NVIDIA e Hugging Face lançam pipeline para criação rápida de modelos de embedding específicos de domínio

A NVIDIA, em parceria com a Hugging Face, lançou uma solução inovadora que permite a criação de modelos de embedding específicos para domínios particulares em menos de um dia e com apenas uma GPU. Essa novidade é especialmente útil para empresas e desenvolvedores que precisam de sistemas de recuperação de informação (RAG) capazes de entender nuances específicas de seus dados, como contratos, logs industriais, fórmulas químicas proprietárias ou taxonomias internas.
O que foi lançado e para quem serve
O novo pipeline de fine-tuning de embeddings transforma um modelo genérico, como o Llama-Nemotron-Embed-1B-v2, em um modelo especializado que entende os detalhes do seu domínio. Isso é fundamental porque modelos genéricos, treinados para entender a internet como um todo, não capturam as sutilezas necessárias para tarefas específicas. A solução é ideal para equipes que desenvolvem sistemas de busca semântica, recuperação de documentos e aplicações que exigem alta precisão na compreensão contextual.
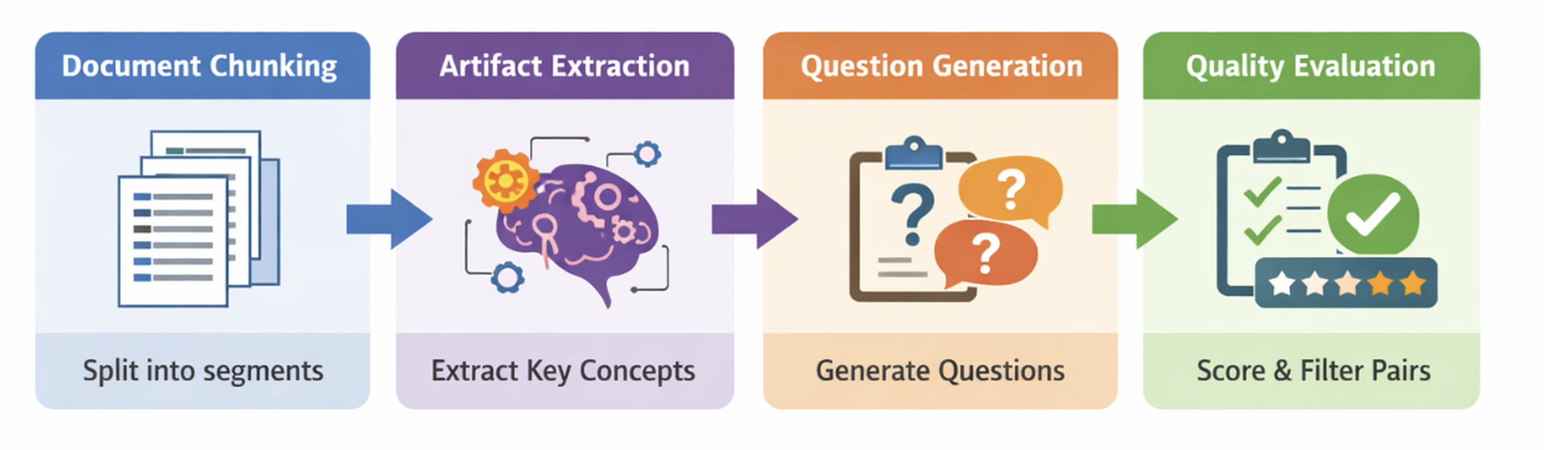
Como funciona o processo de fine-tuning
- Geração automática de dados de treinamento: Utilizando o NeMo Data Designer e um LLM da NVIDIA (nvidia/nemotron-3-nano-30b-a3b), o pipeline lê documentos do seu domínio e gera pares de pergunta-resposta sintéticos de alta qualidade, sem necessidade de rotulagem manual.
- Mineração de "hard negatives": Para melhorar a capacidade do modelo em distinguir documentos muito semelhantes, o pipeline identifica passagens que parecem relevantes, mas não são a resposta correta, tornando o treinamento mais robusto.
- Incorporação de perguntas multi-hop: Perguntas que exigem a conexão de informações de múltiplos documentos são geradas para treinar o modelo a recuperar contextos mais complexos e relevantes.
- Fine-tuning com aprendizado contrastivo: O modelo é ajustado usando uma arquitetura biencoder e técnicas de aprendizado contrastivo, com hiperparâmetros otimizados para garantir qualidade e estabilidade no treinamento, mesmo com conjuntos de dados pequenos.
- Avaliação padronizada: O desempenho é medido com a framework BEIR, usando métricas como nDCG, Recall, Precision e MAP, garantindo melhorias significativas na recuperação.
- Exportação e implantação: O modelo final é convertido para ONNX e TensorRT para acelerar a inferência, e pode ser implantado via NVIDIA NIM, oferecendo uma API compatível com OpenAI para integração direta em pipelines existentes.
Disponibilidade e requisitos técnicos
Para utilizar o pipeline, é necessário ter:
- Um diretório com documentos do seu domínio em formatos texto (.txt, .md, etc.)
- Uma GPU NVIDIA Ampere ou superior com pelo menos 80GB de memória (testado em A100 e H100)
- Uma chave API NVIDIA válida, que pode ser obtida gratuitamente em build.nvidia.com
O pipeline e os conjuntos de dados sintéticos estão disponíveis como projetos open source no GitHub e integrados à Hugging Face, facilitando o acesso e a experimentação.
Impacto prático e resultados reais
Empresas como a Atlassian já aplicaram essa receita para treinar modelos em seus dados públicos do Jira, obtendo um aumento de 26,7% no Recall@60 — ou seja, o modelo recupera documentos relevantes com muito mais precisão dentro dos primeiros 60 resultados. Isso representa uma melhora direta na experiência de milhões de usuários que dependem da busca eficiente em sistemas corporativos.
Como começar: links úteis e documentação
- Guia de setup do pipeline
- NeMo Automodel (treinamento de embedding)
- NeMo Data Designer (geração de dados sintéticos)
- NeMo Export-Deploy (exportação e deployment)
- Repositório Nemotron
- BEIR (avaliação de recuperação de informação)
- Dataset sintético NVIDIA
- Crie sua conta na Hugging Face para começar
Em resumo, essa solução democratiza e acelera o desenvolvimento de modelos de embedding especializados, reduzindo o tempo, custo e complexidade técnica envolvidos. Com ela, organizações podem melhorar significativamente a qualidade de suas buscas e sistemas de recuperação de informação, trazendo ganhos concretos para usuários finais e negócios.
Leia também

Hugging Face lança simulação econômica com cinco modelos de IA para entender mercados emergentes
8 de junho de 2026
Projeto Amazing Digital Dentures: os desafios de criar aventuras digitais com IA
8 de junho de 2026
Her: a detetive que analisa suas sessões de Claude Code com inteligência e segurança
7 de junho de 2026