Liger GRPO e TRL: A Nova Fronteira no Aprendizado por Reforço em IA

Nos últimos anos, o campo da Inteligência Artificial (IA) tem avançado rapidamente, especialmente no que diz respeito ao aprendizado por reforço, uma técnica que permite que agentes aprendam a tomar decisões otimizadas por meio de interações com o ambiente. Recentemente, uma combinação inovadora entre o algoritmo Liger GRPO e a biblioteca TRL (Transformers Reinforcement Learning) tem chamado a atenção da comunidade científica e tecnológica por suas aplicações promissoras e melhorias significativas no desempenho de agentes inteligentes.
Introdução ao Aprendizado por Reforço e ao Liger GRPO
O aprendizado por reforço (Reinforcement Learning - RL) é uma área da IA que foca no desenvolvimento de agentes capazes de aprender estratégias eficazes para maximizar recompensas em ambientes dinâmicos e incertos. Entre os diversos algoritmos existentes, o Liger GRPO surge como uma abordagem robusta que combina técnicas de otimização e políticas probabilísticas para melhorar a eficiência do aprendizado.
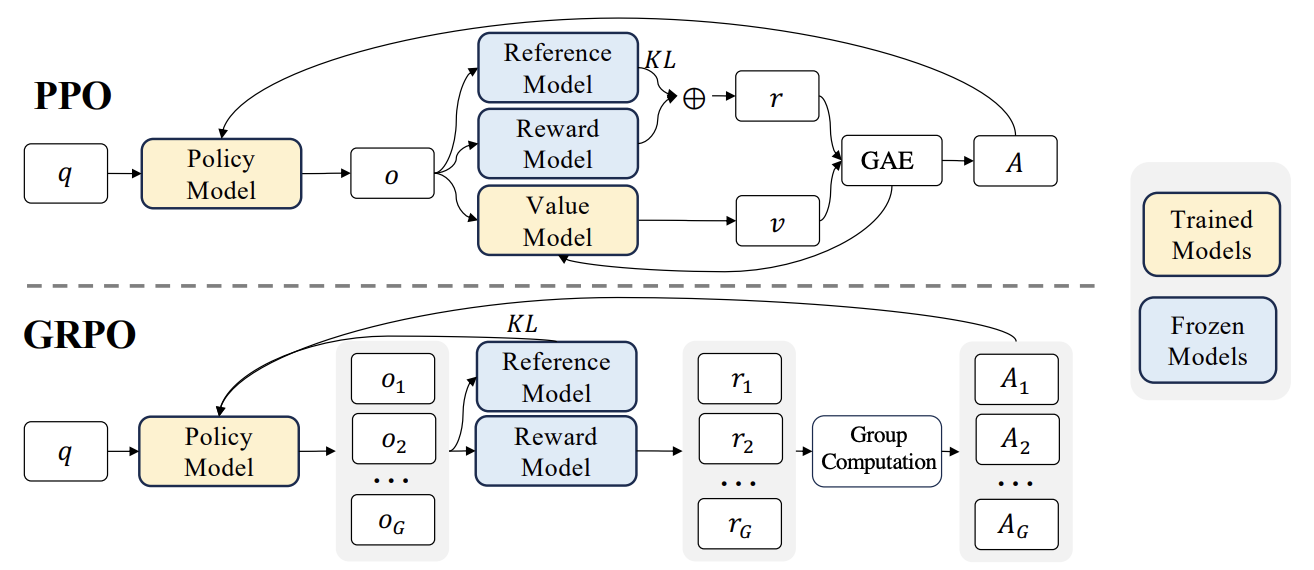
O Liger GRPO (Gradient Regularized Policy Optimization) é um algoritmo que busca otimizar políticas de decisão de forma estável e eficiente, mitigando problemas comuns como a instabilidade do gradiente e a convergência prematura. Essa técnica é especialmente útil em cenários complexos, onde o ambiente apresenta alta dimensionalidade e variabilidade.
O Papel da Biblioteca TRL no Desenvolvimento de Agentes Inteligentes
A biblioteca TRL (Transformers Reinforcement Learning) é uma ferramenta open-source que facilita a implementação e experimentação de modelos de aprendizado por reforço baseados em arquiteturas Transformer. Essa biblioteca oferece suporte para integração com diversos algoritmos, ambientes e frameworks, tornando o desenvolvimento mais ágil e acessível.
Ao unir a capacidade dos Transformers em capturar dependências de longo prazo com as técnicas avançadas de aprendizado por reforço, o TRL permite a criação de agentes que aprendem políticas mais complexas e adaptativas, capazes de lidar com tarefas desafiadoras em jogos, robótica, processamento de linguagem natural e muito mais.
Como o Liger GRPO e o TRL se Complementam
A combinação do Liger GRPO com a biblioteca TRL representa um avanço significativo para a comunidade de IA. O Liger GRPO traz uma otimização eficiente e estável das políticas, enquanto o TRL oferece uma infraestrutura poderosa para implementar e testar essas políticas em modelos Transformer.
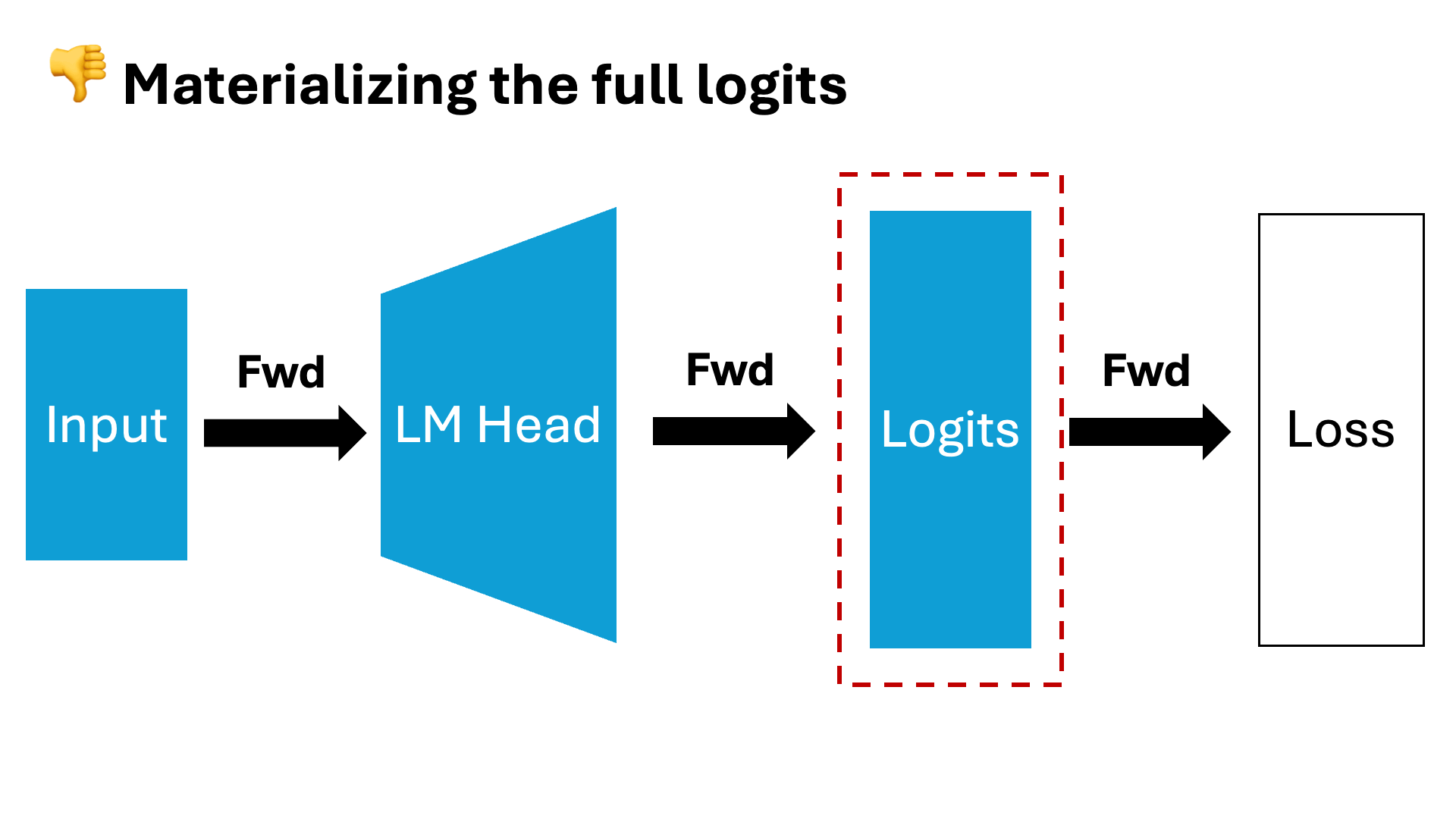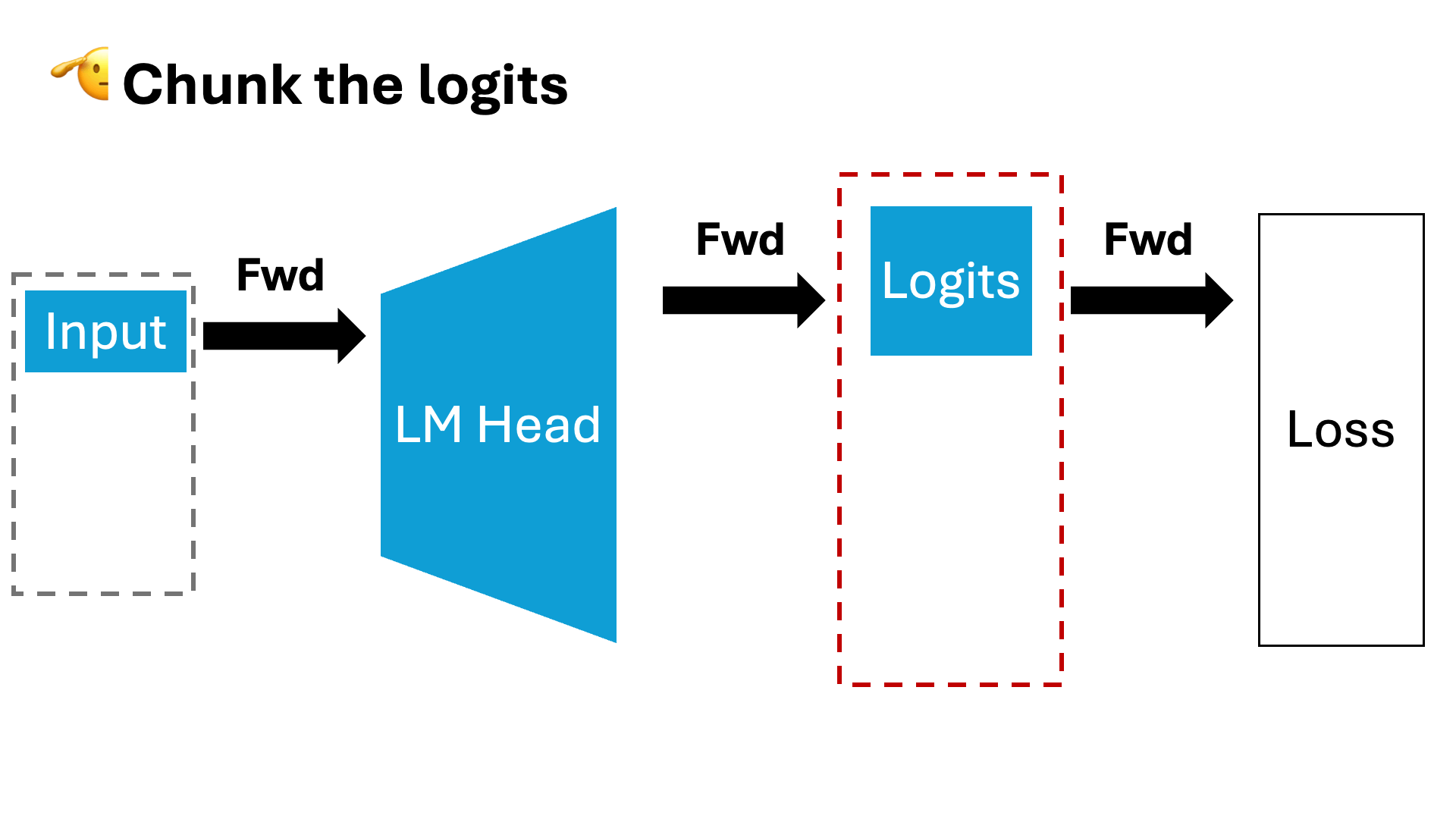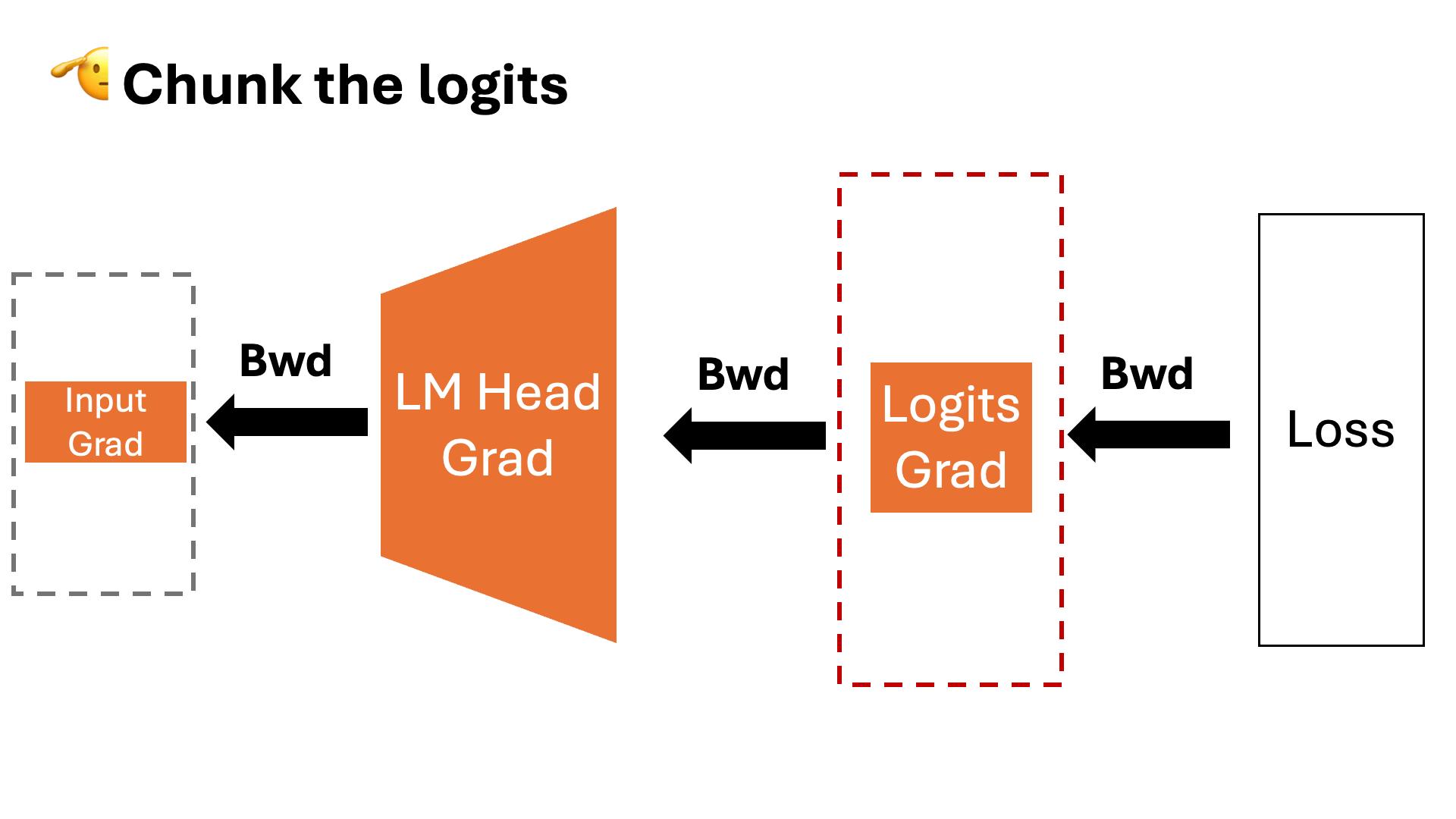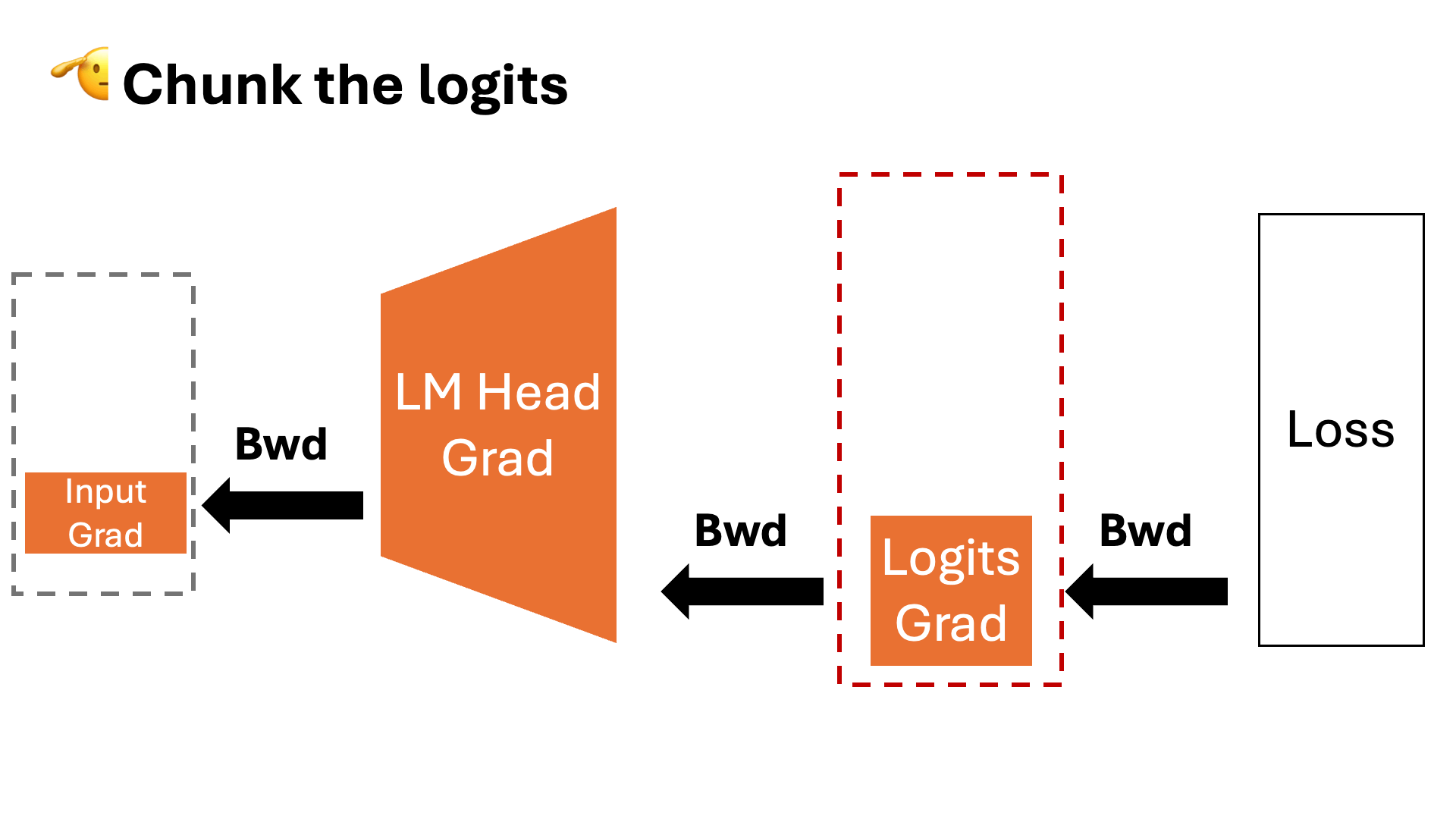
- Estabilidade no treinamento: O Liger GRPO reduz oscilações e melhora a convergência das políticas, crucial para modelos complexos como Transformers.
- Flexibilidade: O TRL permite experimentar diferentes arquiteturas e ambientes, facilitando a adaptação do Liger GRPO a múltiplos contextos.
- Desempenho aprimorado: A sinergia entre os dois permite que agentes aprendam estratégias mais sofisticadas em menos tempo.
Aplicações e Impactos Práticos
Essa integração abre portas para diversas aplicações práticas, tais como:
- Jogos e simulações: Desenvolvimento de agentes capazes de superar humanos em jogos complexos, com aprendizado mais rápido e robusto.
- Robótica: Controle adaptativo de robôs em ambientes dinâmicos, melhorando a autonomia e segurança.
- Processamento de linguagem natural: Agentes que aprendem a interagir e responder de forma mais natural e contextualizada.
- Sistemas de recomendação: Personalização dinâmica baseada em feedback contínuo dos usuários.
Desafios e Perspectivas Futuras
Apesar dos avanços, ainda existem desafios a serem superados, como a escalabilidade para ambientes ainda mais complexos, a interpretação das decisões tomadas pelos agentes e a garantia de segurança e ética no uso dessas tecnologias. No entanto, a união do Liger GRPO com o TRL indica um caminho promissor para o desenvolvimento de agentes cada vez mais inteligentes e confiáveis.
Pesquisadores e desenvolvedores estão explorando novas formas de aprimorar essa combinação, incluindo o uso de aprendizado multiagente, integração com outras técnicas de IA e aplicação em áreas emergentes como saúde e finanças.
Conclusão
A integração do algoritmo Liger GRPO com a biblioteca TRL representa um marco importante no aprendizado por reforço, combinando estabilidade, eficiência e flexibilidade para criar agentes inteligentes mais capazes e adaptativos. Essa inovação não apenas amplia as possibilidades de aplicação da IA, mas também fortalece a base para futuras pesquisas e desenvolvimentos no campo.
Para profissionais e entusiastas da IA, acompanhar esses avanços é fundamental para entender as tendências e preparar-se para as transformações que a inteligência artificial continuará a trazer para diversos setores da sociedade.