Nemotron 3 Nano 4B: Novo Modelo Compacto da NVIDIA para IA Local Eficiente

Apresentação do Nemotron 3 Nano 4B
A NVIDIA, em parceria com a Hugging Face, lançou o Nemotron 3 Nano 4B, um modelo híbrido compacto e eficiente voltado para aplicações de inteligência artificial local. Integrante da família Nemotron 3, esse modelo utiliza a arquitetura híbrida Mamba-Transformer para oferecer um equilíbrio entre precisão e desempenho, com apenas 4 bilhões de parâmetros.
Essa redução de tamanho permite sua execução em dispositivos de borda, como as plataformas NVIDIA Jetson Thor e Jetson Orin Nano, além de servidores com GPUs NVIDIA DGX Spark e placas GeForce RTX. O resultado é uma IA com tempo de resposta rápido, maior privacidade de dados e flexibilidade na implantação, mantendo custos de inferência reduzidos.
Quem pode se beneficiar do Nemotron 3 Nano 4B?
O Nemotron 3 Nano 4B é ideal para desenvolvedores e empresas que buscam implementar agentes conversacionais e personas locais, especialmente em ambientes com recursos limitados de memória e processamento. Seu design é focado em aplicações que demandam baixo consumo de VRAM e alta eficiência, como robótica embarcada, dispositivos IoT e jogos táticos.
Destaques técnicos e desempenho
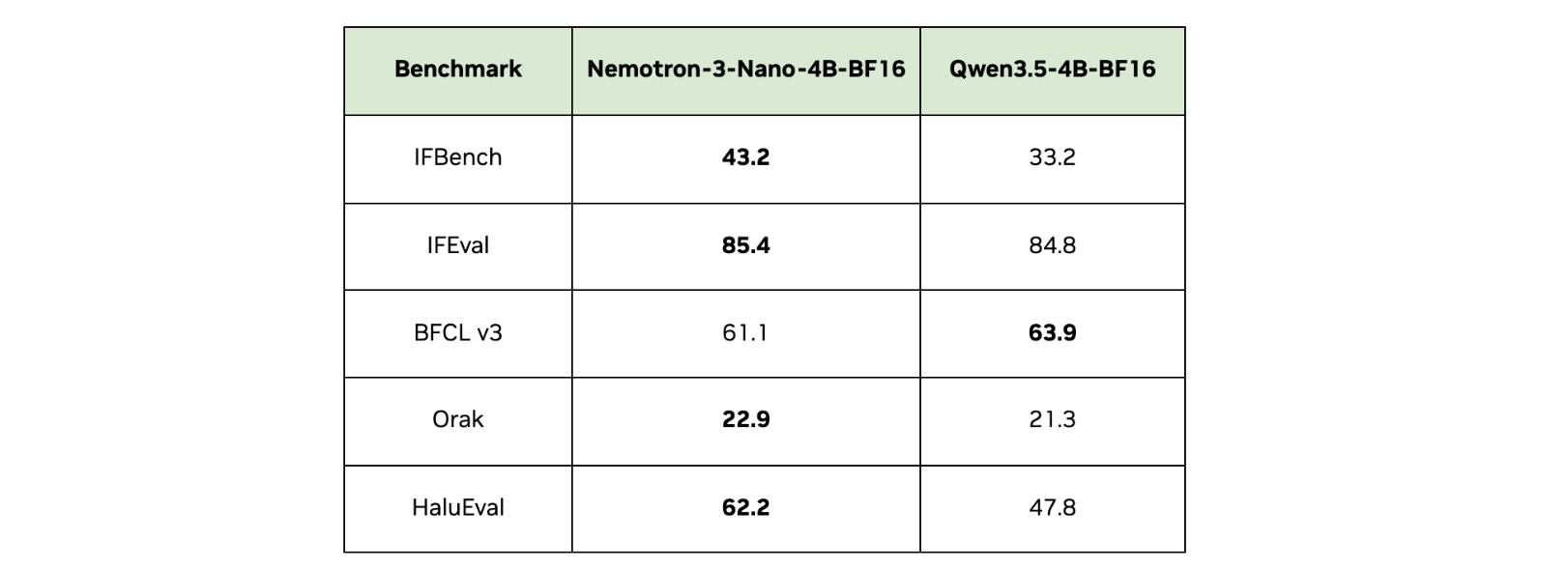
- Precisão de ponta: O modelo atinge o estado da arte em sua categoria para tarefas de seguimento de instruções (IFBench, IFEval) e inteligência para jogos (avaliado em títulos como Super Mario, Darkest Dungeon e Stardew Valley).
- Eficiência de memória: Apresenta a menor pegada de VRAM em sua classe, tanto em configurações de baixa quanto de alta complexidade.
- Baixa latência: Registra o menor tempo para o primeiro token (TTFT) em cenários de alta carga computacional.
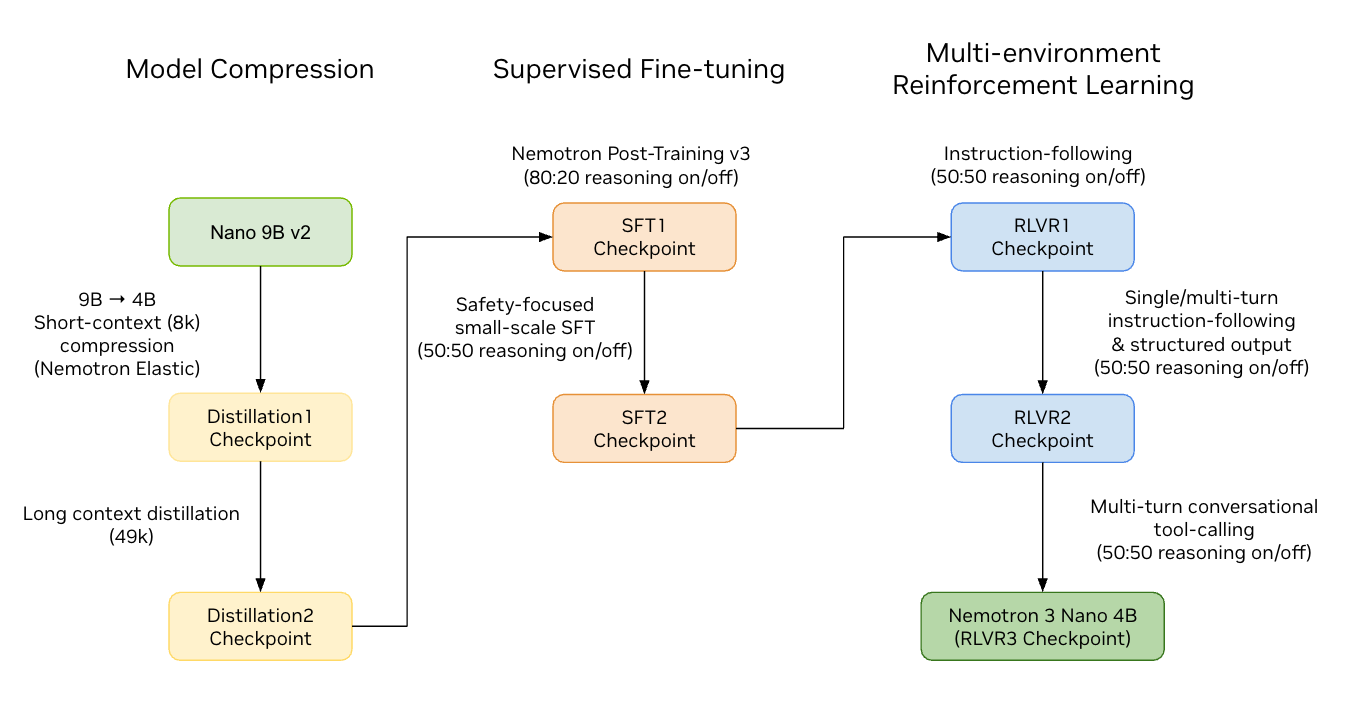
- Redução de tamanho com Nemotron Elastic: O modelo foi comprimido de 9 bilhões para 4 bilhões de parâmetros por meio de uma técnica avançada de pruning e distilação, que mantém a qualidade e o raciocínio híbrido do modelo original.
Processo de desenvolvimento e otimizações
O Nemotron 3 Nano 4B foi criado a partir do Nemotron Nano 9B v2, utilizando o framework Nemotron Elastic. Esse processo envolve:
- Pruning estruturado: Um roteador treinado decide automaticamente quais componentes do modelo reduzir — incluindo cabeças de atenção, dimensão de embedding, canais intermediários e número de camadas.
- Distilação em duas etapas: Para recuperar a precisão após a compressão, o modelo passa por treinamento com janelas de contexto curtas (8K tokens) e longas (49K tokens), totalizando mais de 200 bilhões de tokens.
- Fine-tuning supervisionado: Treinamentos adicionais focados em raciocínio, segurança e instruções específicas, utilizando o Megatron-LM.
- Reforço com aprendizado por múltiplos ambientes: Pipeline de aprendizagem por reforço em três estágios, incluindo ambientes NeMo-Gym para instruções e saídas estruturadas, além de multi-turnos para uso de ferramentas conversacionais.
Quantização para edge devices
Para maximizar a eficiência em dispositivos de borda, o modelo está disponível em versões quantizadas:
- FP8: Aplicada por meio de Post-Training Quantization utilizando a biblioteca ModelOpt, com estratégia seletiva para preservar camadas críticas em BF16. Essa versão oferece até 1,8x melhoria em latência e throughput em plataformas DGX Spark e Jetson Thor.
- Q4_K_M GGUF: Quantização de 4 bits compatível com Llama.cpp, ideal para Jetson Orin Nano 8GB, alcançando até o dobro da taxa de tokens por segundo comparado ao Nemotron Nano 9B v2.
Como acessar e experimentar o Nemotron 3 Nano 4B
O Nemotron 3 Nano 4B está disponível para download gratuito em diversos formatos compatíveis com motores de inferência como Transformers, vLLM, TRT-LLM e Llama.cpp. Para começar, acesse os seguintes repositórios na Hugging Face:
Para usuários da plataforma Jetson, há instruções detalhadas e comandos prontos para uso na página do Jetson AI Lab. Além disso, o SDK NVIDIA In-Game Inferencing (NVIGI) pode acelerar a performance em cenários que combinam inferência com cargas gráficas intensas.
Impacto prático para desenvolvedores e empresas
Com o Nemotron 3 Nano 4B, a NVIDIA e a Hugging Face abrem caminho para a adoção de modelos de linguagem avançados em dispositivos locais, sem depender exclusivamente da nuvem. Isso significa respostas mais rápidas, maior controle sobre os dados e redução dos custos operacionais. O modelo é especialmente indicado para aplicações em robótica, jogos, assistentes virtuais e sistemas embarcados que necessitam de inteligência artificial eficiente e confiável.