Nemotron OCR v2: Novo Modelo Multilíngue de OCR Rápido e Preciso com Dados Sintéticos

Nemotron OCR v2: inovação em OCR multilíngue com dados sintéticos
A NVIDIA, em parceria com a Hugging Face, lançou o Nemotron OCR v2, um modelo de reconhecimento óptico de caracteres (OCR) multilíngue que combina alta velocidade e precisão, treinado majoritariamente com dados sintéticos. O modelo é capaz de processar documentos em seis idiomas — inglês, japonês, coreano, russo, chinês simplificado e chinês tradicional — mantendo desempenho superior em relação a soluções especializadas por idioma.
O que diferencia o Nemotron OCR v2?
O principal desafio para modelos OCR multilíngues é a escassez de dados anotados com qualidade e em escala para diversas línguas. A equipe da NVIDIA identificou que o gargalo não está na arquitetura, mas sim na disponibilidade de dados. Para superar isso, foi adotada uma pipeline de geração de dados sintéticos, que combina textos reais extraídos do corpus mOSCAR com uma renderização avançada baseada no SynthDoG, adaptada para anotações detalhadas em níveis de palavra, linha e parágrafo, além de informações hierárquicas de ordem de leitura.
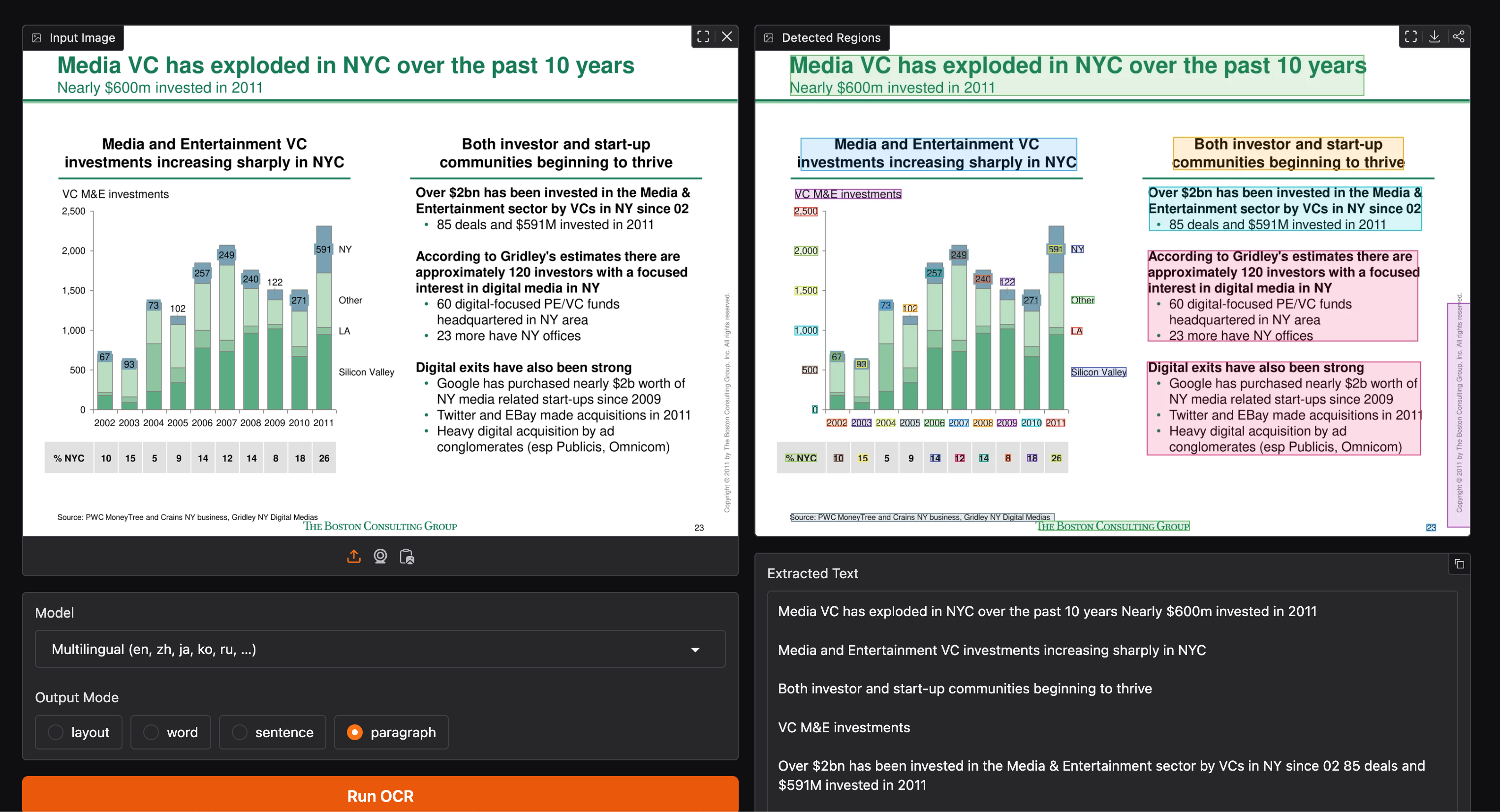
Pipeline de dados sintéticos
- Fonte textual: mOSCAR, um grande corpus multilíngue com 163 idiomas, que oferece textos realistas em vocabulário e estrutura para cada língua.
- Renderização: versão modificada do SynthDoG, que produz imagens documentais com múltiplos layouts, incluindo colunas, tabelas, texto vertical e estilos variados.
- Anotações detalhadas: bounding boxes precisas para palavra, linha e parágrafo, além de grafos relacionais que indicam a ordem lógica de leitura, essencial para documentos complexos.
- Variedade de fontes: entre 165 e 1.258 fontes open source por idioma, incluindo Google Fonts e Noto.
- Augmentações: efeitos visuais como sombras, borrões, distorções e ruídos para melhorar a robustez do modelo.
Arquitetura eficiente e unificada
Nemotron OCR v2 utiliza uma arquitetura baseada no design FOTS (Fast Oriented Text Spotting), que integra detecção e reconhecimento em uma única rede com backbone convolucional compartilhado (RegNetX-8GF). Essa abordagem permite que a imagem seja processada uma única vez para gerar mapas de características reutilizados por todos os componentes:
- Detector de texto: localiza regiões de texto na imagem.
- Reconhecedor: decodifica o texto em regiões detectadas usando um Transformer compacto.
- Modelo relacional: analisa as relações entre regiões para organizar a ordem de leitura e estrutura do documento.
Essa reutilização reduz o processamento redundante, garantindo alta velocidade: até 34,7 páginas por segundo em uma GPU A100.
Resultados e desempenho prático
O treinamento com 12 milhões de imagens sintéticas e cerca de 680 mil imagens reais resultou em melhorias expressivas na Normalized Edit Distance (NED) para todos os idiomas testados, com valores próximos a zero em benchmarks sintéticos (SynthDoG) e desempenho competitivo em cenários reais (OmniDocBench).

Comparado a modelos especializados por idioma, Nemotron OCR v2 multilíngue se destaca por:
- Reconhecer cinco idiomas simultaneamente sem necessidade de seleção prévia.
- Manter ou superar a precisão dos modelos especializados.
- Oferecer velocidade até 28 vezes maior que concorrentes como PaddleOCR v5.
Para quem é indicado e como acessar
Nemotron OCR v2 é ideal para empresas e desenvolvedores que precisam de um OCR multilíngue rápido e robusto, aplicável em processamento de documentos, automação de fluxos de trabalho, análise de formulários e digitalização em larga escala. O modelo está disponível gratuitamente para uso comercial sob a NVIDIA Open Model License, e o dataset sintético sob licença CC-BY-4.0.
Você pode experimentar o modelo diretamente no navegador através da demonstração online do Nemotron OCR v2. Para integrar em seus projetos, acesse o repositório oficial em nvidia/nemotron-ocr-v2 na Hugging Face.
O dataset sintético também está disponível para download em nvidia/OCR-Synthetic-Multilingual-v1. Para criar sua conta e ter acesso à plataforma, visite Hugging Face Sign Up.