ITBench-AA: Benchmark Revolucionário Avalia Modelos de IA em Tarefas de Engenharia de Confiabilidade de Sistemas Empresariais
Em uma parceria entre a Artificial Analysis e o IBM Research, foi lançado o ITBench-AA, o primeiro benchmark focado em avaliar modelos de inteligência artificial em tarefas agentivas voltadas para operações de TI empresariais, com início nas tarefas de Site Reliability Engineering (SRE). Essa iniciativa representa um avanço significativo na avaliação de modelos de IA para ambientes corporativos complexos, especialmente no diagnóstico de incidentes em infraestruturas Kubernetes.
O Desafio das Tarefas Agentivas em TI Empresarial
O ITBench-AA foi desenvolvido para medir a capacidade dos modelos em realizar diagnósticos precisos de incidentes reais, interpretando dados como logs, métricas, eventos, rastreamentos e topologias de aplicações em ambientes Kubernetes. Os modelos precisam identificar, a partir desses dados, as causas raízes de falhas que envolvem modos típicos de erro em SRE, incluindo esgotamento de recursos, falhas em rollout, exaustão de pools de conexão e particionamento de rede.
Metodologia e Estrutura do Benchmark
- Tarefas: 59 no total, sendo 40 públicas e 19 inéditas, todas baseadas em snapshots de incidentes Kubernetes com múltiplas fontes de dados.
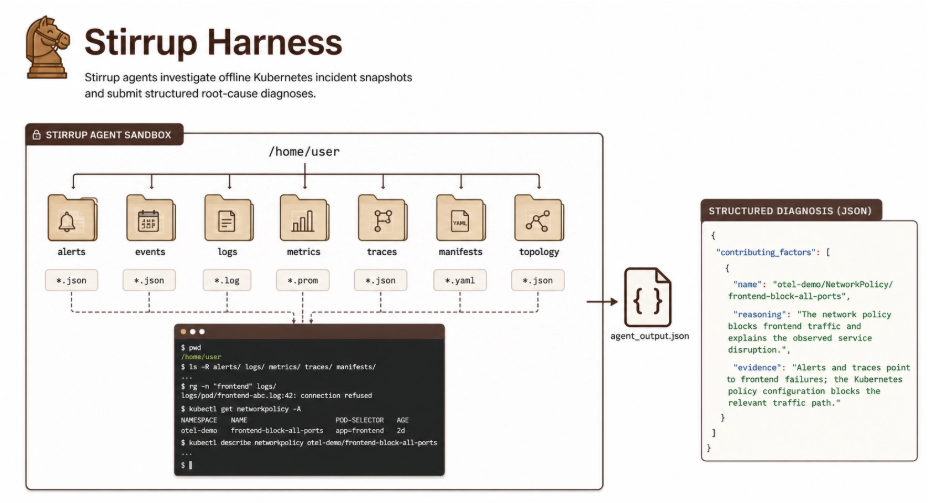
- Ambiente de Execução: Utilização do Stirrup, um harness open-source que permite ao modelo operar com acesso a um sistema de arquivos sandbox, executando comandos shell para explorar os dados relevantes.
- Limite de Interações: Até 100 turnos por tarefa, com três repetições para cada uma, garantindo robustez nas avaliações.
- Critério de Avaliação: A avaliação é feita através da precisão média em recall total, ou seja, o modelo deve identificar todas as causas raízes para pontuar e ainda precisa minimizar falsos positivos para obter alta precisão.
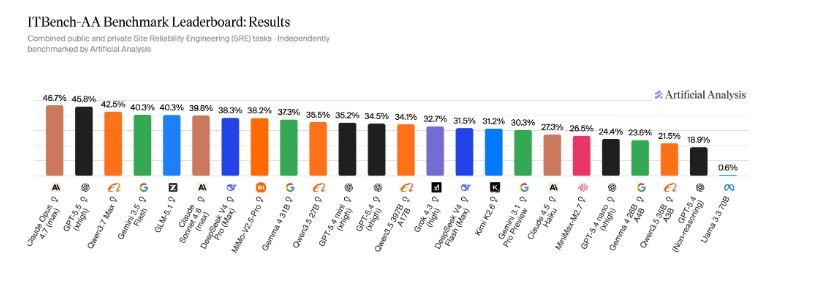
Desempenho dos Modelos de IA na Avaliação
Os resultados revelam que os modelos de ponta ainda enfrentam desafios importantes nessas tarefas complexas. Nenhum deles ultrapassou 50% de acerto médio, o que destaca a dificuldade do benchmark e a maturidade ainda em desenvolvimento dessas tecnologias para aplicações agentivas em TI.
O ranking atual apresenta:
- Claude Opus 4.7 (Adaptive Reasoning, Max Effort): líder com 47% de precisão.
- GPT-5.5 (xhigh): logo atrás, com 46%.
- Qwen3.7 Max: 42%.
Modelos de código aberto também demonstraram desempenho competitivo, com destaque para:
- GLM-5.1 (Reasoning): alcançando 40%, empatado com Gemini 3.5 Flash (high).
- DeepSeek V4 Pro (Reasoning, Max Effort): com 38%.
- Gemma 4 31B (Reasoning): 37%, superando Gemini 3.1 Pro Preview, que marcou 30%.
Insights sobre a Dinâmica das Interações
Um achado relevante foi que maior número de interações (turnos) não necessariamente resulta em diagnósticos mais precisos. Por exemplo, o GPT-5.5 (xhigh) faz em média 31 turnos por tarefa e obtém 46% de acurácia, enquanto o Gemini 3.1 Pro Preview chega a 83 turnos, mas com apenas 30% de precisão.
Modelos que investigam demais tendem a identificar erroneamente mecanismos upstream ou sintomas co-ocorrentes como causas, o que penaliza o escore final devido à presença de falsos positivos.
Relevância e Aplicações Práticas
O ITBench-AA representa uma ferramenta essencial para a comunidade de IA e operações de TI, pois fornece um padrão rigoroso e realista para avaliar a capacidade dos modelos em ambientes empresariais críticos. A precisão ainda abaixo de 50% indica que há muito espaço para avanços, especialmente na automação e suporte à resolução de incidentes em sistemas distribuídos complexos.
Além disso, o benchmark está estruturado para se expandir a outras áreas críticas, como FinOps e segurança da informação (CISO), o que amplia seu impacto futuro.