Kimina-Prover: Revolucionando o Raciocínio Formal com Busca RL em Modelos de IA de Grande Escala

Nos últimos anos, o avanço dos modelos de inteligência artificial tem impulsionado uma revolução no campo do raciocínio formal, uma área crucial para a verificação automática de teoremas e a resolução de problemas complexos de lógica. Um dos desafios centrais é como melhorar a eficiência e a precisão desses modelos durante a inferência, especialmente em tarefas que exigem raciocínio simbólico rigoroso. É nesse contexto que surge o Kimina-Prover, uma abordagem inovadora que aplica a busca baseada em aprendizado por reforço (RL) durante o tempo de teste para aprimorar o desempenho de grandes modelos de raciocínio formal.
O que é o Kimina-Prover?
Kimina-Prover é um sistema desenvolvido para otimizar o processo de prova automática em modelos de inteligência artificial que lidam com raciocínio formal. Diferentemente de métodos tradicionais que aplicam estratégias fixas durante a inferência, o Kimina-Prover incorpora uma busca dinâmica guiada por aprendizado por reforço no momento da execução, ou seja, "test-time RL search". Isso significa que o modelo pode explorar diferentes caminhos de raciocínio em tempo real, aprendendo a escolher as melhores estratégias para resolver um problema específico.
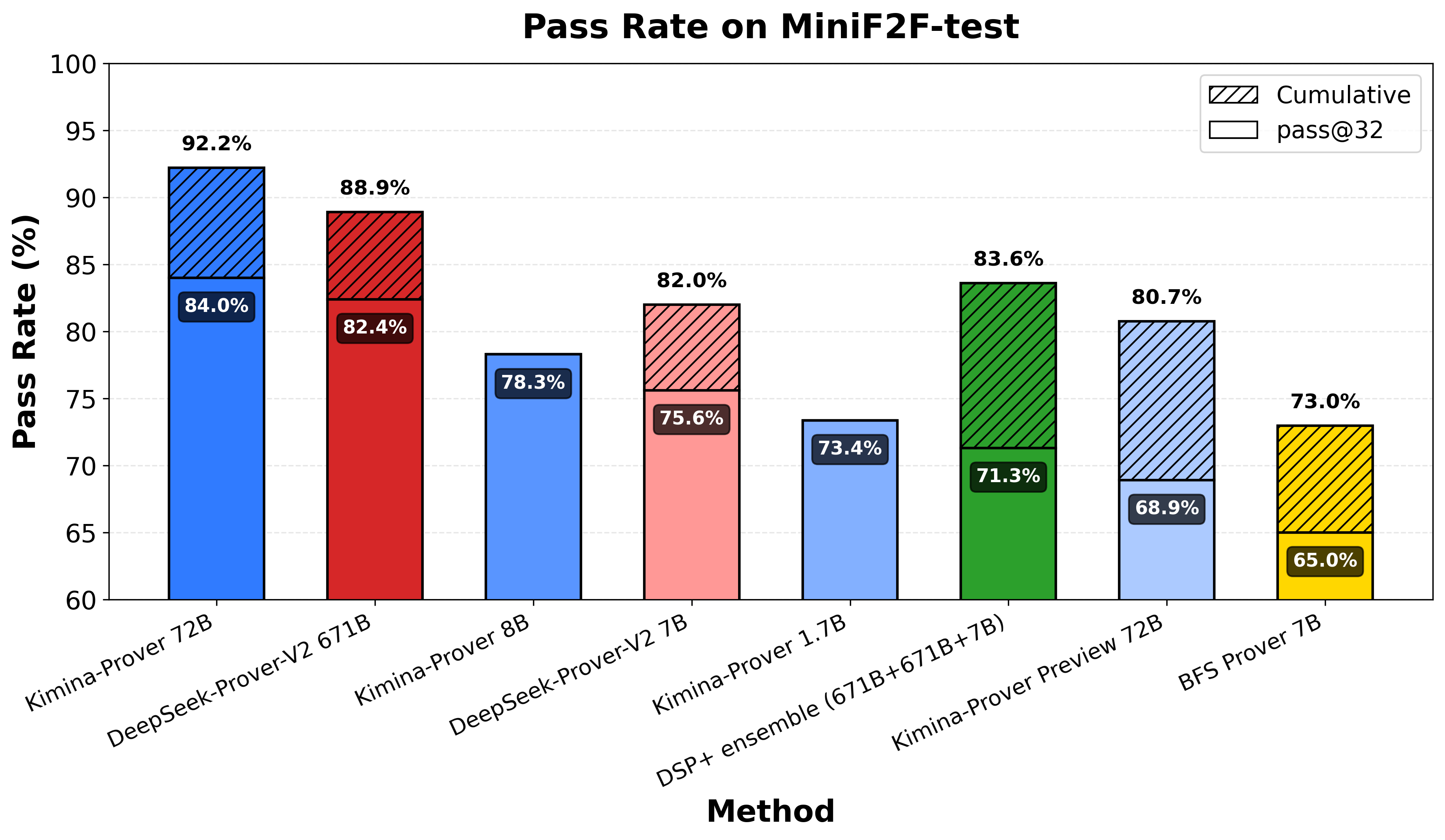
Por que a busca RL em tempo de teste é inovadora?
- Adaptação dinâmica: Em vez de depender exclusivamente do treinamento prévio, o modelo ajusta sua estratégia conforme o problema apresentado, aumentando a flexibilidade.
- Exploração eficiente: A busca guiada por RL permite explorar múltiplas possibilidades de raciocínio, evitando caminhos ineficazes.
- Melhoria contínua: O sistema pode aprender com suas próprias decisões durante a inferência, refinando suas escolhas para problemas futuros.
Como funciona o Kimina-Prover na prática?
O processo começa com um modelo de raciocínio formal treinado em uma vasta base de dados de teoremas e provas. Quando confrontado com um novo problema, o Kimina-Prover não se limita a aplicar diretamente o modelo para gerar uma prova. Em vez disso, ele executa uma busca estratégica, onde múltiplas tentativas de prova são avaliadas e guiadas por um agente de aprendizado por reforço.
Esse agente atribui valores às diferentes ações possíveis, como aplicar certos axiomas ou regras de inferência, e escolhe as que têm maior probabilidade de levar a uma prova válida. O processo é iterativo e adaptativo, permitindo que o sistema explore caminhos alternativos e evite erros comuns.
Benefícios para o campo do raciocínio formal
- Aumento da taxa de sucesso: A busca RL melhora significativamente a capacidade do modelo de encontrar provas corretas.
- Redução do tempo de inferência: Ao focar em estratégias mais promissoras, o sistema evita buscas exaustivas e demoradas.
- Escalabilidade: A abordagem é especialmente eficaz em modelos de grande escala, que lidam com problemas complexos e extensos.
Implicações e aplicações futuras
O desenvolvimento do Kimina-Prover representa um passo importante para a integração entre aprendizado de máquina e raciocínio simbólico. Essa combinação pode acelerar avanços em áreas como verificação formal de software, inteligência artificial explicável e até mesmo na automação de descobertas científicas.
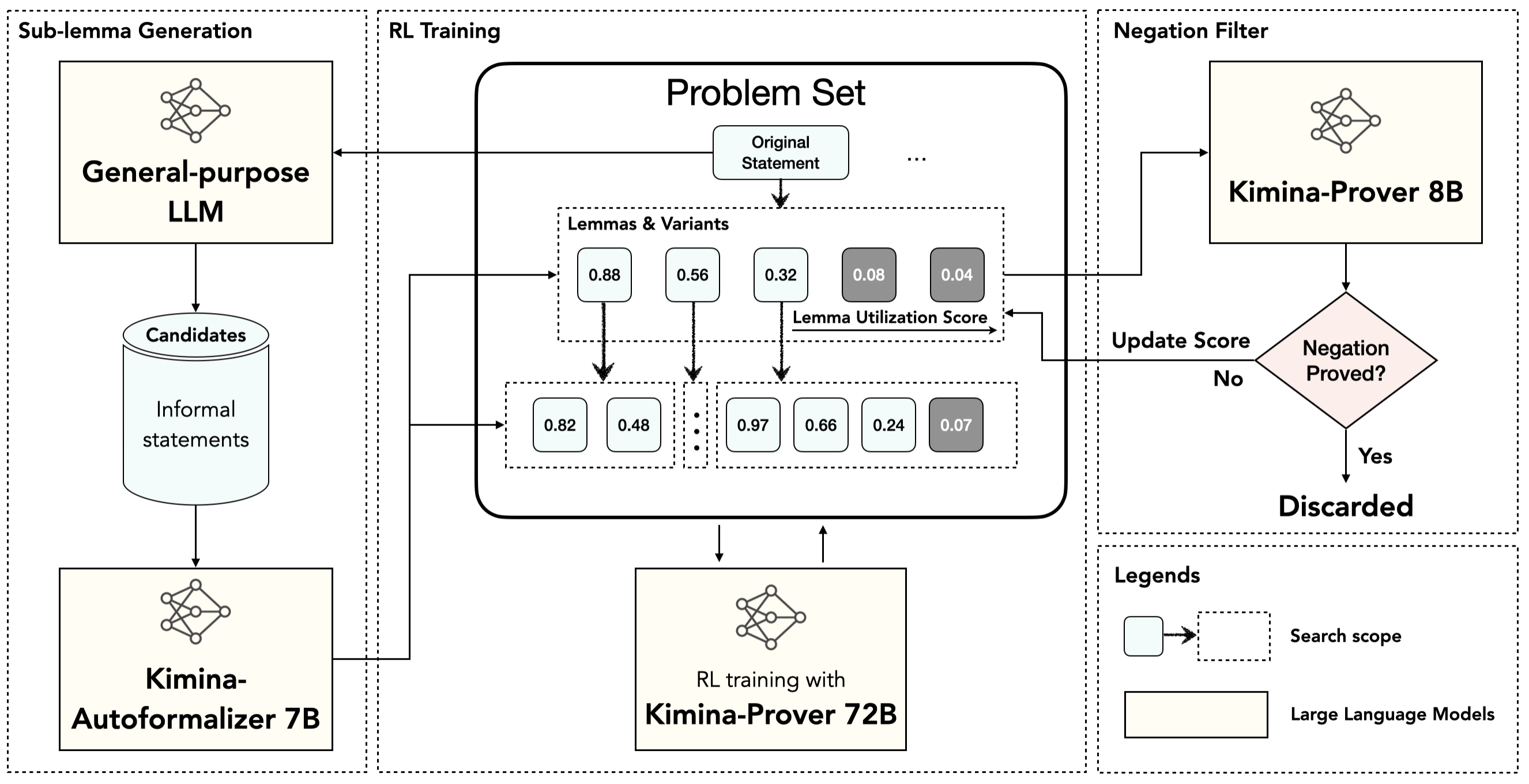
Além disso, a técnica de aplicar busca baseada em aprendizado por reforço durante o tempo de teste pode ser adaptada para outras tarefas complexas de IA, onde a tomada de decisão sequencial e a exploração de múltiplas possibilidades são essenciais.
Conclusão
O Kimina-Prover demonstra como a união entre modelos de raciocínio formal e técnicas avançadas de aprendizado por reforço pode transformar a forma como máquinas resolvem problemas lógicos complexos. Ao permitir uma busca inteligente e adaptativa durante a inferência, essa abordagem eleva o potencial dos sistemas de IA para atuar em domínios que exigem rigor e precisão.
Com o contínuo aprimoramento dessas tecnologias, podemos esperar que o raciocínio automático se torne cada vez mais eficiente e confiável, abrindo portas para aplicações inovadoras e impactantes no futuro da inteligência artificial.