NVIDIA Nemotron 3 Nano Omni: Inteligência Multimodal para Documentos, Áudio e Vídeo em Contextos Longos

A NVIDIA lançou o Nemotron 3 Nano Omni, um modelo de inteligência artificial multimodal projetado para entender e processar documentos complexos, áudio e vídeo com longos contextos. Esta nova geração amplia a linha Nemotron, que antes focava em visão e linguagem, para integrar texto, imagens, vídeos e áudio em uma única arquitetura avançada.
O que é o Nemotron 3 Nano Omni?
Trata-se de um modelo omni-modal desenvolvido para aplicações reais que demandam análise detalhada de documentos, reconhecimento automático de fala, compreensão de conteúdos audiovisuais extensos, uso autônomo em ambientes computacionais e raciocínio multimodal geral. Ele oferece alta precisão em benchmarks de inteligência documental, como OCRBenchV2 e MMlongbench-Doc, além de liderar rankings em entendimento de vídeo e áudio, como os benchmarks WorldSense e DailyOmni. No reconhecimento de voz, destacou-se no VoiceBench e é o modelo aberto mais eficiente em termos de custo para vídeo no MediaPerf.
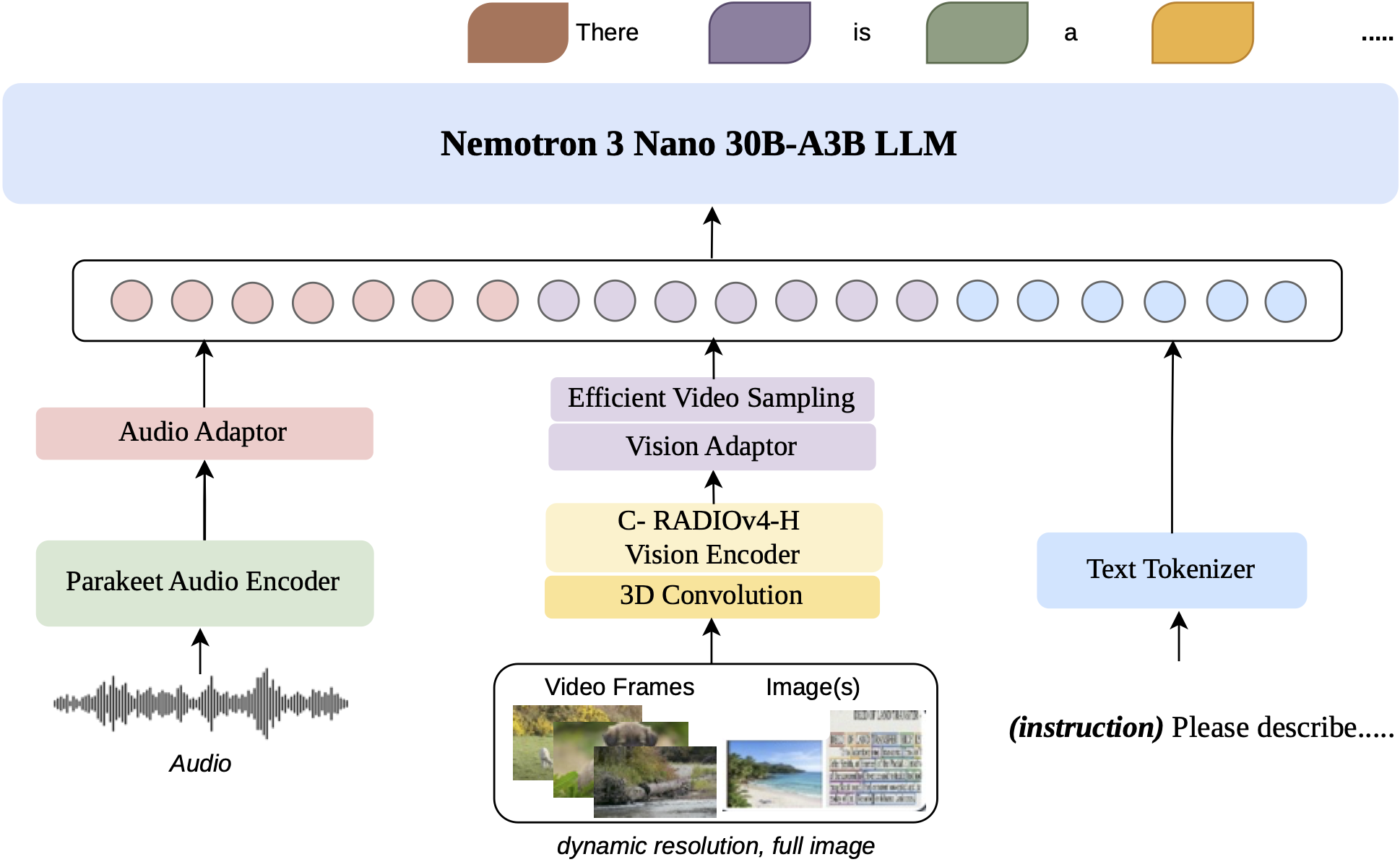
Arquitetura e inovações técnicas
O Nemotron 3 Nano Omni combina um backbone híbrido Mamba-Transformer Mixture-of-Experts (MoE) com encoders especializados para visão (C-RADIOv4-H) e áudio (Parakeet-TDT-0.6B-v2). Essa arquitetura foi projetada para preservar detalhes visuais finos, incorporar compreensão nativa de áudio e escalar para contextos multimodais muito longos, essenciais para documentos densos, vídeos e raciocínios que envolvem múltiplas modalidades.
- Backbone híbrido: intercalando 23 camadas Mamba para processamento eficiente de contexto longo, 23 camadas MoE com 128 especialistas e 6 camadas de atenção agrupada para manter interação global forte.
- Resolução dinâmica: processamento de imagens com resolução variável, de 1.024 a 13.312 patches visuais por imagem, permitindo lidar com documentos complexos, tabelas e layouts de interface gráfica com alta fidelidade.
- Compressão temporal Conv3D para vídeo: fusão de pares de frames em "tubelets" para reduzir tokens e aumentar eficiência no processamento de vídeo.
- EVS (Efficient Video Sampling): técnica que elimina tokens redundantes durante a inferência para melhorar desempenho sem perda de precisão.
- Áudio nativo: o modelo processa áudio diretamente, não apenas transcrições, suportando até 20 minutos de áudio contínuo e contextos de linguagem com mais de 5 horas, fundamental para análises multimodais sincronizadas.
Treinamento e desempenho
O treinamento do Nemotron 3 Nano Omni envolve múltiplas etapas: alinhamento multimodal, extensão de contexto, otimização por preferências e aprendizado por reforço multimodal. A infraestrutura usada inclui clusters NVIDIA H100 e frameworks como Megatron-LM, Transformer Engine e NeMo-RL.
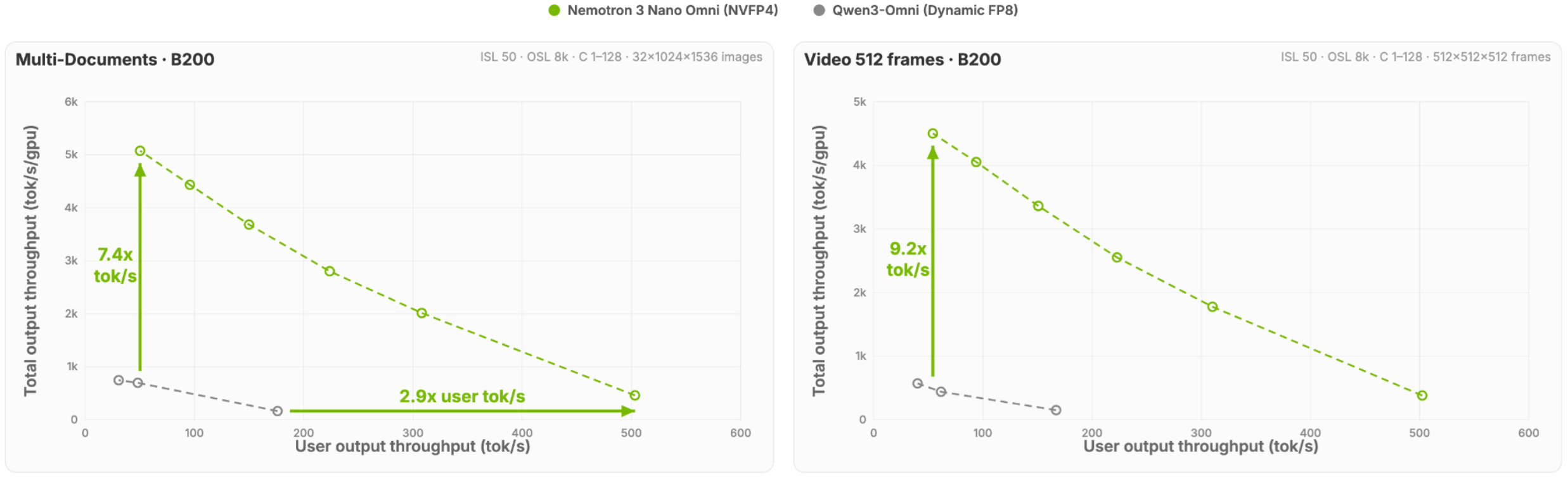
Em termos de desempenho, o modelo oferece até 9 vezes maior throughput e quase 3 vezes mais velocidade em raciocínio single-stream em cenários multimodais, em comparação com alternativas abertas similares.
Casos de uso práticos
- Análise de documentos reais: capaz de interpretar documentos extensos e complexos, como contratos, relatórios financeiros com mais de 100 páginas, manuais técnicos, formulários e pacotes de conformidade, entendendo layout, tabelas, fórmulas e referências cruzadas.
- Reconhecimento automático de fala: transcrição robusta em ambientes com múltiplos falantes, sotaques variados e ruídos de fundo, integrada a fluxos que combinam áudio com outras modalidades para sumarização e perguntas e respostas.
- Compreensão de áudio e vídeo longos: análise conjunta de imagens e áudio em vídeos corporativos, tutoriais, reuniões, demonstrações de produtos e arquivos de vídeo extensos.
- Uso autônomo em interfaces gráficas: interpretação de capturas de tela, monitoramento do estado da interface e auxílio em seleção de ações ou automação de fluxos de trabalho.
- Raciocínio multimodal geral: síntese e análise complexa envolvendo múltiplas modalidades e evidências estruturadas para respostas coerentes e fundamentadas.
Exemplos de fluxos de trabalho
Entre os exemplos demonstrados estão:
- Análise de documentos multi-página: extração e cálculo de métricas financeiras de relatórios com mais de 100 páginas, combinando leitura de tabelas, gráficos e textos.
- Entendimento conjunto de vídeo e áudio: responder perguntas detalhadas sobre cenas específicas e narração, como identificar estruturas em chamas e descrever visuais associados a relatos.
- Uso agentivo em computação: integração com sistemas que interpretam instruções e capturas de tela para executar tarefas automatizadas em ambientes gráficos.
Disponibilidade e recursos para desenvolvedores
Os checkpoints do modelo estão disponíveis para download no HuggingFace nos formatos BF16, FP8 e NVFP4. A NVIDIA também disponibiliza documentação completa, receitas de pipeline, repositórios de código e relatórios detalhados para quem deseja explorar a arquitetura, os dados de treinamento e os benchmarks do Nemotron 3 Nano Omni.