Protegendo Dados Privados em Grande Escala com Seleção Diferencialmente Privada de Partições

Em um mundo cada vez mais digital, a proteção da privacidade dos usuários tornou-se uma prioridade fundamental para empresas e pesquisadores. Com o crescimento exponencial do volume de dados coletados, garantir que informações sensíveis permaneçam seguras, mesmo durante análises complexas, é um desafio significativo. Recentemente, avanços em técnicas de privacidade diferencial têm oferecido soluções promissoras para este cenário, especialmente no que diz respeito à seleção de partições de dados de forma segura e eficiente.
O que é Privacidade Diferencial e por que ela importa?
A privacidade diferencial é um conceito matemático que garante que a inclusão ou exclusão de um único dado individual em um conjunto não afete significativamente o resultado de uma análise. Isso significa que é praticamente impossível identificar informações pessoais específicas a partir dos dados analisados, mesmo que um invasor tenha acesso ao resultado final.
Essa abordagem é crucial para proteger dados sensíveis em setores como saúde, finanças e tecnologia, onde a exposição inadvertida pode causar danos irreparáveis aos indivíduos. Além disso, a privacidade diferencial permite que organizações compartilhem insights valiosos sem comprometer a segurança dos dados originais.
Desafios na Seleção de Partições em Grandes Conjuntos de Dados
Ao trabalhar com grandes volumes de dados, é comum dividir as informações em partições — subconjuntos que facilitam a análise e o processamento. No entanto, selecionar quais partições incluir em uma análise, preservando a privacidade dos dados, é uma tarefa complexa.
- Escalabilidade: Métodos tradicionais podem não ser eficientes para conjuntos de dados massivos.
- Ruído e precisão: Adicionar ruído para garantir privacidade pode comprometer a qualidade dos resultados.
- Segurança: Garantir que a seleção não exponha informações sensíveis é fundamental.
Por isso, pesquisadores do Google Research desenvolveram um algoritmo inovador de seleção diferencialmente privada de partições que equilibra esses aspectos, permitindo análises seguras e precisas em larga escala.
Como funciona a Seleção Diferencialmente Privada de Partições?
O algoritmo proposto utiliza técnicas avançadas de privacidade diferencial para selecionar automaticamente as partições mais relevantes para análise, enquanto limita a exposição de dados individuais. Ele incorpora um mecanismo que adiciona ruído cuidadosamente calibrado durante o processo de seleção, garantindo que a probabilidade de incluir uma partição não revele informações sensíveis.
Além disso, o método é projetado para ser eficiente em termos computacionais, permitindo sua aplicação em conjuntos de dados com bilhões de registros sem comprometer o desempenho.
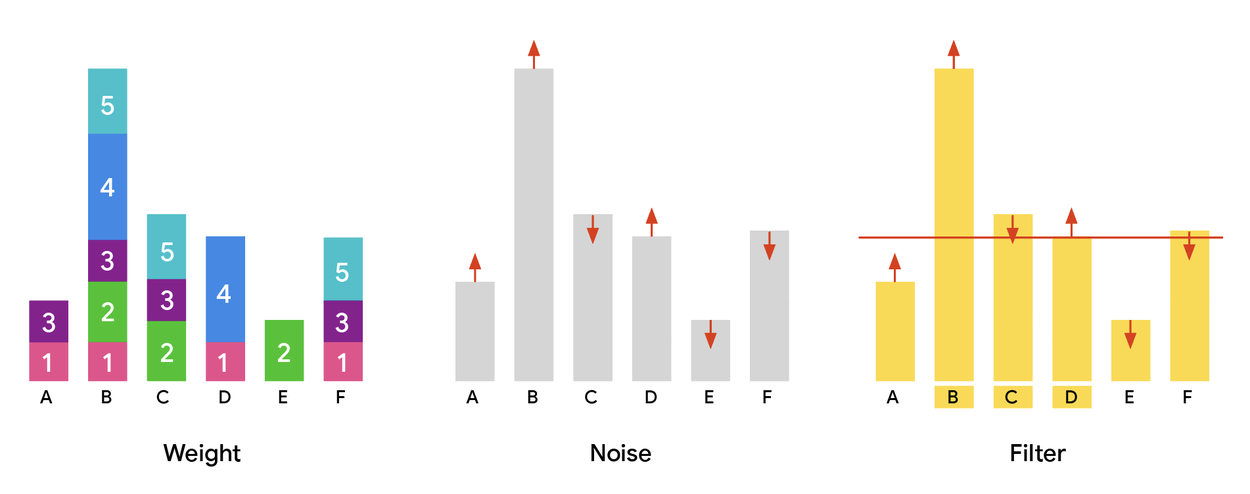
Benefícios principais:
- Privacidade reforçada: Minimiza o risco de vazamento de dados pessoais.
- Alta escalabilidade: Funciona eficientemente em grandes volumes de dados.
- Precisão mantida: Equilibra ruído e utilidade dos dados.
- Aplicabilidade ampla: Pode ser usado em diversos setores que lidam com dados sensíveis.
Impacto e aplicações práticas
Essa inovação tem potencial para transformar a forma como empresas e instituições conduzem análises de dados, especialmente aquelas que precisam conciliar a necessidade de insights profundos com a responsabilidade ética e legal de proteger a privacidade dos usuários.
Por exemplo, em pesquisas médicas, a seleção diferencialmente privada de partições pode permitir a análise de grandes bancos de dados de pacientes sem expor informações pessoais, acelerando descobertas científicas sem comprometer a confidencialidade.
Da mesma forma, em plataformas digitais, essa técnica pode ajudar a entender padrões de comportamento do usuário para melhorar serviços, respeitando as normas de privacidade e evitando abusos.
Conclusão
À medida que a coleta e análise de dados continuam a crescer, soluções como a seleção diferencialmente privada de partições são essenciais para garantir que a inovação tecnológica caminhe lado a lado com a proteção da privacidade. O trabalho do Google Research destaca a importância de abordagens responsáveis e avançadas para enfrentar os desafios atuais, promovendo um futuro onde dados e privacidade coexistam de forma harmoniosa.
Para profissionais de tecnologia, pesquisadores e empresas, entender e implementar essas técnicas será fundamental para construir sistemas confiáveis e éticos, que respeitem os direitos dos indivíduos e impulsionem o progresso.