EMO: Modelo Modular Emergente que Revoluciona o Uso de Mixture-of-Experts em Grandes Linguagens

O time da AllenAI, em parceria com a Hugging Face, anunciou o lançamento do EMO, um modelo do tipo mixture-of-experts (MoE) que introduz modularidade emergente diretamente a partir dos dados, sem depender de domínios pré-definidos por humanos. Essa inovação permite que uma pequena fração dos especialistas (experts) do modelo seja ativada para uma tarefa específica, mantendo quase toda a performance do modelo completo.
O Desafio da Modularidade em Grandes Modelos de Linguagem
Modelos de linguagem convencionais são geralmente monolíticos: um único modelo é treinado, ajustado e utilizado como uma entidade única. No entanto, aplicações reais frequentemente demandam apenas um subconjunto de suas capacidades, como geração de código, raciocínio matemático ou conhecimento em áreas específicas.

Com a escalada para modelos com trilhões de parâmetros, usar o modelo inteiro para cada tarefa torna-se impraticável, onerando recursos computacionais e memória com parâmetros que podem não ser necessários.
Modelos MoE oferecem uma solução natural: em vez de um grande bloco feedforward em cada camada, eles possuem múltiplas redes menores chamadas experts, ativando apenas um pequeno subconjunto para cada token de entrada. Na teoria, isso permitiria carregar apenas os experts relevantes para uma tarefa, economizando recursos.
Na prática, porém, MoEs tradicionais ativam experts baseados em padrões superficiais, como preposições ou pontuações, e não em domínios semânticos, o que faz com que quase todos os experts sejam usados para qualquer entrada, inviabilizando o uso seletivo.
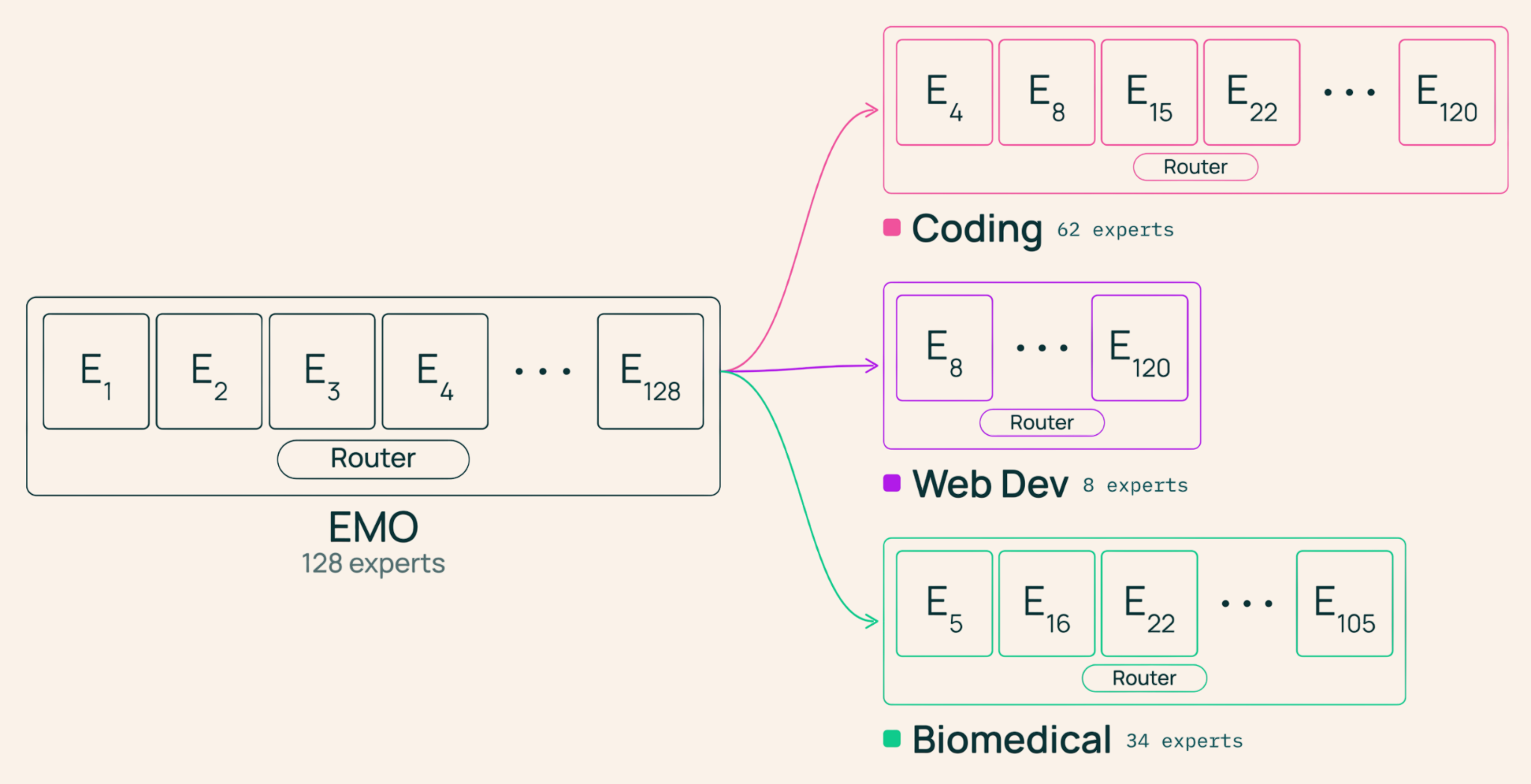
Como o EMO Promove a Modularidade Emergente
Ao contrário de abordagens anteriores que exigem rotas baseadas em domínios pré-definidos (como matemática, biologia ou código), o EMO permite que a modularidade emerja diretamente dos dados. A chave está no uso das fronteiras de documento como sinal fraco para supervisionar o roteamento dos tokens aos experts.
Durante o treinamento, todos os tokens de um mesmo documento são restritos a escolher seus experts dentro de um subconjunto compartilhado, definido automaticamente pelo roteador do modelo. Essa restrição incentiva que grupos coerentes de experts se especializem em domínios semânticos, pois tokens do mesmo documento tendem a pertencer a um mesmo domínio.
Para evitar que o modelo colapse em poucos experts, o EMO aplica balanceamento de carga globalmente, garantindo que diferentes documentos distribuam o uso dos experts e que a modularidade seja mantida sem perda de diversidade.
Além disso, o tamanho do pool de experts para cada documento é aleatoriamente amostrado durante o treinamento, o que permite flexibilidade e suporte a diferentes tamanhos de subconjuntos de experts na inferência.
Resultados e Benefícios Práticos do EMO
O EMO foi treinado com 14 bilhões de parâmetros no total, dos quais 1 bilhão estão ativos em cada inferência (8 experts ativos entre 128 totais), utilizando um dataset de 1 trilhão de tokens.
Nos benchmarks gerais, o EMO iguala o desempenho de um MoE padrão sem modularidade, mostrando que o objetivo de modularidade não compromete a performance total.
Mais importante, quando se utiliza apenas um subconjunto dos experts para uma tarefa específica (por exemplo, 12,5% dos experts), o EMO mantém uma queda de performance muito pequena, cerca de 3% em média, enquanto MoEs tradicionais apresentam degradação severa, chegando a resultados próximos ao acaso.
A seleção dos melhores experts para uma tarefa é simples e eficiente, podendo ser feita com poucos exemplos de validação, o que facilita a adaptação rápida do modelo a novos domínios.
Especialização dos Experts e Interpretação
Análises das ativações do roteador mostram que os experts do EMO se agrupam em domínios semânticos claros, como Saúde, Política, Música e Notícias, ao contrário de MoEs tradicionais que agrupam tokens por características superficiais, como preposições ou artigos definidos.
Isso significa que cada subconjunto de experts funciona como um módulo com capacidade real e específica, permitindo composições flexíveis e interpretáveis.
Uma visualização interativa das clusters de tokens está disponível para exploração pública, facilitando a compreensão do comportamento modular do EMO.
O Que Está Disponível para a Comunidade
- Modelos EMO treinados: coleção no Hugging Face
- Relatório técnico detalhado: paper oficial
- Código-fonte para treinamento: repositório no GitHub
- Visualização interativa: explore os clusters de experts
Esses recursos oferecem uma base sólida para pesquisadores e desenvolvedores explorarem modularidade emergente em MoEs, abrindo caminho para modelos mais eficientes, adaptáveis e interpretáveis.
Desafios e Próximos Passos
Embora o EMO represente um avanço significativo, ainda há desafios a serem superados, como:
- Melhorar a seleção e composição automática de subconjuntos de experts;
- Atualizar módulos específicos sem afetar o modelo completo;
- Desenvolver maior interpretabilidade e controle baseados na estrutura modular.
O lançamento do EMO contribui para que a comunidade possa avançar nesses pontos, tornando os grandes modelos de linguagem mais práticos e customizáveis para diferentes aplicações.
Links úteis
Leia também

Hugging Face lança simulação econômica com cinco modelos de IA para entender mercados emergentes
8 de junho de 2026
Projeto Amazing Digital Dentures: os desafios de criar aventuras digitais com IA
8 de junho de 2026
Her: a detetive que analisa suas sessões de Claude Code com inteligência e segurança
7 de junho de 2026