Mini-R1: Explorando o Momento 'Aha' no Aprendizado por Reforço Profundo

O aprendizado por reforço (RL) tem ganhado destaque como uma das áreas mais promissoras da inteligência artificial, permitindo que agentes aprendam comportamentos complexos através da interação com o ambiente. Entre os diversos tutoriais e projetos que buscam desmistificar essa técnica, o Mini-R1 surge como uma ferramenta essencial para reproduzir o famoso "momento aha" do Deepseek R1, um marco no entendimento prático do RL.
Introdução ao Mini-R1 e o Conceito do "Momento Aha" no RL
O "momento aha" refere-se àquele instante em que um agente de aprendizado por reforço descobre uma estratégia eficaz para maximizar sua recompensa, demonstrando uma compreensão clara do ambiente e das ações que levam ao sucesso. O Mini-R1 é um tutorial simplificado que permite aos desenvolvedores e entusiastas replicar essa experiência, facilitando o aprendizado e a experimentação com conceitos fundamentais do RL.

Por Que o Mini-R1 é Importante para Quem Quer Aprender RL?
- Didático e acessível: O Mini-R1 oferece uma abordagem passo a passo para entender como agentes aprendem através de recompensas e punições.
- Reprodução do Deepseek R1: Permite reviver o momento de descoberta do Deepseek R1, um tutorial reconhecido por sua clareza e eficácia.
- Experiência prática: Ao invés de apenas conceitos teóricos, o Mini-R1 possibilita a implementação e teste de algoritmos em um ambiente controlado.
- Base para projetos avançados: Compreender o Mini-R1 prepara o terreno para explorar modelos mais complexos e aplicações reais do RL.
Como Funciona o Mini-R1?
O Mini-R1 apresenta um ambiente simplificado onde um agente deve aprender a maximizar sua recompensa através de ações sequenciais. A estrutura do tutorial guia o usuário desde a definição do ambiente e das regras até a implementação do algoritmo de aprendizado por reforço, geralmente utilizando Q-learning ou métodos similares.
Durante o processo, o agente experimenta diferentes estratégias e, gradualmente, identifica padrões que levam a melhores resultados. O "momento aha" ocorre quando o agente descobre uma política ótima ou quase ótima, evidenciando a eficácia do RL.
Componentes Principais do Mini-R1
- Ambiente: Um cenário controlado com estados e recompensas definidas.
- Agente: O modelo que toma decisões baseado nas informações do ambiente.
- Política: A estratégia que o agente utiliza para escolher ações.
- Função de valor: Avalia a qualidade das ações em determinados estados.
- Algoritmo de aprendizado: Método pelo qual o agente atualiza sua política com base nas recompensas recebidas.
Benefícios de Estudar o Mini-R1 para Desenvolvedores e Pesquisadores
Ao trabalhar com o Mini-R1, os profissionais ganham uma compreensão sólida dos fundamentos do RL, o que é crucial para avançar em projetos mais complexos, como jogos, robótica e sistemas autônomos. Além disso, o tutorial incentiva a experimentação, permitindo que os usuários testem diferentes parâmetros e observem como isso impacta o aprendizado do agente.
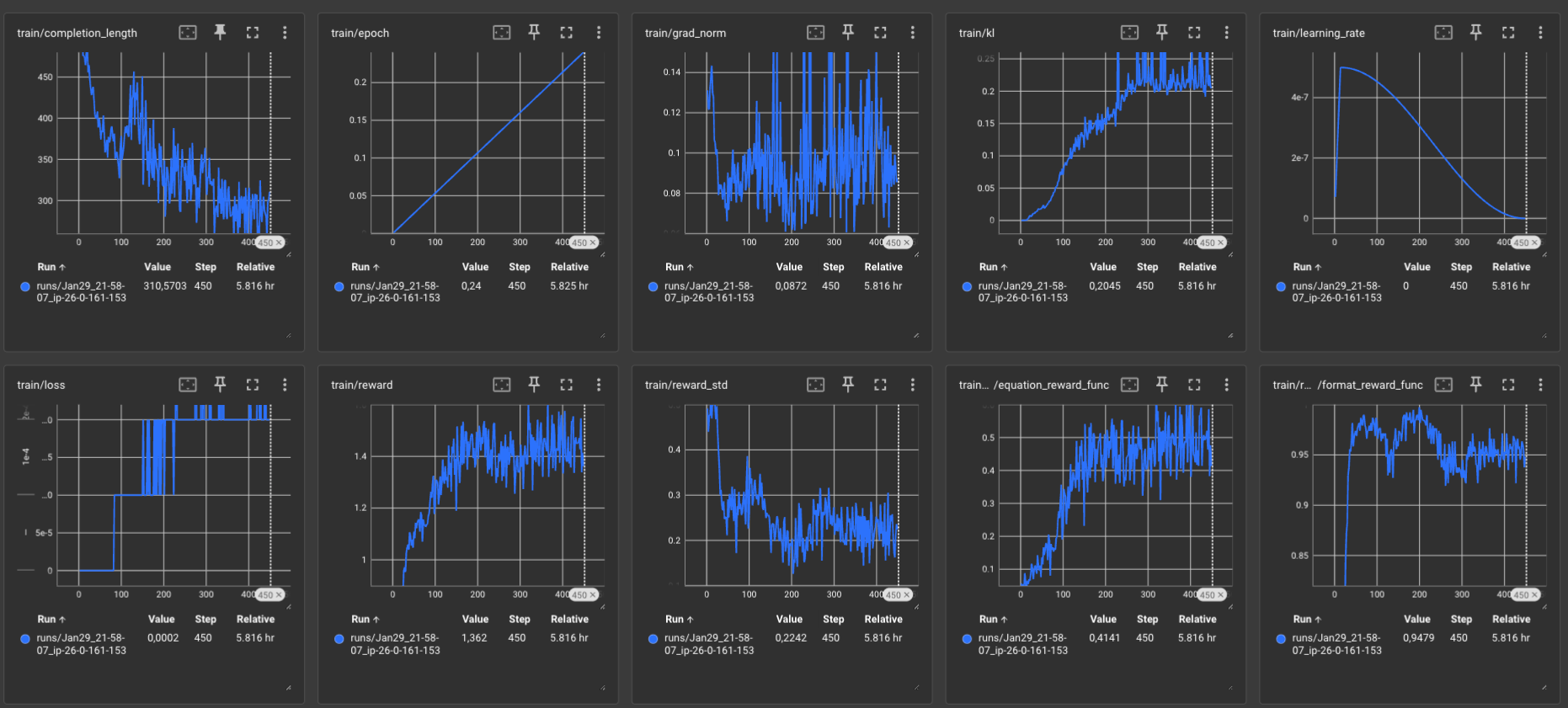
Essa experiência prática é valiosa para:
- Desenvolver intuição sobre o comportamento de agentes RL.
- Identificar desafios comuns, como exploração versus exploração.
- Aprender a ajustar hiperparâmetros para melhorar o desempenho.
- Preparar-se para implementar RL em aplicações do mundo real.
Conclusão: O Mini-R1 como Porta de Entrada para o Mundo do Aprendizado por Reforço
O Mini-R1 representa uma ferramenta poderosa para quem deseja compreender e aplicar os conceitos de aprendizado por reforço de maneira prática e envolvente. Ao reproduzir o "momento aha" do Deepseek R1, ele oferece uma experiência educativa que vai além da teoria, preparando desenvolvedores e pesquisadores para os desafios e oportunidades que o RL oferece.
Se você está começando sua jornada no aprendizado por reforço, explorar o Mini-R1 pode ser o passo decisivo para transformar conhecimento em habilidade aplicada, abrindo portas para inovações em inteligência artificial.