Novos Blocos de Construção AWS para Treinamento e Inferência de Foundation Models

Infraestrutura de Computação, Rede e Armazenamento para Foundation Models na AWS
A AWS lançou uma arquitetura robusta de blocos de construção que visa otimizar o treinamento e a inferência de foundation models, aproveitando recursos avançados de computação acelerada, redes de alta largura de banda e armazenamento distribuído escalável. Essa infraestrutura é composta principalmente por instâncias EC2 aceleradas com GPUs NVIDIA de última geração, incluindo as famílias P5, P6 e variantes UltraServer, que oferecem desde 1 até 72 GPUs Blackwell com grandes capacidades de memória HBM3e e interconexões NVLink e EFA para comunicação eficiente.
As instâncias P5 trazem GPUs H100 e H200, com até 8 GPUs por nó, enquanto a família P6 introduz a arquitetura Blackwell B200 e B300, com até 288 GB de memória HBM por GPU. A comunicação entre GPUs dentro do nó é feita via NVLink/NVSwitch, garantindo baixa latência e alta largura de banda, enquanto a comunicação entre nós é suportada pelo Elastic Fabric Adapter (EFA), que utiliza o protocolo Scalable Reliable Datagram (SRD) para reduzir a latência e aumentar o throughput em treinamentos distribuídos.
Quanto ao armazenamento, a AWS oferece uma hierarquia de dados que inclui armazenamento local NVMe SSD para dados "quentes", o sistema de arquivos distribuído Lustre via Amazon FSx para acesso compartilhado de alta performance e Amazon S3 para persistência durável, com integração facilitada para carregamento preguiçoso de datasets e exportação automática de checkpoints.
Orquestração de Recursos com Slurm e Kubernetes
Gerenciar centenas ou milhares de aceleradores simultaneamente requer orquestração sofisticada. A AWS integra dois sistemas principais para esse fim: Slurm e Kubernetes. Slurm é amplamente utilizado em computação de alto desempenho e oferece agendamento de jobs em nível de cluster, garantindo alocação atômica e balanceamento de carga com suporte a políticas de prioridade, localização topológica e controle de recursos específicos como GPUs.
A AWS oferece ferramentas como AWS ParallelCluster para facilitar a implantação de clusters Slurm, além do AWS Parallel Computing Service (PCS) e o Amazon SageMaker HyperPod, que adiciona funcionalidades como monitoramento contínuo de nós e retomada automática de jobs, essenciais para treinamentos distribuídos em larga escala.
Por sua vez, o Kubernetes oferece uma abordagem declarativa via APIs para orquestração, muito usada para implantação de modelos, mas com limitações para treinamentos distribuídos que envolvem sincronização rígida. Para superar essas limitações, projetos como Kueue implementam controle de admissão de jobs em nível de grupo, garantindo agendamento eficiente e uso justo de recursos em ambientes multi-tenant.
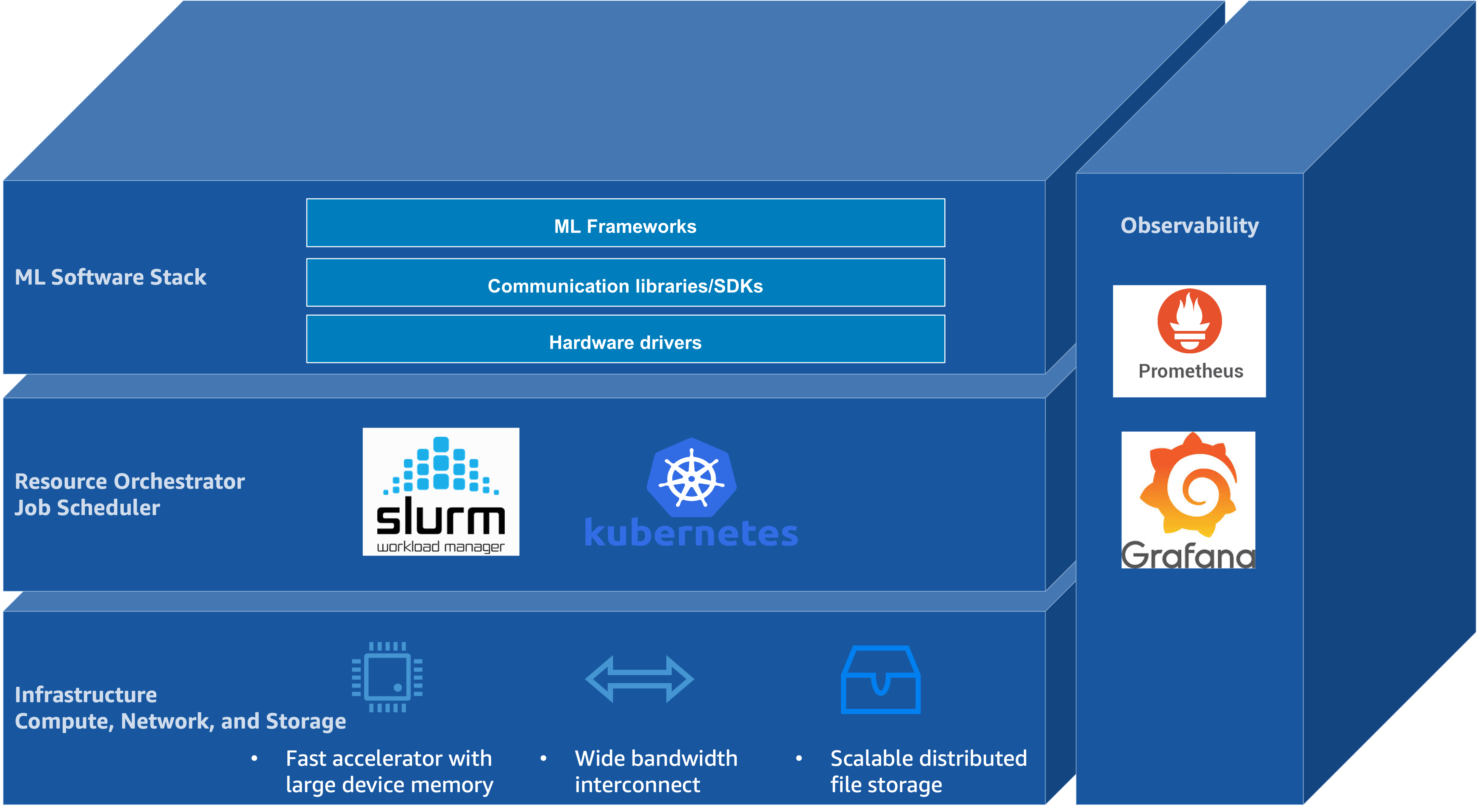
Stack de Software e Observabilidade para Ciclo de Vida de Foundation Models
A pilha de software para foundation models na AWS combina frameworks populares como PyTorch e JAX para desenvolvimento e treinamento distribuído, com sistemas de monitoramento como Amazon Managed Service for Prometheus (AMP) e Amazon Managed Grafana (AMG) para coleta e visualização de métricas. Essa combinação permite observabilidade em todos os níveis — hardware, orquestração e aplicação — facilitando a detecção rápida de gargalos e problemas de performance.
Quem Pode Usar e Como Acessar
Essa infraestrutura é destinada a engenheiros e pesquisadores de machine learning que trabalham com foundation models em larga escala, seja para pré-treinamento, fine-tuning ou inferência. As instâncias EC2 aceleradas estão disponíveis publicamente na AWS, com diferentes configurações para atender desde workloads menores até ultra clusters com milhares de GPUs.
Para acessar, basta criar uma conta AWS e provisionar as instâncias EC2 desejadas via console, CLI ou APIs. Para orquestração, pode-se utilizar AWS ParallelCluster para Slurm, Amazon SageMaker para HyperPod, ou configurar clusters Kubernetes com suporte a projetos como Kueue para gerenciamento de jobs. A integração com serviços gerenciados de observabilidade e armazenamento também está disponível via AWS Management Console.
Impacto Prático para o Usuário
Com essa nova arquitetura de blocos de construção, a AWS oferece uma solução integrada e escalável para os desafios complexos do treinamento e inferência de foundation models, permitindo a redução de latência, aumento da eficiência computacional e melhor uso dos recursos distribuídos. Isso facilita o desenvolvimento de modelos maiores e mais complexos, acelera ciclos de experimentação e contribui para resultados mais robustos em aplicações reais de IA.
Links úteis
Leia também

Hugging Face lança simulação econômica com cinco modelos de IA para entender mercados emergentes
8 de junho de 2026
Projeto Amazing Digital Dentures: os desafios de criar aventuras digitais com IA
8 de junho de 2026
Her: a detetive que analisa suas sessões de Claude Code com inteligência e segurança
7 de junho de 2026