PipelineRL: Revolucionando o Aprendizado por Reforço com Pipelines Inteligentes

O aprendizado por reforço (RL) é uma das áreas mais promissoras da inteligência artificial, permitindo que agentes aprendam a tomar decisões ótimas em ambientes complexos através de interações contínuas. Recentemente, a HuggingFace lançou o PipelineRL, uma ferramenta inovadora que promete simplificar e acelerar o desenvolvimento de modelos de RL, integrando pipelines inteligentes para facilitar todo o processo.
O que é o PipelineRL?
O PipelineRL é uma solução desenvolvida para unificar e otimizar as etapas do aprendizado por reforço, desde a coleta de dados até o treinamento e a avaliação dos agentes. Inspirado nas pipelines tradicionais de machine learning, ele traz uma abordagem modular e escalável, permitindo que pesquisadores e desenvolvedores criem fluxos de trabalho eficientes e replicáveis.

Principais características do PipelineRL
- Modularidade: Cada etapa do processo de RL é representada como um componente independente, facilitando a personalização e reutilização.
- Integração com ambientes: Suporte nativo para múltiplos ambientes de simulação, incluindo OpenAI Gym e outros frameworks populares.
- Automação: Automatiza tarefas repetitivas como coleta de dados, pré-processamento e avaliação, reduzindo o tempo de desenvolvimento.
- Escalabilidade: Permite execução distribuída e paralelização, essencial para treinar agentes em ambientes complexos.
- Compatibilidade: Fácil integração com bibliotecas de deep learning como PyTorch e TensorFlow.
Por que o PipelineRL é um avanço para o aprendizado por reforço?
Tradicionalmente, o desenvolvimento de agentes de RL exige a implementação manual de diversas etapas, o que pode ser trabalhoso e suscetível a erros. O PipelineRL oferece uma estrutura padronizada que não apenas acelera esse processo, mas também melhora a reprodutibilidade dos experimentos.
Além disso, a capacidade de modularizar o pipeline permite que pesquisadores testem diferentes algoritmos, estratégias de exploração e técnicas de otimização de forma mais ágil. Isso é fundamental para acelerar a inovação e a aplicação prática do RL em setores como robótica, jogos, finanças e saúde.
Como funciona na prática?
Imagine que você deseja treinar um agente para jogar um jogo de tabuleiro complexo. Com o PipelineRL, você pode montar um pipeline que:
- Configura o ambiente do jogo;
- Define a política inicial do agente;
- Executa múltiplas interações para coletar dados;
- Treina o modelo com os dados coletados;
- Avalia o desempenho do agente;
- Reinicia o ciclo para melhorar continuamente o aprendizado.
Todo esse processo pode ser orquestrado de forma automática, com monitoramento e ajustes dinâmicos, permitindo foco maior na experimentação e análise dos resultados.
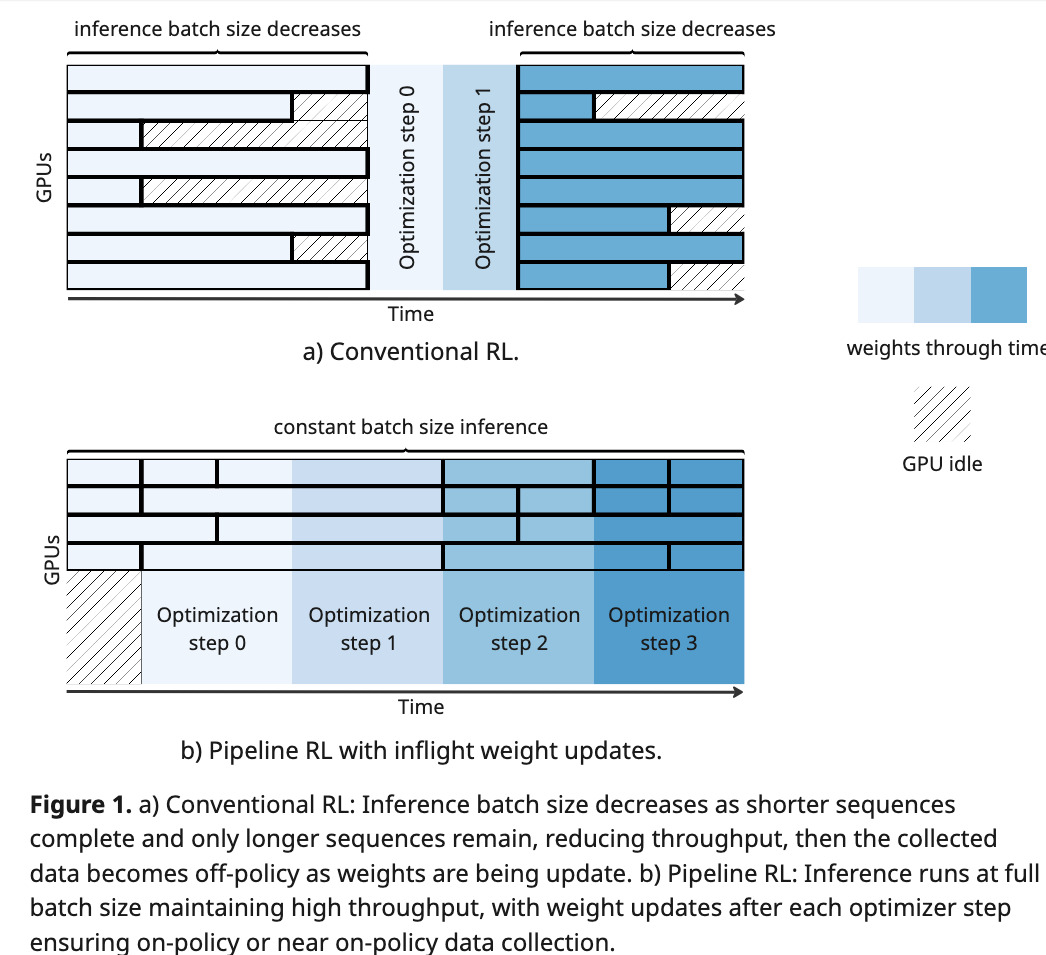
Impacto para a comunidade de IA
Com o PipelineRL, a HuggingFace contribui para democratizar o acesso a ferramentas avançadas de RL. Pesquisadores iniciantes podem começar a explorar o campo com menos barreiras técnicas, enquanto profissionais experientes ganham agilidade para desenvolver soluções mais robustas.
Além disso, a padronização dos pipelines facilita a colaboração entre equipes e a publicação de resultados, promovendo um ambiente mais aberto e transparente para o avanço da inteligência artificial.
Conclusão
O PipelineRL representa um passo significativo na evolução do aprendizado por reforço, trazendo uma abordagem mais estruturada, eficiente e acessível para o desenvolvimento de agentes inteligentes. Ao integrar automação, modularidade e escalabilidade, essa ferramenta da HuggingFace abre novas possibilidades para aplicações práticas e pesquisas inovadoras em IA.
Se você está interessado em explorar o potencial do aprendizado por reforço, vale a pena acompanhar de perto as novidades do PipelineRL e considerar sua adoção em seus projetos.