Granite 4.1: Os Bastidores da Construção dos Novos Modelos de Linguagem da IBM

Conheça o Granite 4.1: uma família de LLMs densos e eficientes
O Granite 4.1 é a mais recente geração de modelos de linguagem de grande porte (LLMs) desenvolvidos pela IBM, disponibilizados em código aberto pela Hugging Face sob a licença Apache 2.0. Com versões de 3 bilhões, 8 bilhões e 30 bilhões de parâmetros, esses modelos foram treinados desde o zero em aproximadamente 15 trilhões de tokens, por meio de um pipeline de pré-treinamento em cinco fases, incluindo uma extensão inédita para contextos longos de até 512 mil tokens.
Arquitetura técnica e inovações
Os modelos Granite 4.1 adotam uma arquitetura Transformer do tipo decoder-only, densa, com componentes avançados como Grouped Query Attention (GQA), Rotary Position Embeddings (RoPE), ativações SwiGLU e RMSNorm. A arquitetura compartilha embeddings de entrada e saída e varia em dimensão conforme o tamanho do modelo:

- 3B: 40 camadas, embedding size 2560, 40 cabeças de atenção
- 8B: 40 camadas, embedding size 4096, 32 cabeças de atenção
- 30B: 64 camadas, embedding size 4096, 32 cabeças de atenção
Pipeline de pré-treinamento em cinco fases
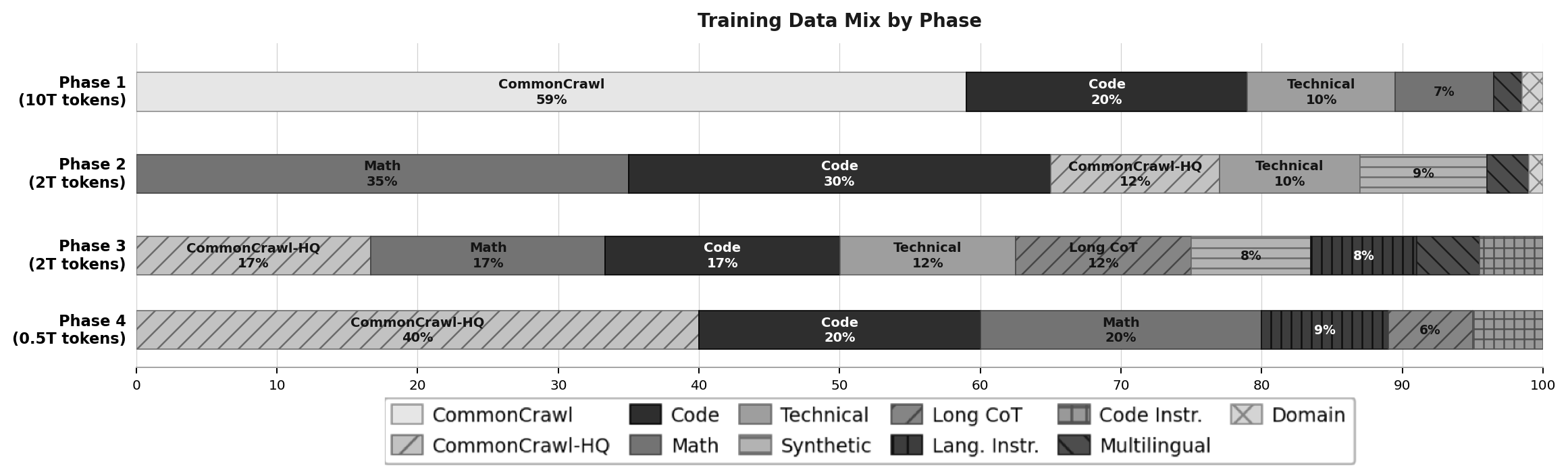
O treinamento do Granite 4.1 é dividido em cinco etapas, cada uma com foco em diferentes tipos de dados e estratégias de aprendizado:
- Fase 1 - Pré-treinamento geral (10 trilhões de tokens): Uso de dados amplos da web (CommonCrawl), código, matemática, conteúdos técnicos e multilíngues para estabelecer uma base robusta.
- Fase 2 - Pré-treinamento focado em matemática e código (2 trilhões de tokens): Aumenta significativamente a proporção de dados de código e matemática para fortalecer o raciocínio.
- Fase 3 - Annealing com dados de alta qualidade (2 trilhões de tokens): Introdução gradual de dados sintéticos, cadeias de raciocínio (chain-of-thought) e instruções para melhorar a qualidade e o comportamento do modelo.
- Fase 4 - Refinamento com dados de alta qualidade (0,5 trilhão de tokens): Foco em dados ainda mais curados para maximizar a precisão e confiabilidade.
- Fase 5 - Treinamento para contexto longo (Long Context Extension - LCE): Extensão progressiva da janela de contexto de 4 mil para 512 mil tokens, permitindo que o modelo lide com documentos e interações muito extensas.
Supervisão rigorosa e aprendizado por reforço
Após o pré-treinamento, os modelos passam por uma fase de fine-tuning supervisionado (SFT) com cerca de 4,1 milhões de amostras altamente curadas. Para garantir a qualidade, foi implementado um sistema de avaliação automática chamado "LLM-as-Judge", que verifica respostas segundo critérios semânticos, estruturais e comportamentais, eliminando amostras com erros ou alucinações.
Em seguida, um pipeline multiestágio de aprendizado por reforço (RL) é aplicado para aprimorar capacidades específicas, como matemática, código, instrução e chat geral. Esse processo usa algoritmos avançados como On-policy GRPO com perda DAPO, garantindo estabilidade e desempenho superior.
Desempenho e benchmarks
Os modelos Granite 4.1 apresentam resultados competitivos em benchmarks de linguagem geral, matemática, programação e tarefas multilíngues. O modelo de 8 bilhões de parâmetros, por exemplo, iguala ou supera o Granite 4.0-H-Small, que possui 32 bilhões de parâmetros e arquitetura Mixture-of-Experts (MoE), apesar de ser mais simples e eficiente.
Alguns destaques nos benchmarks incluem:
- Desempenho de até 94,16 no GSM8K (matemática) para o modelo de 30B.
- Alta precisão em tarefas de programação, como HumanEval, com pass@1 acima de 89% no modelo 30B.
- Capacidade de seguir instruções e realizar diálogos complexos, demonstrada em avaliações como AlpacaEval e IFEval.
- Suporte a múltiplos idiomas, incluindo português, inglês, alemão, espanhol, francês, japonês, árabe, entre outros.
Implicações práticas e disponibilidade
Com foco em eficiência, confiabilidade e custo operacional reduzido, o Granite 4.1 é indicado para aplicações empresariais que demandam modelos de linguagem robustos e escaláveis, capazes de trabalhar com contextos extremamente longos e diversos domínios. A arquitetura densa simplifica a implementação e manutenção em produção.
Os modelos, documentação completa e recursos comunitários estão disponíveis gratuitamente para desenvolvedores e empresas através do repositório no GitHub e da plataforma Hugging Face:
- Repositório GitHub Granite 4.1
- Documentação oficial Granite
- Blog oficial Hugging Face sobre Granite 4.1
- Cadastro na Hugging Face