Gemma 4: A Nova Fronteira da Inteligência Multimodal On-Device da Hugging Face

Apresentação do Gemma 4 e seu impacto na IA multimodal
A Hugging Face lançou a família de modelos Gemma 4, desenvolvida pela Google DeepMind, trazendo avanços significativos em inteligência multimodal embarcada (on-device). Com licenças Apache 2.0, esses modelos são abertos, altamente compatíveis com diversas bibliotecas e dispositivos, e oferecem suporte a entradas de texto, imagens, áudio e vídeo, além de geração de texto.
Arquitetura e inovações técnicas do Gemma 4
O Gemma 4 evolui a partir de versões anteriores, incorporando componentes que equilibram eficiência, compatibilidade e desempenho em contextos de longo alcance e agentes autônomos. Entre suas principais características estão:
- Per-Layer Embeddings (PLE): um esquema que cria vetores de embedding dedicados para cada camada do decodificador, permitindo especialização sem aumentar muito o custo computacional.
- Shared KV Cache: otimização que reutiliza estados de chave e valor em camadas finais, reduzindo memória e cálculo durante inferência, especialmente útil para contextos longos e uso em dispositivos locais.
- Encoder visual e de áudio: o encoder de imagens preserva proporções originais e permite diferentes orçamentos de tokens para balancear qualidade e desempenho; o encoder de áudio segue arquitetura USM-style conformer similar ao Gemma-3n.
- Suporte a contextos muito longos: até 256 mil tokens em modelos maiores, com atenção alternada entre janelas locais e atenção global.
Modelos disponíveis e capacidades multimodais
O Gemma 4 está disponível em quatro variantes, todas baseadas em fine-tuning base e por instrução:
- E2B: 2,3 bilhões de parâmetros efetivos (5,1B com embeddings), janela de contexto de 128k tokens, suporte a áudio.
- E4B: 4,5 bilhões efetivos (8B com embeddings), 128k tokens, suporte a áudio.
- 31B: modelo denso com 31 bilhões de parâmetros, 256k tokens de contexto.
- 26B: modelo MoE (mixture-of-experts) com 26 bilhões totais e 4 bilhões ativos, 256k tokens.
Esses modelos são capazes de processar imagens, texto e vídeo (com áudio nos menores) de forma integrada. Em testes informais, o desempenho multimodal se mostrou comparável ao da geração de texto, com alta qualidade.
Principais funcionalidades multimodais testadas
Detecção de objetos e apontamento em interfaces
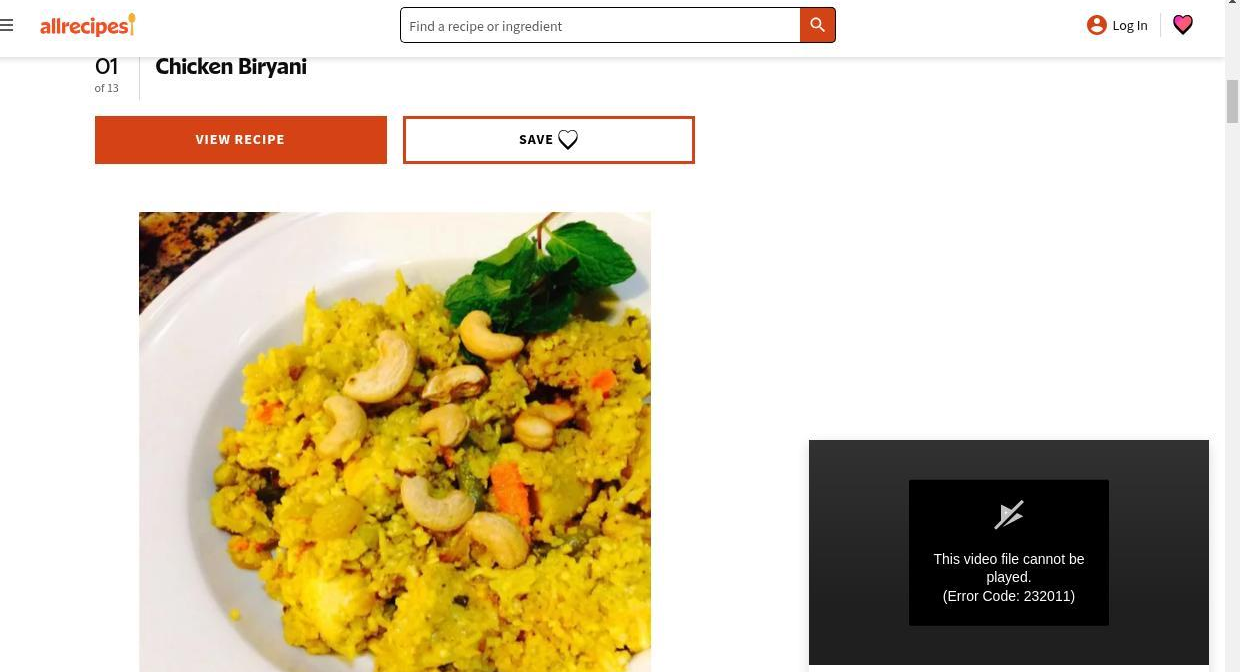
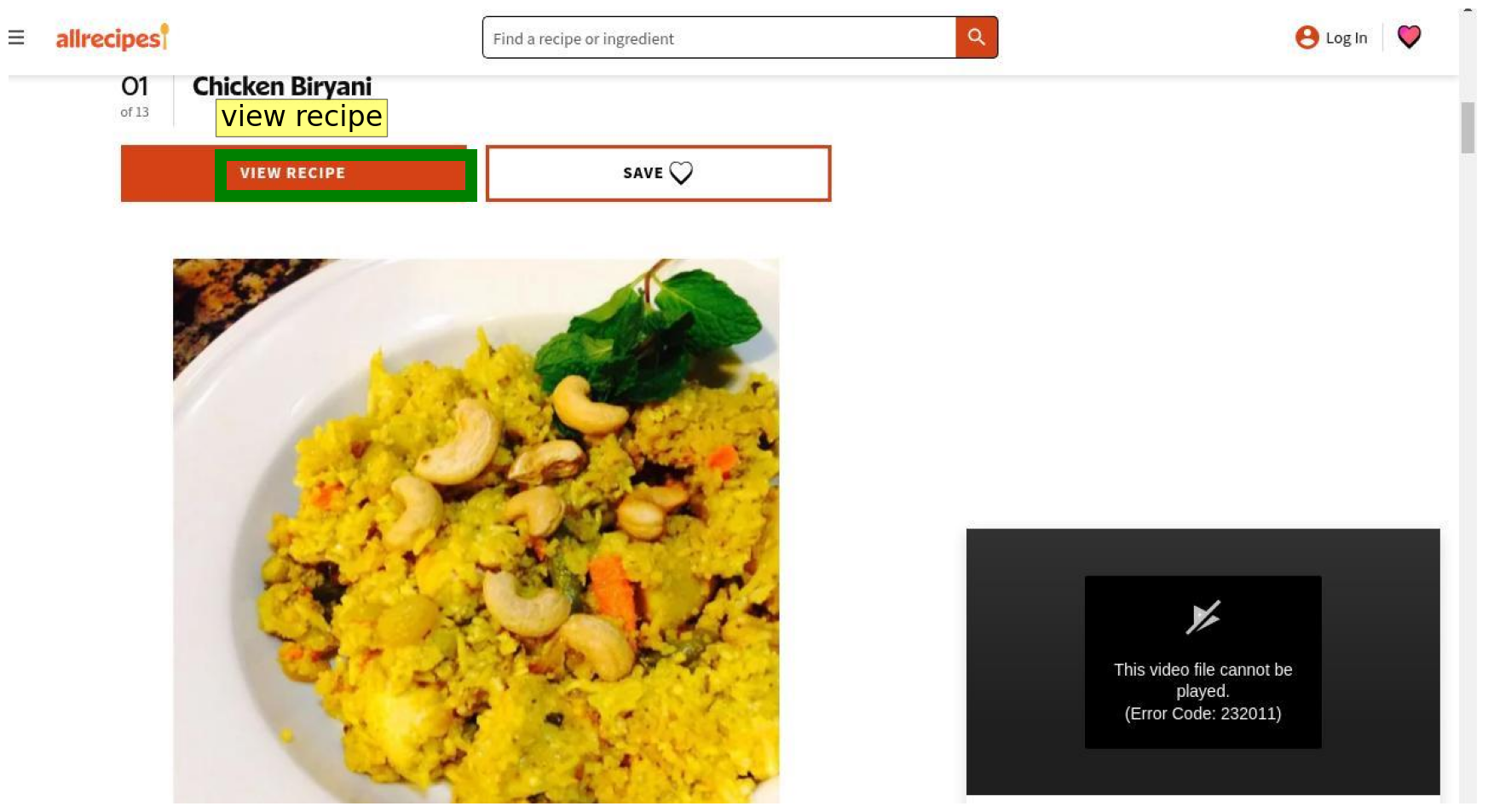
O Gemma 4 pode identificar elementos em interfaces gráficas (GUI), respondendo nativamente em JSON com as coordenadas de caixas delimitadoras. Por exemplo, ao solicitar a caixa delimitadora do botão “view recipe”, o modelo retorna as coordenadas relativas à imagem, facilitando a integração em sistemas automatizados.
Reconhecimento e descrição de objetos em imagens
Testes com imagens do cotidiano, como bicicletas, mostram que o modelo consegue identificar objetos e retornar coordenadas precisas, com variações de detalhamento conforme o tamanho do modelo.
Raciocínio multimodal e geração de código
O Gemma 4 é capaz de interpretar imagens e gerar código HTML para reconstrução de páginas web, produzindo até 4000 tokens para garantir fidelidade ao layout original. Isso demonstra capacidade avançada de "pensamento multimodal" e execução de tarefas complexas.
Compreensão e descrição de vídeos com áudio
Os modelos menores aceitam vídeos com áudio, analisando o conteúdo visual e auditivo para responder perguntas sobre a cena e a letra da música, mesmo sem treinamento explícito em vídeos. Modelos maiores processam vídeo sem áudio, descrevendo com riqueza de detalhes apresentações musicais ao vivo, iluminação, público e atmosfera.
Legenda automática de imagens
Todos os checkpoints do Gemma 4 geram legendas detalhadas e precisas para imagens complexas, descrevendo cenários urbanos e naturais com nuances, como uma gaivota em uma praça europeia, destacando elementos arquitetônicos e ambientais.
Integração e fine-tuning facilitados
O Gemma 4 foi projetado para ser integrado com múltiplas ferramentas e bibliotecas populares, como MLX, mistral.rs, transformers, llama.cpp, transformers.js, entre outras. Essa flexibilidade permite rodar os modelos localmente, em dispositivos móveis e na nuvem.
Para quem deseja adaptar o modelo a necessidades específicas, há suporte a fine-tuning com TRL, incluindo exemplos práticos para o Google Vertex AI e Unsloth Studio, facilitando personalizações e melhorias de desempenho.
Como experimentar o Gemma 4
A Hugging Face disponibiliza notebooks e scripts para testar o Gemma 4, incluindo:
- Notebook multimodal Gemma 4 (E2B)
- Script de inferência
- Exemplo de fine-tuning no Vertex AI
- Demos interativas
O lançamento do Gemma 4 representa um avanço notável na inteligência artificial multimodal para dispositivos locais, combinando alta performance, flexibilidade e abertura. Com suporte a áudio, vídeo, imagens e texto, e compatibilidade ampla, ele abre novas possibilidades para aplicações em assistentes pessoais, automação, análise multimídia e muito mais.