O Futuro da Geração de Vídeos com Modelos Abertos na Plataforma Diffusers

A inteligência artificial tem revolucionado diversas áreas da tecnologia, e a geração de vídeos não fica atrás. Recentemente, a HuggingFace, uma das maiores plataformas de modelos de IA, tem avançado significativamente no desenvolvimento e disponibilização de modelos abertos para geração de vídeos utilizando a biblioteca Diffusers. Neste artigo, vamos explorar o estado atual desses modelos, seus desafios, aplicações e o que esperar para o futuro dessa tecnologia promissora.
Introdução à Geração de Vídeos por IA
Enquanto a geração de imagens por IA já alcançou níveis impressionantes de qualidade e realismo, a geração de vídeos ainda enfrenta desafios técnicos mais complexos. Isso ocorre porque, além da qualidade visual, é necessário garantir a coerência temporal entre os frames para que o vídeo tenha fluidez e faça sentido para o espectador.
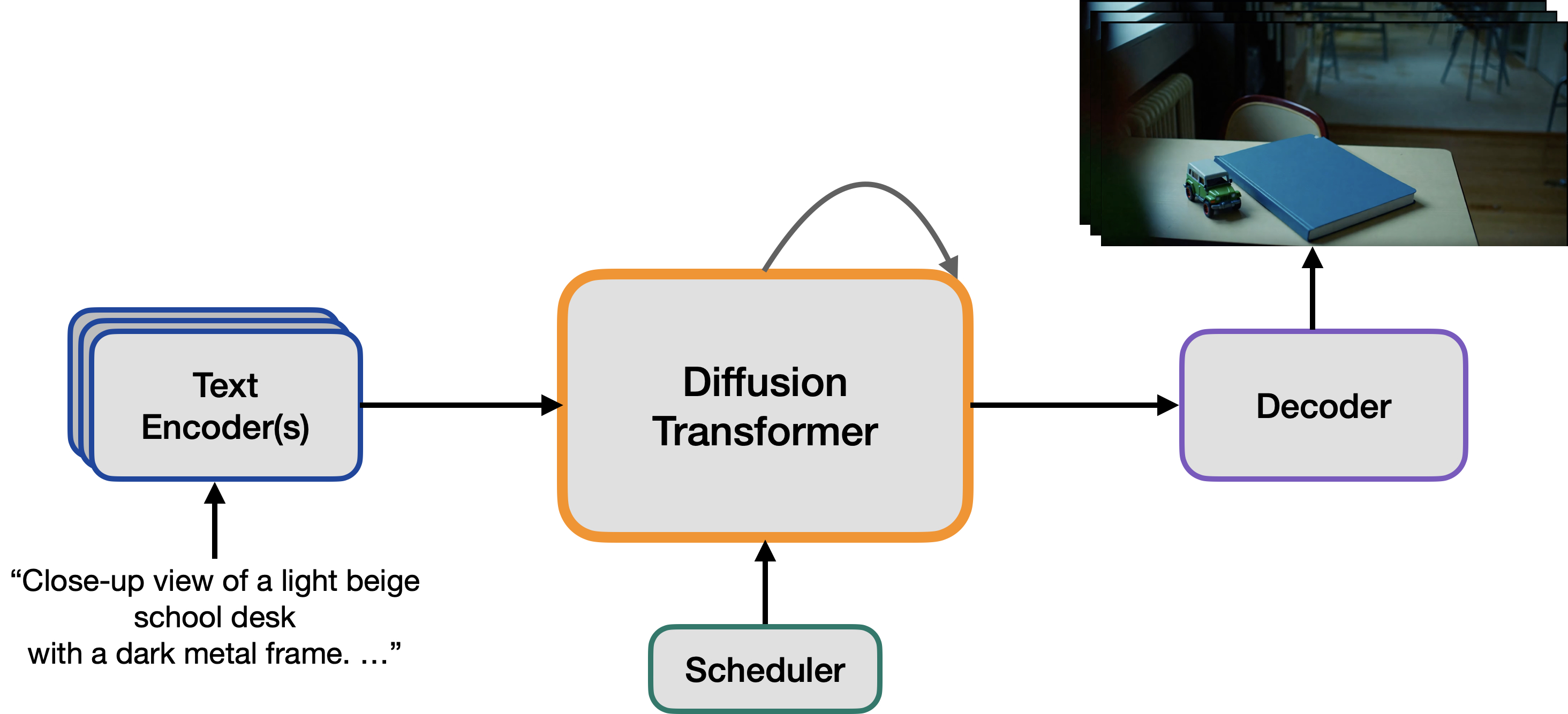
A biblioteca Diffusers, desenvolvida pela HuggingFace, tem sido um marco na democratização do acesso a modelos de difusão para geração de conteúdos visuais. Inicialmente focada em imagens, a plataforma tem expandido seu alcance para incluir modelos capazes de gerar vídeos, abrindo portas para pesquisadores, desenvolvedores e entusiastas experimentarem e criarem vídeos de forma automatizada.
O Estado Atual dos Modelos Abertos para Geração de Vídeos
Atualmente, os modelos de geração de vídeos disponíveis na Diffusers ainda estão em estágio inicial, mas já demonstram resultados promissores. Alguns pontos importantes sobre o cenário atual incluem:
- Modelos baseados em difusão: Utilizam processos iterativos para refinar a geração dos frames, garantindo maior qualidade e coerência entre eles.
- Coerência temporal: Um dos principais desafios é manter a continuidade entre os frames para evitar saltos ou inconsistências no vídeo final.
- Capacidade computacional: A geração de vídeos requer muito mais processamento e memória do que imagens estáticas, o que limita o uso em dispositivos com recursos limitados.
- Open source e colaboração: A comunidade em torno da Diffusers tem contribuído com melhorias constantes, criando modelos cada vez mais eficientes e acessíveis.
Principais Modelos e Tecnologias
Dentre os modelos disponíveis, destacam-se aqueles que combinam a geração de imagens com técnicas de aprendizado temporal para criar vídeos curtos e coerentes. Alguns exemplos incluem:
- Modelos de difusão condicionados por texto: Permitem a geração de vídeos a partir de descrições textuais, facilitando a criação de conteúdos personalizados.
- Modelos híbridos: Integram redes neurais convolucionais e recorrentes para melhorar a fluidez temporal.
Desafios e Limitações
Apesar dos avanços, ainda existem barreiras a serem superadas para que a geração de vídeos por IA se torne amplamente utilizada e confiável:

- Qualidade e resolução: Vídeos gerados ainda apresentam limitações em resolução e detalhes finos, especialmente em cenas complexas.
- Tempo de geração: O processo pode ser demorado, exigindo otimizações para uso prático.
- Controle criativo: Ajustar parâmetros para obter resultados específicos ainda requer conhecimento técnico avançado.
- Ética e uso responsável: A facilidade de criação de vídeos realistas levanta questões sobre desinformação e direitos autorais.
Aplicações Promissoras
Mesmo com as limitações atuais, as possibilidades de aplicação são vastas e impactantes:
- Produção de conteúdo audiovisual: Criadores podem gerar vídeos rápidos para protótipos, trailers ou material promocional.
- Educação e treinamento: Vídeos personalizados para explicar conceitos complexos de forma visual e dinâmica.
- Entretenimento: Desenvolvimento de animações e cenas para jogos e filmes com menor custo e tempo.
- Pesquisa científica: Visualização de dados e simulações em formato de vídeo gerado automaticamente.
O Futuro da Geração de Vídeos na Diffusers
Com o avanço contínuo da pesquisa e o crescimento da comunidade de código aberto, é esperado que os modelos de geração de vídeos se tornem mais robustos, rápidos e acessíveis. Algumas tendências a serem observadas incluem:
- Integração com outras modalidades: Combinação de áudio, texto e vídeo para experiências multimodais completas.
- Melhorias na coerência temporal: Novas arquiteturas que garantam fluidez e continuidade superiores.
- Otimização para dispositivos móveis: Tornar a geração de vídeos viável em smartphones e tablets.
- Ferramentas amigáveis: Interfaces intuitivas para que usuários sem conhecimento técnico possam criar vídeos com IA.
Conclusão
A geração de vídeos por modelos abertos na plataforma Diffusers representa um avanço significativo no campo da inteligência artificial aplicada ao audiovisual. Embora ainda existam desafios técnicos e éticos a serem enfrentados, o potencial dessa tecnologia para transformar a criação de conteúdo é enorme. A colaboração contínua da comunidade e o desenvolvimento de novas técnicas prometem tornar essa ferramenta cada vez mais poderosa e acessível, abrindo um novo capítulo na produção de vídeos automatizados.
Fique atento às novidades do IA em Foco para acompanhar as últimas tendências e inovações nessa área fascinante!