NVIDIA Lança Dataset Multilíngue com 6 Milhões de Exemplos para Avanços em Raciocínio de IA

Nos últimos anos, a inteligência artificial (IA) tem avançado rapidamente, especialmente em tarefas que envolvem raciocínio complexo e compreensão de múltiplas línguas. Pensando nisso, a NVIDIA acaba de lançar um dataset inovador com 6 milhões de exemplos multilíngues, que promete revolucionar a forma como modelos de IA aprendem e aplicam raciocínio em diferentes idiomas.
O que é o novo dataset da NVIDIA?
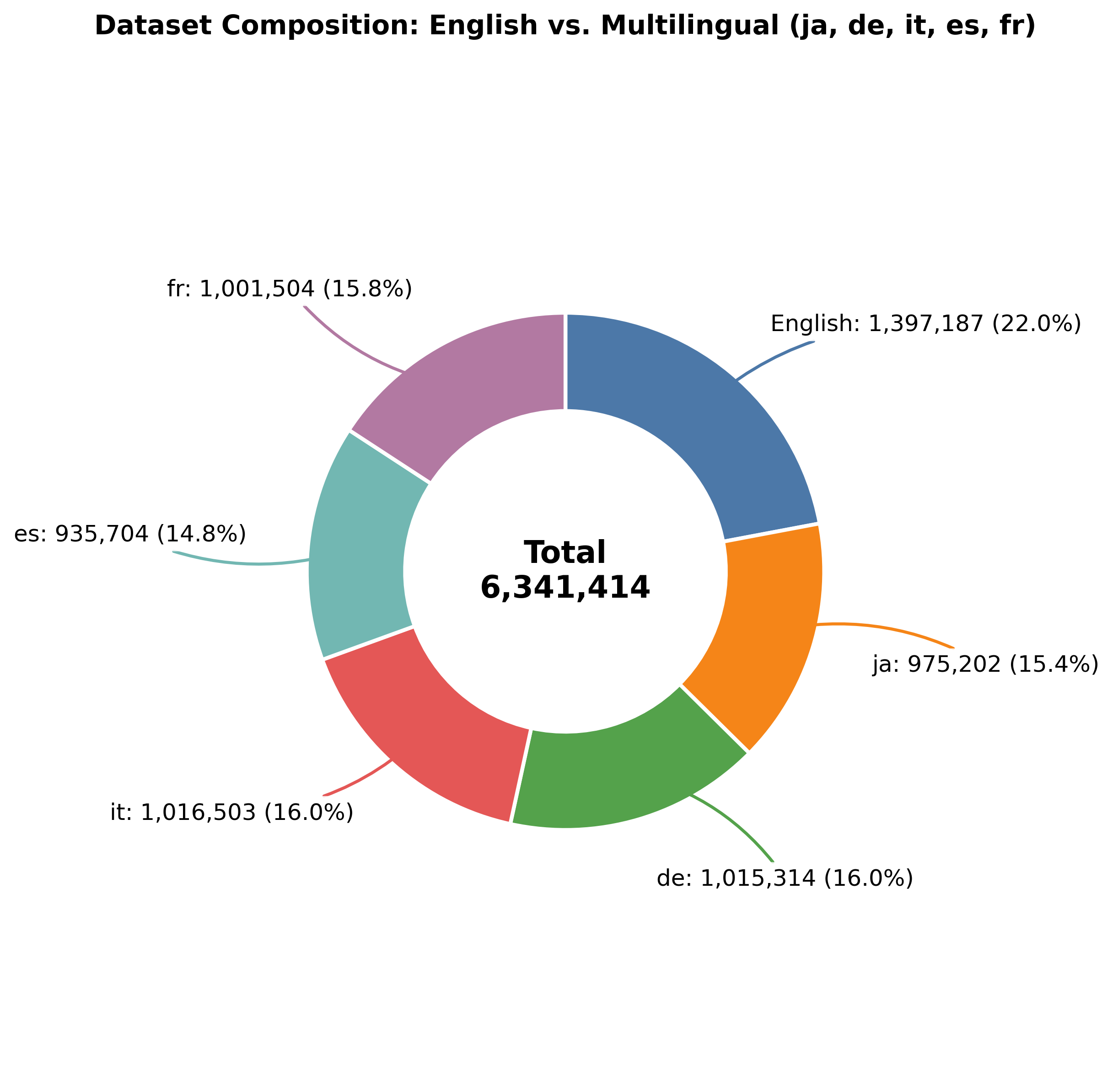
O dataset lançado pela NVIDIA é uma coleção massiva de dados projetada para treinar e avaliar modelos de IA em tarefas de raciocínio que envolvem múltiplas línguas. Com 6 milhões de exemplos, ele cobre uma ampla variedade de cenários e contextos, permitindo que os algoritmos desenvolvam habilidades mais robustas e generalizáveis.
Características principais
- Multilíngue: O dataset inclui dados em diversos idiomas, ampliando o alcance dos modelos para além do inglês.
- Raciocínio complexo: Os exemplos envolvem tarefas que exigem inferência, dedução e análise lógica.
- Escalabilidade: Com milhões de exemplos, o conjunto é ideal para treinar modelos de grande escala, como transformadores e redes neurais profundas.
Por que esse lançamento é importante?
O avanço da IA depende fortemente da qualidade e diversidade dos dados utilizados para treinamento. Até então, muitos datasets focavam em uma única língua ou em tarefas simples, limitando o potencial dos modelos. Com esse novo recurso da NVIDIA, pesquisadores e desenvolvedores poderão:
- Melhorar a compreensão multilíngue: Modelos poderão aprender a interpretar e raciocinar em diferentes idiomas, tornando a IA mais acessível globalmente.
- Desenvolver aplicações mais inteligentes: Desde assistentes virtuais até sistemas de recomendação, a capacidade de raciocinar aumenta a qualidade das respostas e decisões automatizadas.
- Avançar em pesquisas: O dataset oferece uma base sólida para novos estudos em raciocínio automático e processamento de linguagem natural (PLN).
Impactos no mercado e na pesquisa
Com a crescente demanda por soluções de IA que funcionem em múltiplos idiomas, o dataset da NVIDIA chega em um momento estratégico. Empresas que atuam globalmente poderão treinar modelos mais precisos e eficientes para seus públicos diversificados. Além disso, a comunidade acadêmica ganha uma ferramenta poderosa para explorar novos algoritmos e técnicas.
Desafios e oportunidades
Embora o dataset seja um avanço significativo, ainda existem desafios a serem superados, como a necessidade de computação robusta para treinar modelos em larga escala e a garantia da qualidade e representatividade dos dados em todas as línguas incluídas. Por outro lado, essas dificuldades incentivam a inovação e a colaboração entre pesquisadores, desenvolvedores e instituições.
Conclusão
A NVIDIA, ao lançar esse dataset multilíngue com 6 milhões de exemplos focados em raciocínio, abre portas para uma nova era na inteligência artificial. Modelos mais inteligentes, capazes de compreender e raciocinar em diversos idiomas, estão mais próximos da realidade. Para profissionais e entusiastas de IA, essa é uma oportunidade imperdível para explorar e contribuir com o futuro da tecnologia.
Fique ligado no blog "IA em Foco" para mais novidades e análises sobre os avanços em inteligência artificial.