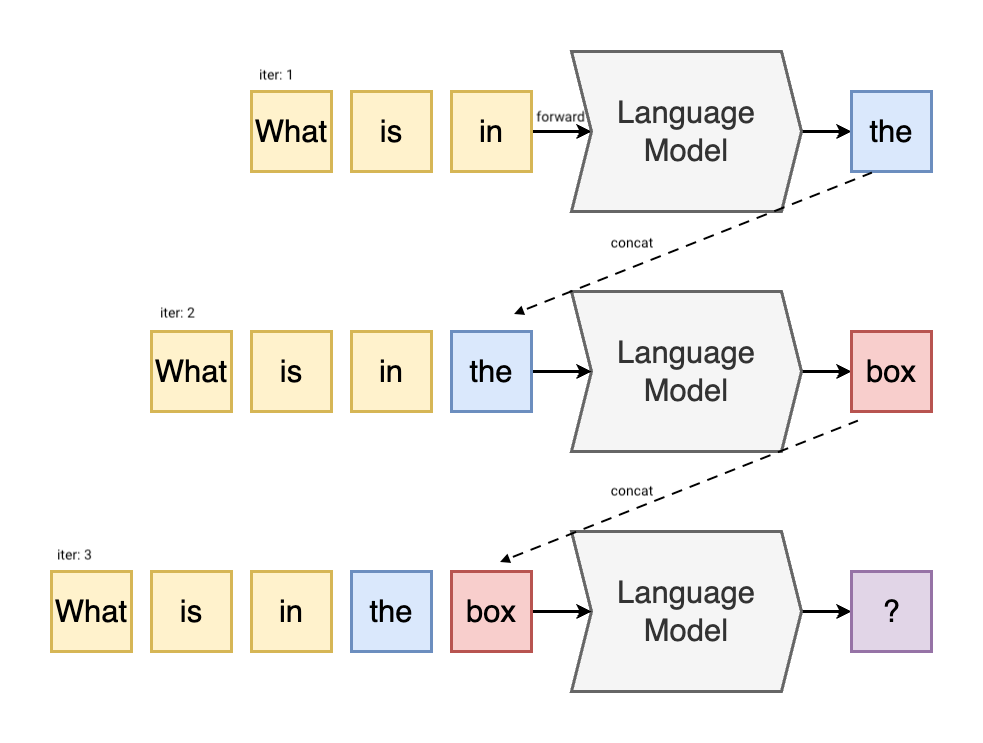
Passos para construir o KV Cache do zero no nanoVLM
A seguir, destacamos os principais passos para implementar o KV Cache no nanoVLM, baseados nas melhores práticas e insights do HuggingFace:
- Entender a arquitetura do transformador: Conhecer como as camadas de atenção funcionam e onde as chaves e valores são gerados.
- Definir estruturas de dados eficientes: Criar arrays ou tensores que armazenem as chaves e valores de forma otimizada.
- Implementar a lógica de atualização do cache: Garantir que, a cada novo token gerado, o cache seja atualizado sem perda de dados anteriores.
- Integrar o cache ao processo de inferência: Modificar a geração de texto para utilizar o cache ao invés de recalcular tudo.
- Testar e validar: Avaliar se o desempenho melhorou e se os resultados permanecem corretos.
Benefícios práticos da implementação do KV Cache no nanoVLM
Ao construir o KV Cache do zero, os desenvolvedores ganham um controle maior sobre o funcionamento interno do modelo, possibilitando:
- Redução significativa no tempo de resposta, ideal para aplicações em tempo real.
- Menor consumo de recursos computacionais, facilitando a execução em dispositivos móveis e embarcados.
- Maior flexibilidade para customizações e adaptações específicas ao projeto.
- Melhor compreensão do funcionamento interno do modelo, o que é valioso para pesquisa e desenvolvimento.
Conclusão
O KV Cache é uma peça-chave para otimizar modelos de linguagem como o nanoVLM, especialmente quando pensamos em aplicações que exigem rapidez e eficiência. Construir essa funcionalidade do zero, embora desafiador, traz inúmeros benefícios e abre portas para inovações ainda maiores no campo da IA multimodal. Para quem trabalha com modelos compactos e deseja extrair o máximo de performance, entender e implementar o KV Cache é um passo fundamental.
Se você se interessa por IA e quer ficar por dentro das últimas tendências e técnicas, continue acompanhando o IA em Foco para conteúdos exclusivos e aprofundados.