Hugging Face lança recursos para treinar e ajustar modelos multimodais com Sentence Transformers
A Hugging Face anunciou uma novidade importante para desenvolvedores e pesquisadores que trabalham com modelos multimodais: a possibilidade de treinar e ajustar finamente modelos de embedding e reranking multimodais usando a biblioteca Sentence Transformers. Essa funcionalidade amplia o uso dos modelos para aplicações que combinam texto, imagens, áudio e vídeo, como busca semântica multimodal e recuperação visual de documentos.
O que foi lançado?
A novidade permite que usuários treinem ou façam fine-tuning de modelos multimodais, como o Qwen/Qwen3-VL-Embedding-2B, otimizando-os para tarefas específicas, por exemplo, Visual Document Retrieval (VDR). Essa tarefa consiste em recuperar páginas de documentos (imagens contendo gráficos, tabelas e layouts) relevantes para uma consulta de texto, o que exige que o modelo entenda diferentes modalidades e estruturas complexas.
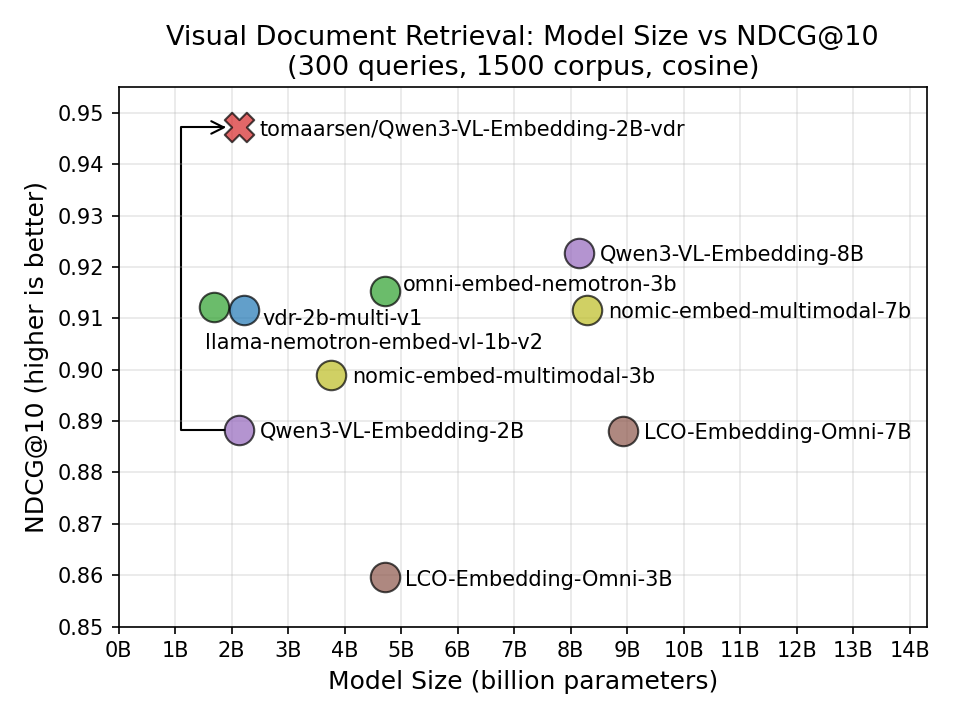
Um exemplo prático apresentado no blog da Hugging Face mostra um modelo finamente ajustado para VDR que alcançou NDCG@10 de 0.947, superando o modelo base (0.888) e outros modelos multimodais maiores, evidenciando o ganho de performance ao treinar com dados específicos do domínio.
Quem pode usar e para que serve?
Essa funcionalidade é indicada para desenvolvedores, cientistas de dados e pesquisadores que trabalham com:
- Recuperação de informações multimodais, como buscas que combinam texto e imagens.
- Geração aumentada por recuperação (retrieval augmented generation).
- Entendimento e análise de documentos visuais complexos.
- Qualquer aplicação que exija embeddings alinhados entre diferentes modalidades (texto, imagem, áudio, vídeo).
Além disso, o sistema suporta a criação de modelos multimodais compostos, combinando encoders especializados para cada tipo de dado, usando o módulo Router, o que possibilita arquiteturas flexíveis e otimizadas para diferentes cenários.
Como acessar e usar
O treinamento e fine-tuning multimodal são feitos com a biblioteca Sentence Transformers, que oferece uma API em Python para carregar modelos, preparar datasets e configurar o processo de treinamento.
Exemplo de carregamento de um modelo multimodal com parâmetros de pré-processamento e configuração do modelo:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"Qwen/Qwen3-VL-Embedding-2B",
model_kwargs={"attn_implementation": "flash_attention_2", "torch_dtype": "bfloat16"},
processor_kwargs={"min_pixels": 28*28, "max_pixels": 600*600}
)Para treinamento, a Hugging Face recomenda o uso da classe SentenceTransformerTrainer, que integra modelo, dataset, função de perda e argumentos de treinamento. A função de perda CachedMultipleNegativesRankingLoss é indicada para tarefas de recuperação, combinando negativos difíceis e negativos em lote para um sinal de treinamento mais forte.
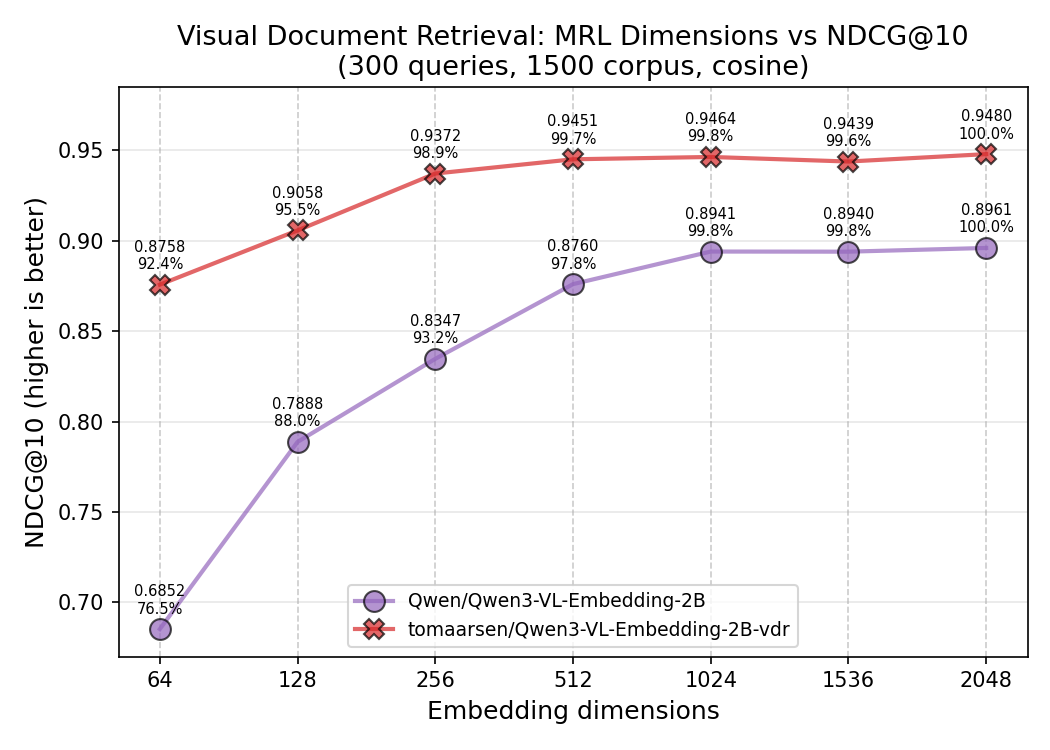
Além disso, o MatryoshkaLoss permite treinar embeddings que funcionam bem em múltiplas dimensões, possibilitando truncamento eficiente para diferentes necessidades de desempenho e memória.
Dados e avaliação
Como dataset de exemplo para treinamento, foi utilizado o tomaarsen/llamaindex-vdr-en-train-preprocessed, uma versão pré-processada do conjunto llamaindex/vdr-multilingual-train com cerca de 53 mil amostras em inglês, contendo consultas de texto, imagens de documentos e negativos difíceis.
Para avaliação, é usada a classe InformationRetrievalEvaluator, que calcula métricas padrão como NDCG@10, MAP e Recall@k, permitindo monitorar o desempenho durante o treinamento.
Impacto prático para o leitor
Com essa novidade, profissionais que precisam de soluções de busca e análise multimodal podem obter modelos mais precisos e adaptados ao seu domínio, sem depender exclusivamente de modelos genéricos. O fine-tuning em dados específicos melhora a capacidade de entender documentos complexos, imagens e consultas em conjunto, ampliando as possibilidades de aplicações comerciais e acadêmicas.
Além disso, o suporte a múltiplas modalidades e a flexibilidade na composição de encoders facilitam a criação de soluções customizadas, equilibrando custo computacional e qualidade.
Disponibilidade e preço
O recurso está disponível na biblioteca Sentence Transformers no GitHub e pode ser usado gratuitamente em ambientes próprios. Para quem utiliza a plataforma Hugging Face, o treinamento pode ser feito em seus Spaces ou Buckets, sujeitos às políticas de uso e preços da plataforma.