FilBench: Desvendando a Capacidade dos Grandes Modelos de Linguagem em Compreender e Gerar Filipino

Nos últimos anos, os grandes modelos de linguagem (LLMs) têm revolucionado a forma como interagimos com a inteligência artificial, especialmente no processamento de idiomas. Enquanto línguas amplamente faladas como o inglês, espanhol e mandarim recebem grande atenção, idiomas com menor presença digital, como o filipino, ainda enfrentam desafios significativos. É nesse contexto que surge o FilBench, um benchmark inovador que avalia a habilidade dos LLMs em compreender e gerar textos em filipino.
O que é o FilBench?
FilBench é uma ferramenta desenvolvida para medir a proficiência dos grandes modelos de linguagem no idioma filipino, também conhecido como tagalo. Diferentemente dos benchmarks tradicionais que focam em línguas com grande volume de dados disponíveis, o FilBench foi criado para testar a capacidade dos modelos em lidar com um idioma que possui menos recursos digitais e, portanto, apresenta desafios únicos para o treinamento e avaliação de IA.

Por que o filipino é importante para IA?
- Demografia: O filipino é falado por mais de 100 milhões de pessoas, principalmente nas Filipinas, tornando-o um dos idiomas mais falados do mundo.
- Diversidade linguística: As Filipinas possuem uma rica diversidade cultural e linguística, e o filipino serve como língua franca entre diferentes grupos.
- Inclusão digital: Desenvolver IA que compreenda o filipino é um passo importante para democratizar o acesso à tecnologia e à informação para falantes desse idioma.
Desafios no Processamento do Filipino por LLMs
Apesar do avanço dos modelos de linguagem, o filipino apresenta obstáculos específicos:
- Escassez de dados: A quantidade limitada de textos digitais em filipino dificulta o treinamento eficaz dos modelos.
- Complexidade linguística: O filipino possui estruturas gramaticais e vocabulário influenciados por diversas línguas, como espanhol, inglês e línguas indígenas, o que pode confundir os modelos.
- Ambiguidade e contexto: O significado de palavras e frases pode variar muito dependendo do contexto cultural e regional.
Como o FilBench Avalia os Modelos?
O benchmark utiliza uma variedade de tarefas para testar diferentes aspectos da compreensão e geração de texto em filipino, incluindo:
- Compreensão de leitura: Avalia a capacidade do modelo de entender textos e responder perguntas relacionadas.
- Geração de texto: Testa a habilidade de criar textos coerentes e contextualmente relevantes em filipino.
- Tradução: Mede a precisão na tradução entre filipino e outras línguas, principalmente inglês.
- Análise semântica: Examina o entendimento do significado e nuances das frases.
Resultados e Impactos
Os testes realizados com o FilBench revelam que, embora os LLMs atuais consigam realizar tarefas básicas em filipino, ainda há espaço para melhorias significativas, especialmente em contextos mais complexos e culturais. Esses resultados são fundamentais para orientar pesquisadores e desenvolvedores a focar no aprimoramento dos modelos para línguas menos representadas.
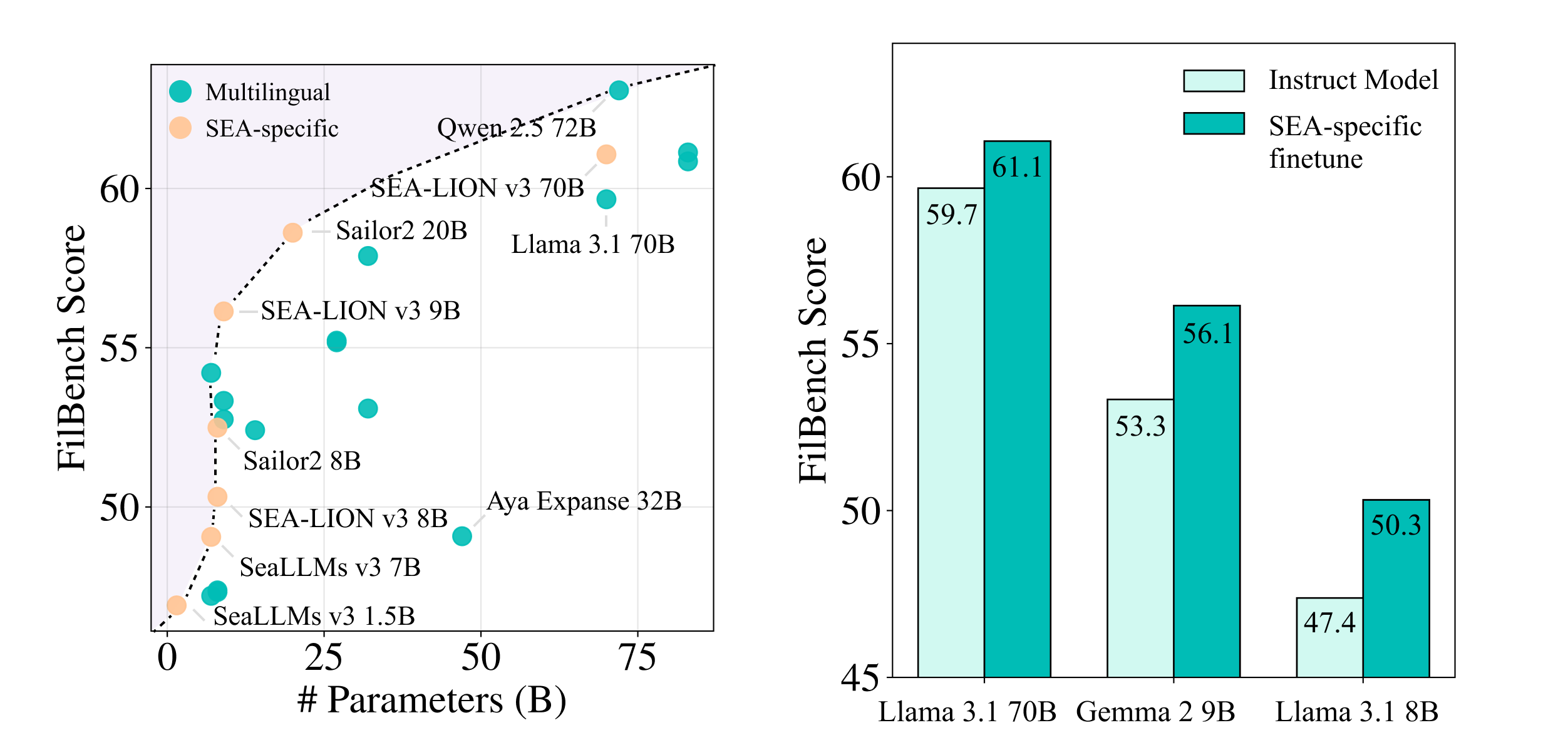
Além disso, o FilBench incentiva a criação de mais dados abertos e recursos em filipino, promovendo a inclusão digital e o desenvolvimento de tecnologias que atendam melhor às necessidades dos falantes dessa língua.
Conclusão
O FilBench representa um avanço importante na avaliação da inteligência artificial aplicada ao filipino, destacando tanto o progresso quanto os desafios atuais dos grandes modelos de linguagem. À medida que a IA se torna cada vez mais presente em nossas vidas, garantir que ela compreenda e se comunique em diversos idiomas, incluindo aqueles com menos recursos digitais, é essencial para uma tecnologia verdadeiramente inclusiva e global.
Para os entusiastas e profissionais de IA, acompanhar iniciativas como o FilBench é fundamental para entender as tendências e direcionar esforços para a construção de modelos mais robustos e culturalmente sensíveis.