JetBrains lança Mellum2: modelo Mixture-of-Experts de 12 bilhões de parâmetros para texto e código

Mellum2: inovação em modelos de linguagem focados em eficiência
O JetBrains, em parceria com a Hugging Face, acaba de lançar o Mellum2, um modelo de inteligência artificial do tipo Mixture-of-Experts (MoE) com 12 bilhões de parâmetros. Diferente de modelos convencionais, Mellum2 ativa apenas 2,5 bilhões de parâmetros por token, o que garante uma inferência rápida e eficiente, ideal para aplicações de alta demanda e baixa latência.
Para quem o Mellum2 é indicado?
Este modelo foi treinado do zero para lidar com tarefas envolvendo tanto linguagem natural quanto código, tornando-o especialmente útil para desenvolvedores, equipes de engenharia de software e empresas que buscam integrar IA em seus fluxos de trabalho. Entre os principais usos estão:
- Roteamento e orquestração: classificação de prompts, seleção de ferramentas e controle de fluxo dentro de sistemas multi-modelos.
- Pipelines RAG (Retrieval-Augmented Generation): compressão de contexto, sumarização e pós-processamento de informações recuperadas.
- Sub-agentes: planejamento, validação e transformação de dados em etapas intermediárias, reduzindo a necessidade de modelos maiores para cada tarefa.
- Implantações privadas: por ser open source e eficiente, pode ser usado em ambientes self-hosted que lidam com código proprietário ou dados internos.
Diferenciais técnicos e desempenho
O Mellum2 utiliza a arquitetura Mixture-of-Experts, que mantém uma alta capacidade total do modelo, mas ativa apenas uma fração dos parâmetros para cada token processado. Isso resulta em:
- Inferência mais rápida: mais de duas vezes mais veloz que modelos abertos de tamanho similar.
- Eficiência de recursos: menor custo operacional em workloads em tempo real.
- Foco especializado: dedicado a texto e código, evitando a complexidade e o peso dos modelos multimodais.
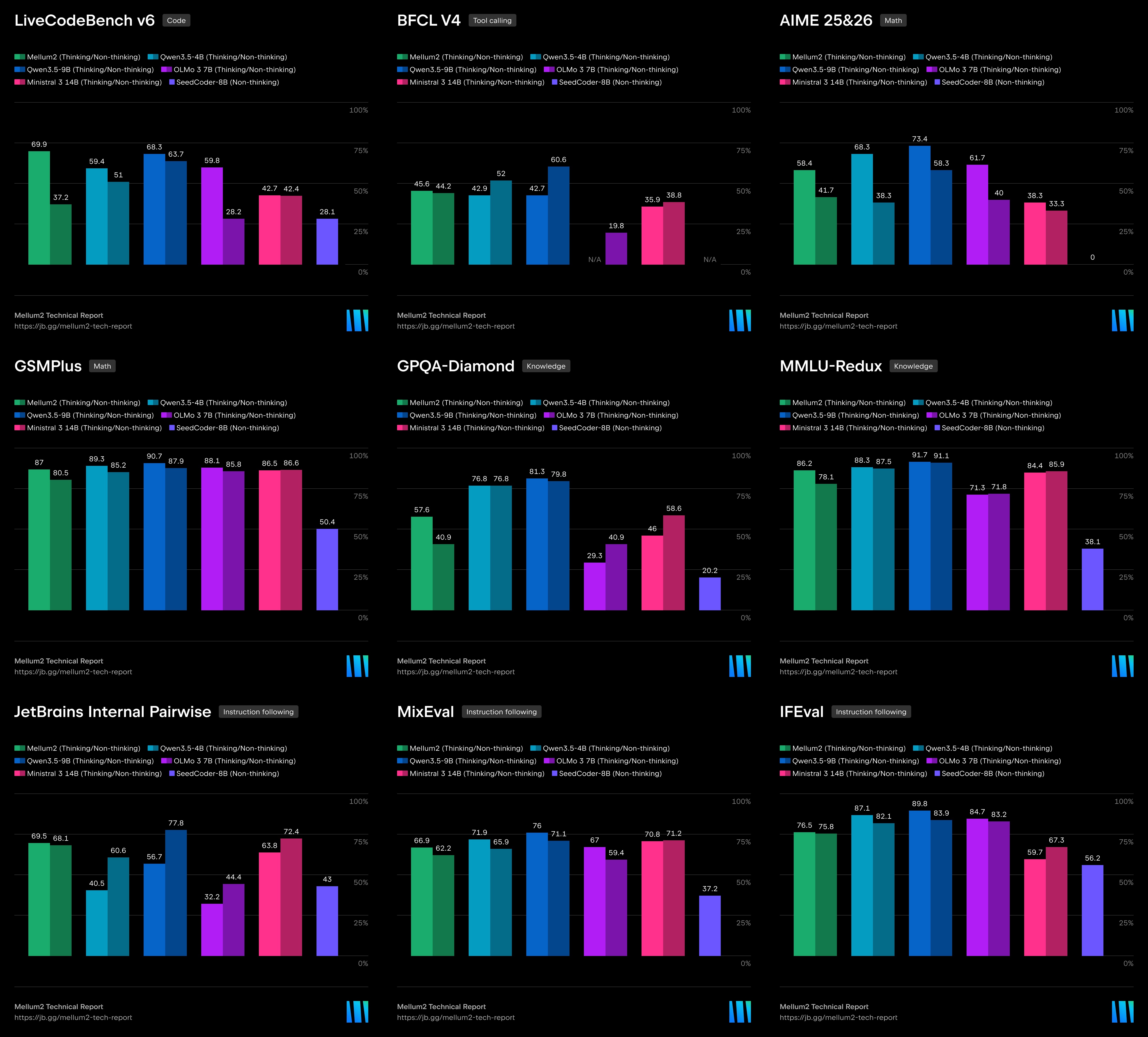
Os benchmarks apresentados no relatório técnico (disponível no arXiv) mostram que Mellum2 é competitivo em tarefas de geração de código, raciocínio, ciência e matemática.
Licença, acesso e como começar a usar
Mellum2 é disponibilizado sob a licença Apache 2.0, o que permite seu uso livre e modificações conforme as necessidades do usuário. Para acessar o modelo, basta visitar a coleção oficial no Hugging Face:
https://huggingface.co/collections/JetBrains/mellum-2
Quem ainda não possui conta pode se cadastrar gratuitamente em:
Além disso, a documentação completa para integração, uso e detalhes técnicos está disponível em:
Impacto prático para desenvolvedores e empresas
À medida que sistemas de IA se tornam mais complexos, a tendência é a composição de múltiplos modelos especializados para tarefas específicas. Mellum2 se posiciona como um modelo rápido e focado, ideal para ser o “núcleo” em sistemas que requerem alta frequência de chamadas, como:
- Redução de custos e latência em pipelines de processamento de linguagem natural e código.
- Melhoria na orquestração de modelos, evitando o uso desnecessário de grandes modelos para tarefas simples.
- Facilidade de implantação em ambientes privados, garantindo segurança e controle sobre dados sensíveis.
Com isso, Mellum2 contribui para tornar sistemas de IA mais rápidos, econômicos e fáceis de gerenciar, especialmente em contextos corporativos e de engenharia de software.