HuggingFace Revoluciona a Geração de Texto com Suporte a Múltiplos Backends: TRT-LLM e vLLM

A evolução da inteligência artificial tem impulsionado avanços significativos na geração de texto automatizada. Recentemente, a HuggingFace, uma das principais plataformas de IA, anunciou uma novidade que promete transformar o desempenho e a flexibilidade dos modelos de geração de texto: o suporte a múltiplos backends, incluindo TRT-LLM e vLLM, para sua ferramenta Text Generation Inference.
O que é Text Generation Inference?
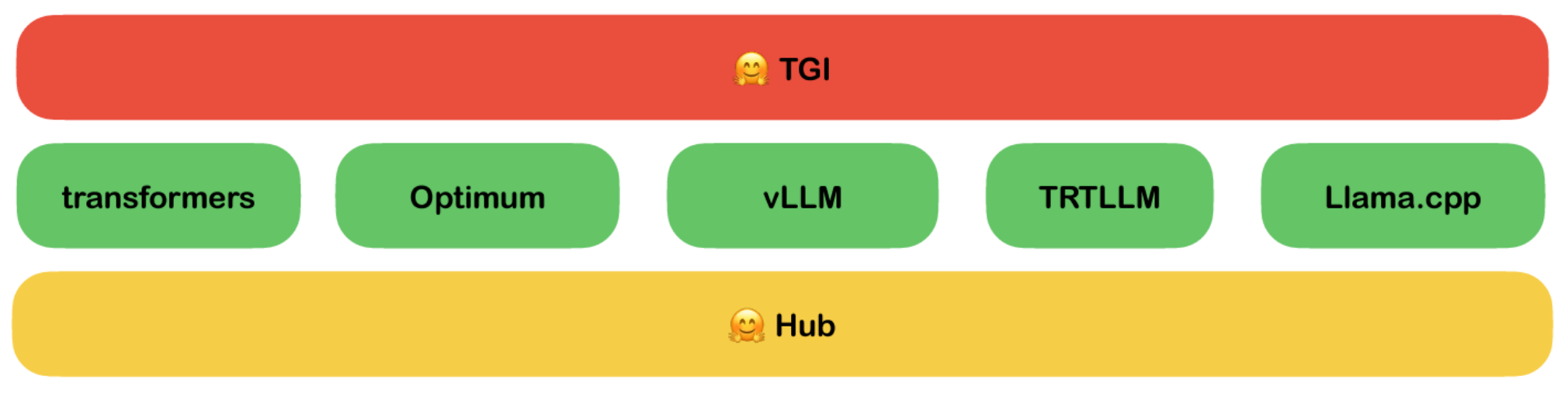
Antes de explorarmos as novidades, é importante entender o que é o Text Generation Inference (TGI). Trata-se de uma ferramenta desenvolvida pela HuggingFace que permite a execução eficiente de modelos de linguagem para geração de texto. Seu objetivo é oferecer respostas rápidas e precisas, facilitando a integração de modelos de IA em aplicações reais, desde chatbots até assistentes virtuais.
Por que o suporte a múltiplos backends é um divisor de águas?
Tradicionalmente, a execução de modelos de linguagem grandes (LLMs) dependia de um backend específico, o que limitava a flexibilidade e a otimização do desempenho. Com a introdução do suporte a múltiplos backends, a HuggingFace permite que desenvolvedores e pesquisadores escolham a melhor infraestrutura para suas necessidades, aproveitando as vantagens de cada tecnologia.
Conheça os backends TRT-LLM e vLLM
- TRT-LLM: Baseado na plataforma TensorRT da NVIDIA, o TRT-LLM é otimizado para acelerar a inferência de modelos de linguagem em GPUs, garantindo alta velocidade e eficiência energética.
- vLLM: Um backend focado em escalabilidade e baixa latência, ideal para aplicações que exigem respostas rápidas e processamento em larga escala.
Benefícios práticos do suporte multi-backend
A integração desses backends no Text Generation Inference traz diversas vantagens:
- Flexibilidade: Escolha do backend mais adequado conforme o caso de uso, hardware disponível e requisitos de desempenho.
- Performance otimizada: Aproveitamento máximo dos recursos de hardware, seja em GPUs NVIDIA com TensorRT ou em ambientes que demandam alta escalabilidade com vLLM.
- Redução de custos: Melhor uso da infraestrutura pode significar economia significativa em ambientes de produção.
- Facilidade de integração: A HuggingFace mantém uma interface unificada, simplificando a troca entre backends sem necessidade de grandes adaptações no código.
Impacto para desenvolvedores e empresas
Para desenvolvedores, essa novidade significa mais liberdade para experimentar e otimizar suas aplicações de geração de texto. Empresas que dependem de IA para atendimento ao cliente, criação de conteúdo ou análise de dados podem agora escalar suas soluções com maior eficiência e menor latência, melhorando a experiência do usuário final.

Exemplos de aplicação
- Chatbots inteligentes que respondem em tempo real, mesmo sob alta demanda.
- Ferramentas de criação de conteúdo automatizado com respostas mais rápidas e precisas.
- Assistentes virtuais corporativos que integram múltiplas fontes de dados e oferecem respostas contextualizadas.
Como começar a usar o suporte multi-backend?
A HuggingFace disponibiliza documentação detalhada e exemplos para que desenvolvedores possam implementar o Text Generation Inference com TRT-LLM e vLLM. A comunidade ativa também contribui com tutoriais, dicas e suporte, facilitando a adoção dessas tecnologias.
Conclusão
A inclusão do suporte a múltiplos backends no Text Generation Inference da HuggingFace representa um avanço significativo na área de geração de texto por IA. Ao combinar a potência do TRT-LLM e a escalabilidade do vLLM, a plataforma oferece uma solução robusta, flexível e eficiente para uma ampla gama de aplicações. Essa inovação não apenas melhora a performance técnica, mas também abre novas possibilidades para desenvolvedores e empresas que desejam explorar o potencial da inteligência artificial de forma mais estratégica e econômica.
Fique atento às atualizações da HuggingFace e aproveite essa nova era na geração de texto automatizada!