Modelos Visão-Linguagem: Revolução na Interpretação de Imagens e Texto

Nos últimos anos, a inteligência artificial (IA) tem avançado rapidamente, especialmente no campo da visão computacional e do processamento de linguagem natural. Uma das áreas que mais tem chamado atenção é a dos Modelos Visão-Linguagem, que combinam a capacidade de entender imagens e textos de forma integrada, abrindo portas para aplicações inovadoras e mais inteligentes.
O que são Modelos Visão-Linguagem?
Modelos Visão-Linguagem são sistemas de IA treinados para interpretar e relacionar informações visuais com dados textuais. Diferente dos modelos tradicionais que focam apenas em imagens ou apenas em texto, esses modelos conseguem compreender o contexto de uma imagem e associá-lo a descrições, perguntas ou comandos em linguagem natural.
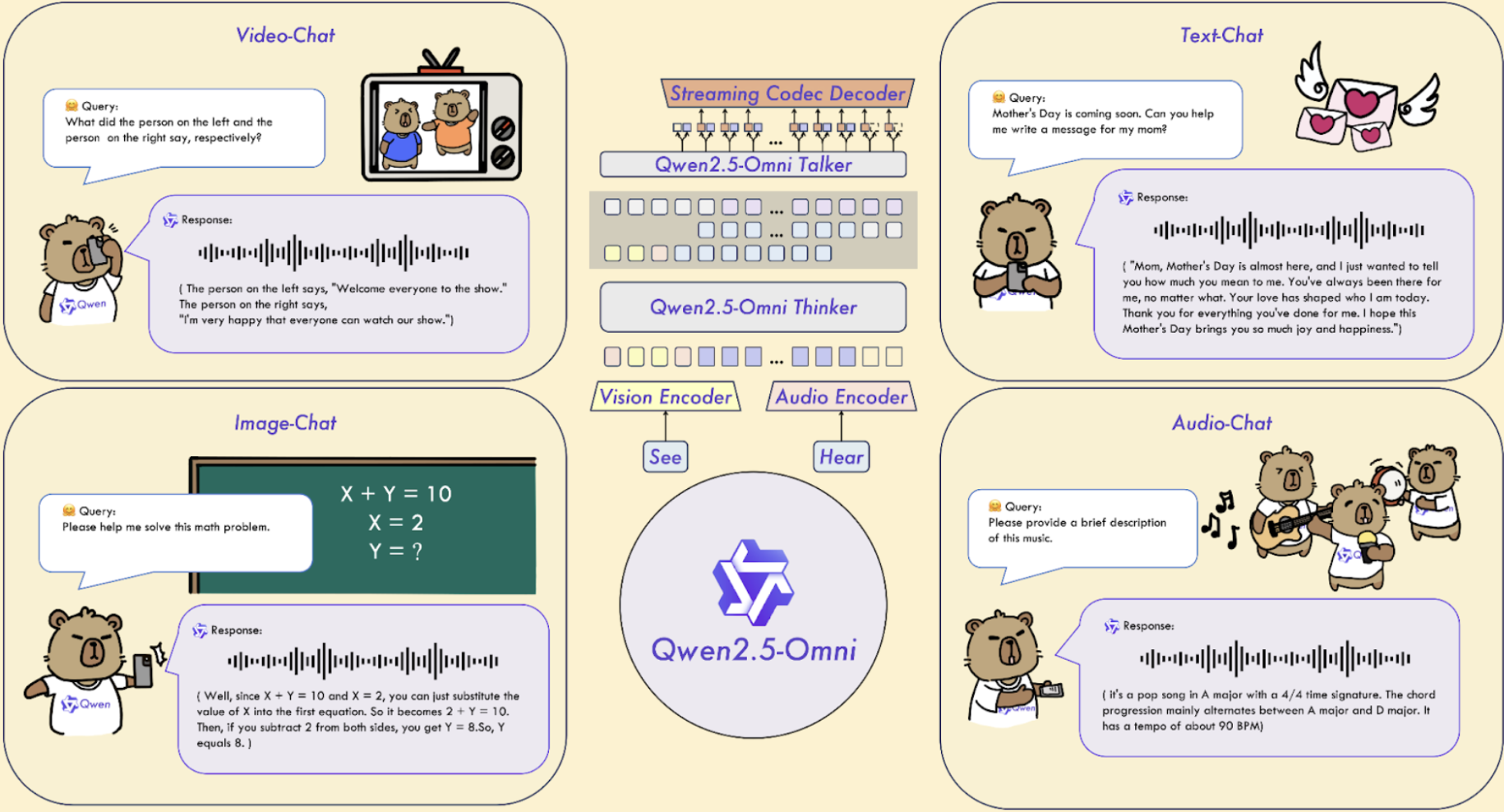
Como funcionam?
Esses modelos utilizam arquiteturas avançadas, como Transformers, que são capazes de processar sequências de dados complexas. Eles recebem entradas multimodais — imagens e textos — e aprendem a criar representações conjuntas que facilitam tarefas como legenda automática de imagens, respostas a perguntas visuais e até mesmo geração de imagens a partir de descrições textuais.
Por que esses modelos são melhores, mais rápidos e mais fortes?
O título original do artigo da HuggingFace destaca três atributos essenciais desses modelos:
- Melhores: A integração multimodal permite uma compreensão mais rica e contextualizada, o que melhora a precisão e a relevância das respostas geradas.
- Mais rápidos: Novas arquiteturas e otimizações no treinamento e inferência tornam esses modelos mais eficientes, reduzindo o tempo necessário para processar informações complexas.
- Mais fortes: A capacidade de generalizar para diferentes tarefas e domínios faz com que esses modelos sejam robustos e versáteis, aptos a lidar com desafios variados no mundo real.
Principais avanços tecnológicos
Entre os avanços que impulsionaram esses modelos, destacam-se:
- Arquiteturas híbridas: Combinação de redes neurais convolucionais para imagens e Transformers para texto.
- Pré-treinamento multimodal: Treinamento em grandes conjuntos de dados que incluem pares imagem-texto, o que permite aprendizado mais profundo das relações entre as modalidades.
- Fine-tuning eficiente: Ajustes específicos para tarefas variadas, como geração de legendas, classificação de imagens com base em descrições ou respostas a perguntas visuais.
Aplicações práticas que transformam o mercado
Os Modelos Visão-Linguagem estão revolucionando diversos setores. Veja algumas aplicações:
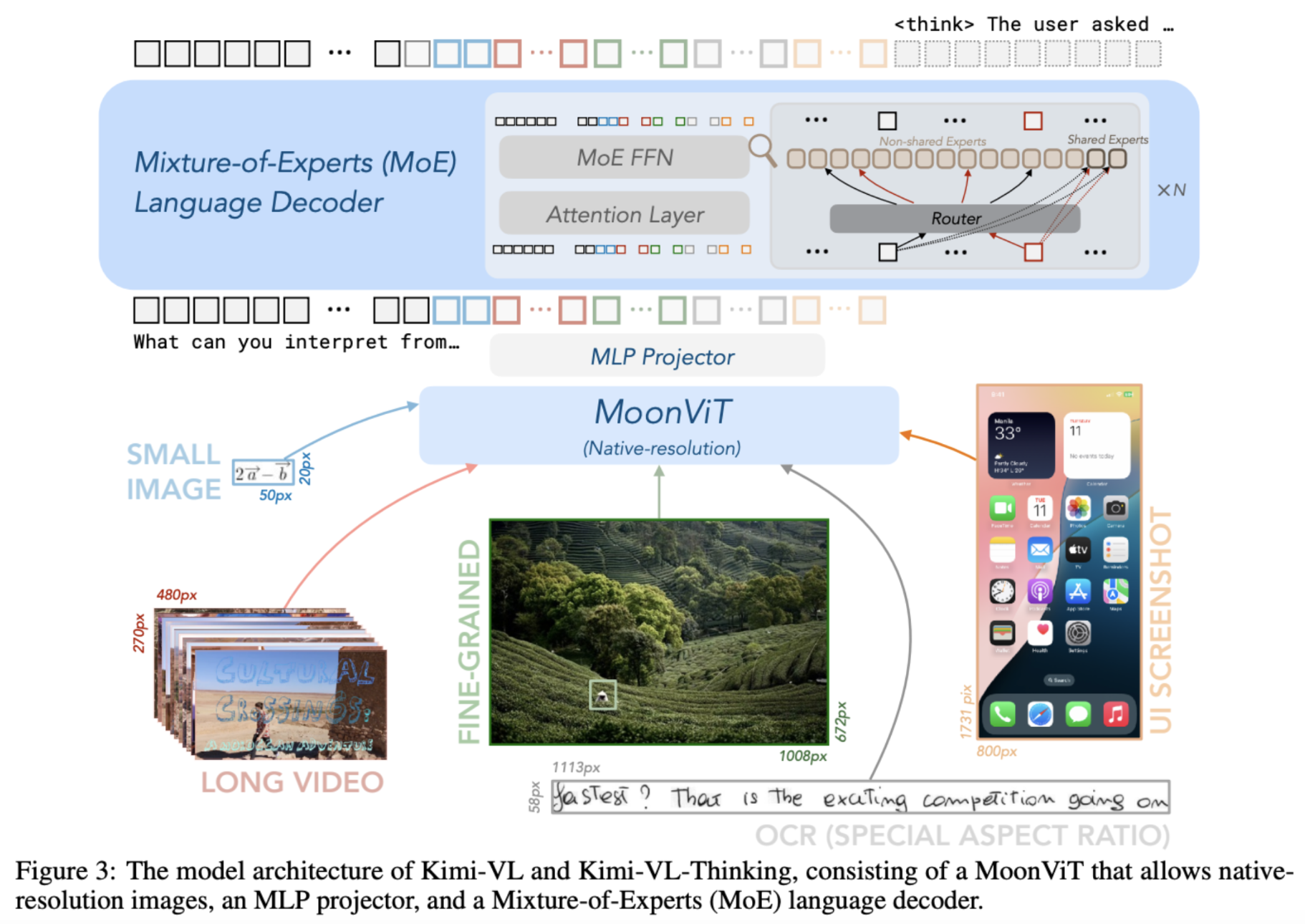
- Assistentes virtuais mais inteligentes: Capazes de interpretar imagens enviadas pelo usuário e responder com informações precisas.
- Diagnóstico médico: Análise integrada de imagens médicas e relatórios textuais para auxiliar profissionais na tomada de decisão.
- Comércio eletrônico: Busca visual aprimorada, onde o consumidor pode encontrar produtos por meio de fotos e descrições.
- Educação: Ferramentas que combinam imagens e textos para criar conteúdos interativos e personalizados.
Desafios e o futuro dos Modelos Visão-Linguagem
Apesar dos avanços, ainda existem desafios importantes a serem superados, como:
- Viés nos dados: Garantir que os modelos não reproduzam preconceitos presentes nos conjuntos de treinamento.
- Interpretação contextual complexa: Melhorar a compreensão de nuances culturais e subjetivas em imagens e textos.
- Escalabilidade: Desenvolver modelos que sejam acessíveis e eficientes para uso em dispositivos com recursos limitados.
O futuro aponta para modelos ainda mais integrados, capazes de entender múltiplas modalidades além de imagens e textos, como áudio e vídeo, ampliando ainda mais as possibilidades de interação e automação.
Conclusão
Os Modelos Visão-Linguagem representam um marco na evolução da inteligência artificial, combinando o melhor da visão computacional e do processamento de linguagem natural. Com melhorias contínuas em desempenho, velocidade e robustez, esses modelos estão prontos para transformar a forma como interagimos com a tecnologia, tornando-a mais intuitiva, eficiente e acessível.
Ficar atento a esses avanços é fundamental para profissionais e entusiastas de IA, pois eles definem o caminho para inovações que impactarão profundamente diversos setores da sociedade.