nanoVLM: Treinando Modelos Visão-Linguagem com Simplicidade e Eficiência em PyTorch

A inteligência artificial tem avançado rapidamente, especialmente na área de modelos que combinam visão e linguagem, conhecidos como VLMs (Vision-Language Models). Esses modelos são capazes de entender imagens e textos simultaneamente, abrindo portas para aplicações inovadoras como legendas automáticas, busca visual e assistentes inteligentes multimodais.
O que é o nanoVLM?
O nanoVLM é um repositório desenvolvido para facilitar o treinamento de modelos visão-linguagem utilizando exclusivamente PyTorch, uma das bibliotecas mais populares para deep learning. Seu diferencial está na simplicidade e eficiência, permitindo que pesquisadores e desenvolvedores criem seus próprios VLMs de forma rápida e descomplicada.

Por que o nanoVLM é importante?
- Facilidade de uso: O código é limpo e organizado, ideal para quem está começando ou quer um ponto de partida sólido para projetos personalizados.
- Treinamento puro em PyTorch: Diferente de outras soluções que dependem de múltiplas bibliotecas ou frameworks, o nanoVLM mantém tudo em PyTorch, facilitando a integração e o entendimento do código.
- Flexibilidade: O repositório permite ajustes e customizações para diferentes tarefas de visão e linguagem, desde classificação até geração de legendas.
- Eficiência computacional: Projetado para ser leve, possibilita o treinamento em máquinas com recursos limitados, democratizando o acesso a essa tecnologia.
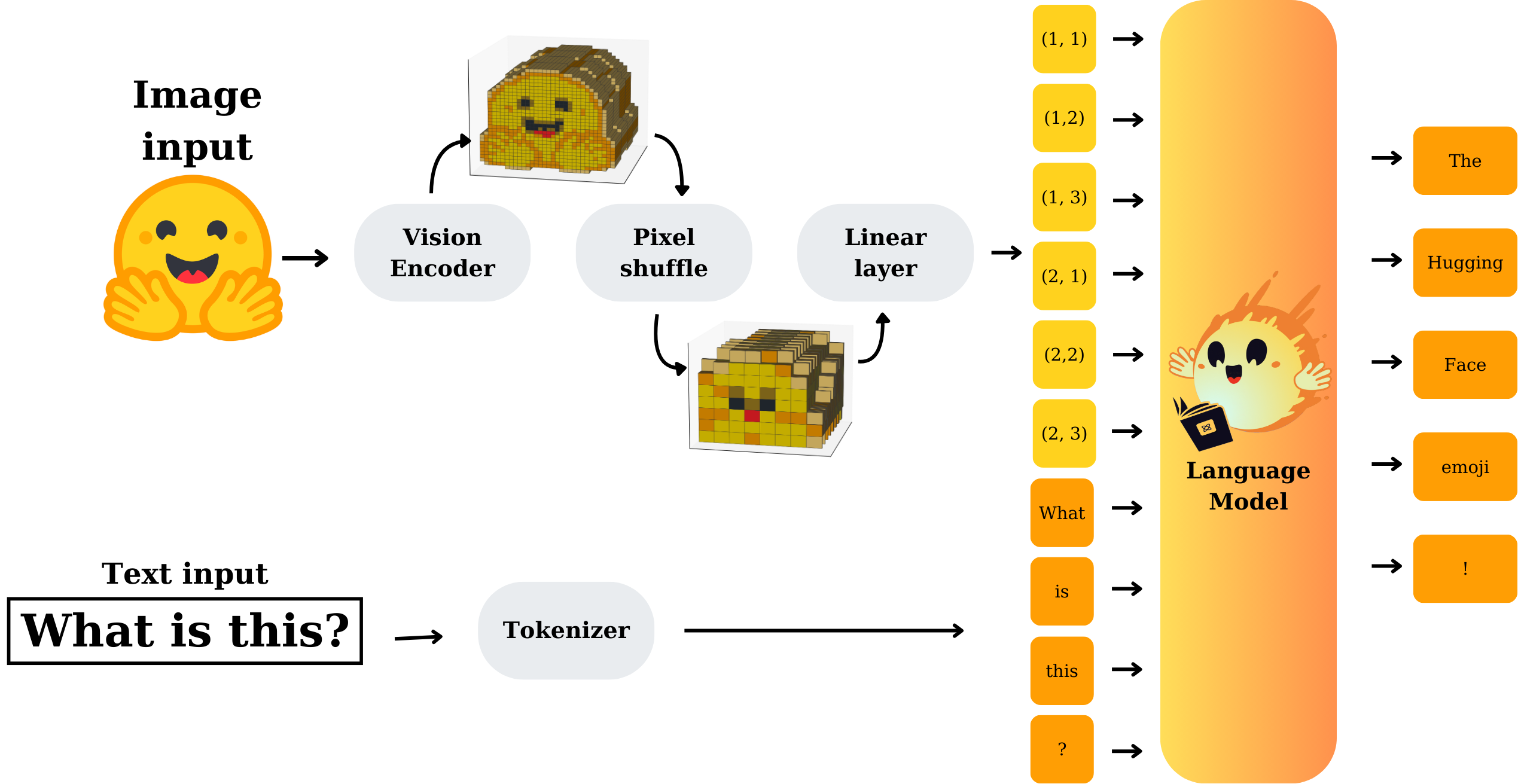
Como funciona o treinamento de um VLM com nanoVLM?
O processo de treinamento envolve a combinação de dados visuais (imagens) e textuais (legendas, descrições) para que o modelo aprenda a relacionar esses dois tipos de informação. No nanoVLM, isso é feito através de:
- Arquitetura modular: O modelo é dividido em componentes que processam imagens e textos separadamente antes de combinar as informações.
- Treinamento contrastivo: Técnica que ensina o modelo a associar corretamente imagens e textos correspondentes, enquanto diferencia pares não relacionados.
- Uso de datasets padrão: O repositório suporta conjuntos de dados amplamente utilizados na comunidade, facilitando a comparação de resultados e a replicação de estudos.
Passos básicos para começar
- Clonar o repositório nanoVLM do GitHub.
- Preparar os dados de imagem e texto conforme o formato esperado.
- Configurar os parâmetros de treinamento, como taxa de aprendizado, número de épocas e tamanho do batch.
- Executar o script de treinamento e monitorar o progresso.
- Avaliar o modelo treinado em tarefas específicas, como recuperação de imagens ou geração de legendas.
Benefícios para a comunidade de IA
Ao disponibilizar uma ferramenta simples e eficiente para o treinamento de VLMs, o nanoVLM contribui para:
- Educação: Estudantes e pesquisadores podem entender melhor os conceitos por trás dos modelos visão-linguagem.
- Pesquisa: Facilita experimentos e inovações, acelerando o desenvolvimento de novas arquiteturas e técnicas.
- Desenvolvimento de aplicações: Empresas e startups podem prototipar soluções multimodais sem a necessidade de infraestrutura complexa.
Conclusão
O nanoVLM representa um passo significativo para tornar o treinamento de modelos visão-linguagem mais acessível e transparente. Com sua abordagem em PyTorch, simplicidade e eficiência, ele é uma excelente escolha para quem deseja explorar o potencial dos VLMs, seja para fins acadêmicos ou comerciais.
Se você está interessado em inteligência artificial multimodal, vale a pena conferir o nanoVLM e experimentar criar seu próprio modelo visão-linguagem do zero. A inovação começa com ferramentas que facilitam o aprendizado e a experimentação, e o nanoVLM entrega exatamente isso.