Maximizando o Poder das GPUs: Eficiência Revolucionária com vLLM Co-localizado no TRL

Nos últimos anos, o avanço da Inteligência Artificial tem exigido cada vez mais recursos computacionais robustos, especialmente GPUs (Unidades de Processamento Gráfico). Contudo, a utilização eficiente desses recursos ainda é um desafio, principalmente quando se trata de modelos de linguagem de grande escala. Pensando nisso, a HuggingFace lançou uma abordagem inovadora que promete revolucionar a forma como as GPUs são aproveitadas: o vLLM co-localizado no TRL.
O Desafio da Eficiência em GPUs para Modelos de Linguagem
Modelos de linguagem grandes, como os baseados em Transformers, demandam alto poder computacional e memória. Tradicionalmente, para acelerar o processamento, múltiplas GPUs são utilizadas em paralelo, mas isso pode acarretar em subutilização dos recursos disponíveis, latências elevadas e custos operacionais altos.
Além disso, a escalabilidade nem sempre é linear, e a comunicação entre GPUs pode gerar gargalos que comprometem a eficiência geral do sistema. Por isso, encontrar uma solução que maximize o uso das GPUs sem sacrificar desempenho é fundamental para o avanço da IA.
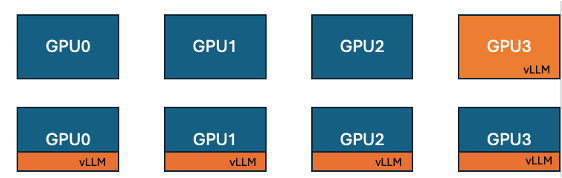
O que é o vLLM Co-localizado no TRL?
O vLLM é uma biblioteca de inferência para modelos de linguagem que foca em otimizar a latência e o throughput na execução de grandes modelos. Já o TRL (Transformer Reinforcement Learning) é uma plataforma para treinamento e ajuste fino de modelos de linguagem utilizando aprendizado por reforço.
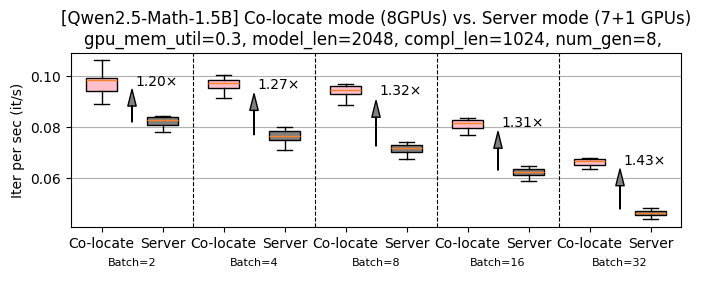
A proposta da HuggingFace é a integração co-localizada dessas duas tecnologias, ou seja, executar o vLLM diretamente dentro do ambiente TRL utilizando as mesmas GPUs. Essa co-localização permite um uso mais eficiente dos recursos, reduzindo a necessidade de comunicação interprocessos e aproveitando melhor a memória e o poder computacional disponível.
Benefícios da Integração
- Redução de Latência: Ao eliminar a comunicação entre processos separados, as respostas dos modelos são geradas mais rapidamente.
- Melhor Utilização da GPU: A co-localização evita ociosidade e fragmentação de recursos, garantindo que cada GPU trabalhe no máximo de sua capacidade.
- Escalabilidade Aprimorada: Permite que múltiplos modelos e tarefas sejam executados simultaneamente, facilitando experimentos e produção em larga escala.
- Custos Operacionais Menores: Com maior eficiência, é possível reduzir a quantidade de hardware necessária, economizando energia e investimentos.
Como Funciona na Prática?
Na prática, o vLLM co-localizado no TRL atua como um motor de inferência embutido dentro do pipeline de treinamento por reforço. Isso significa que, durante o ajuste fino do modelo, as respostas geradas pelo vLLM são utilizadas imediatamente para calcular recompensas e atualizar os parâmetros.
Essa integração estreita elimina a necessidade de transferir dados entre sistemas distintos, acelerando o ciclo de treinamento e melhorando a qualidade dos modelos resultantes. Além disso, a arquitetura modular do vLLM permite adaptar facilmente o sistema para diferentes tamanhos e tipos de modelos.
Casos de Uso e Aplicações
- Chatbots e Assistentes Virtuais: Respostas mais rápidas e precisas com menor custo computacional.
- Geração de Conteúdo: Produção de textos em larga escala com maior fluidez e coerência.
- Pesquisa e Desenvolvimento: Experimentação ágil em modelos de linguagem avançados.
- Personalização de Modelos: Ajuste fino eficiente para aplicações específicas, como atendimento ao cliente ou análise de sentimentos.
Conclusão: O Futuro da Eficiência em IA
A integração do vLLM co-localizado no TRL representa um passo significativo para superar os desafios de eficiência e escalabilidade no uso de GPUs para modelos de linguagem. Ao maximizar o aproveitamento dos recursos computacionais, essa abordagem não só reduz custos, mas também acelera o desenvolvimento e a implantação de soluções baseadas em IA.
Para pesquisadores, desenvolvedores e empresas, essa inovação abre novas possibilidades para explorar o potencial dos modelos de linguagem de forma mais sustentável e eficaz. Ficar atento a essas tecnologias é essencial para se manter competitivo no cenário cada vez mais dinâmico da Inteligência Artificial.