QIMMA: A Plataforma que Revoluciona a Avaliação de Modelos de Linguagem em Árabe com Foco na Qualidade

Desafios na Avaliação de Modelos em Árabe
Embora o árabe seja falado por mais de 400 milhões de pessoas em diversas regiões e dialetos, a avaliação dos modelos de linguagem natural (NLP) para essa língua enfrenta diversos obstáculos. A avaliação atual é fragmentada e muitas vezes carece de validação rigorosa, o que compromete a confiança nos resultados. Entre os principais problemas estão:
- Traduções problemáticas: Muitos benchmarks são traduções do inglês, gerando distorções culturais e linguísticas que não refletem o uso natural do árabe.
- Ausência de validação de qualidade: Benchmarks nativos frequentemente apresentam erros de anotação, respostas incorretas, problemas de codificação e vieses culturais não corrigidos.
- Falta de reprodutibilidade: Scripts de avaliação e resultados detalhados raramente são disponibilizados, dificultando auditorias e avanços científicos.
- Fragmentação de cobertura: Leaderboards existentes focam em tarefas isoladas e domínios estreitos, prejudicando uma visão holística do desempenho dos modelos.
QIMMA: Um Novo Padrão em Avaliação de LLMs em Árabe
Para enfrentar esses desafios, a equipe do QIMMA قِمّة ⛰ desenvolveu uma plataforma que prioriza a qualidade e a transparência na avaliação de grandes modelos de linguagem (LLMs) em árabe. Diferentemente de outros leaderboards, o QIMMA valida rigorosamente os benchmarks antes de avaliar os modelos, garantindo que as pontuações reflitam a real capacidade linguística em árabe.
Características Principais do QIMMA
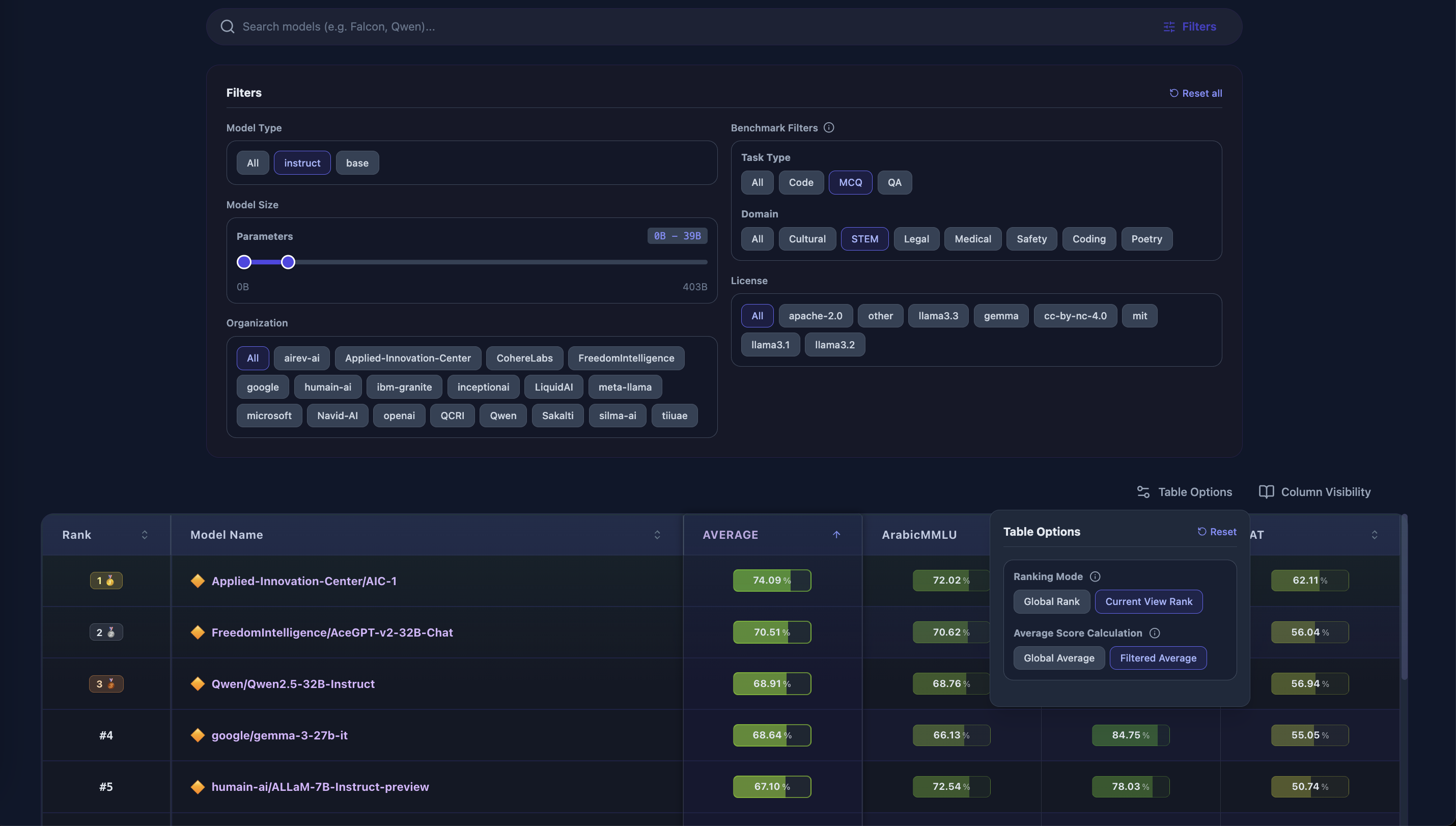
- Conteúdo 99% nativo em árabe: Evita artefatos de tradução, com exceção da avaliação de código, que é agnóstica à linguagem.
- Multi-domínio e multi-tarefa: Consolida 109 subconjuntos de 14 benchmarks, totalizando mais de 52 mil amostras em 7 domínios, incluindo educação, governança, saúde, literatura e programação.
- Primeiro leaderboard árabe com avaliação de código: Inclui versões adaptadas para o árabe dos benchmarks HumanEval+ e MBPP+, possibilitando avaliação em tarefas de programação.
- Transparência total: Resultados por amostra são públicos, assim como o código de avaliação, facilitando auditoria e reprodutibilidade.
- Validação em duas etapas: Combina avaliação automática por dois LLMs distintos com revisão humana para casos suspeitos.
Como Funciona a Validação de Qualidade do QIMMA
Antes de qualquer avaliação, todas as amostras passam por um pipeline rigoroso de validação em duas fases:
- Avaliação automática multi-modelo: Dois LLMs com capacidades robustas em árabe (Qwen3-235B-A22B-Instruct e DeepSeek-V3-671B) avaliam cada amostra com uma rubrica de 10 pontos. Amostras com pontuação baixa por ambos os modelos são descartadas imediatamente.
- Anotação e revisão humana: Amostras com divergência entre os modelos são analisadas por falantes nativos, que consideram nuances culturais, dialetais e interpretações subjetivas para garantir a adequação e qualidade.
Problemas Identificados
O processo revelou que mesmo benchmarks amplamente utilizados apresentam problemas sistemáticos, como respostas incorretas, erros de formatação, viés cultural e inconsistências nas respostas consideradas corretas.
- Taxonomia dos erros: Qualidade das respostas, problemas textuais e de formatação, sensibilidade cultural e conformidade das respostas ouro com protocolos de avaliação.
Avaliação de Código: Refinamento Linguístico
Na avaliação de código, em vez de descartar amostras, o QIMMA realizou refinamentos linguísticos nos enunciados para melhorar a clareza e naturalidade do árabe, mantendo intactas as soluções e testes originais. As modificações incluíram normalização do árabe moderno padrão, correção de ambiguidade, padronização terminológica, ajustes estruturais e refinamentos semânticos.
Framework de Avaliação e Métricas
QIMMA utiliza ferramentas como LightEval, EvalPlus e FannOrFlop para garantir consistência e reprodutibilidade. As métricas variam conforme o tipo de tarefa:
- MCQ (múltipla escolha): Log-verossimilhança normalizada e acurácia.
- Multi-seleção MCQ: Probabilidade acumulada nas escolhas corretas.
- QA generativa: F1 e BERTScore com modelo AraBERT v02.
- Código: Pass@1.
Além disso, o QIMMA padroniza os prompts em árabe, contemplando formatos variados para múltipla escolha, perguntas abertas e preenchimento de lacunas.
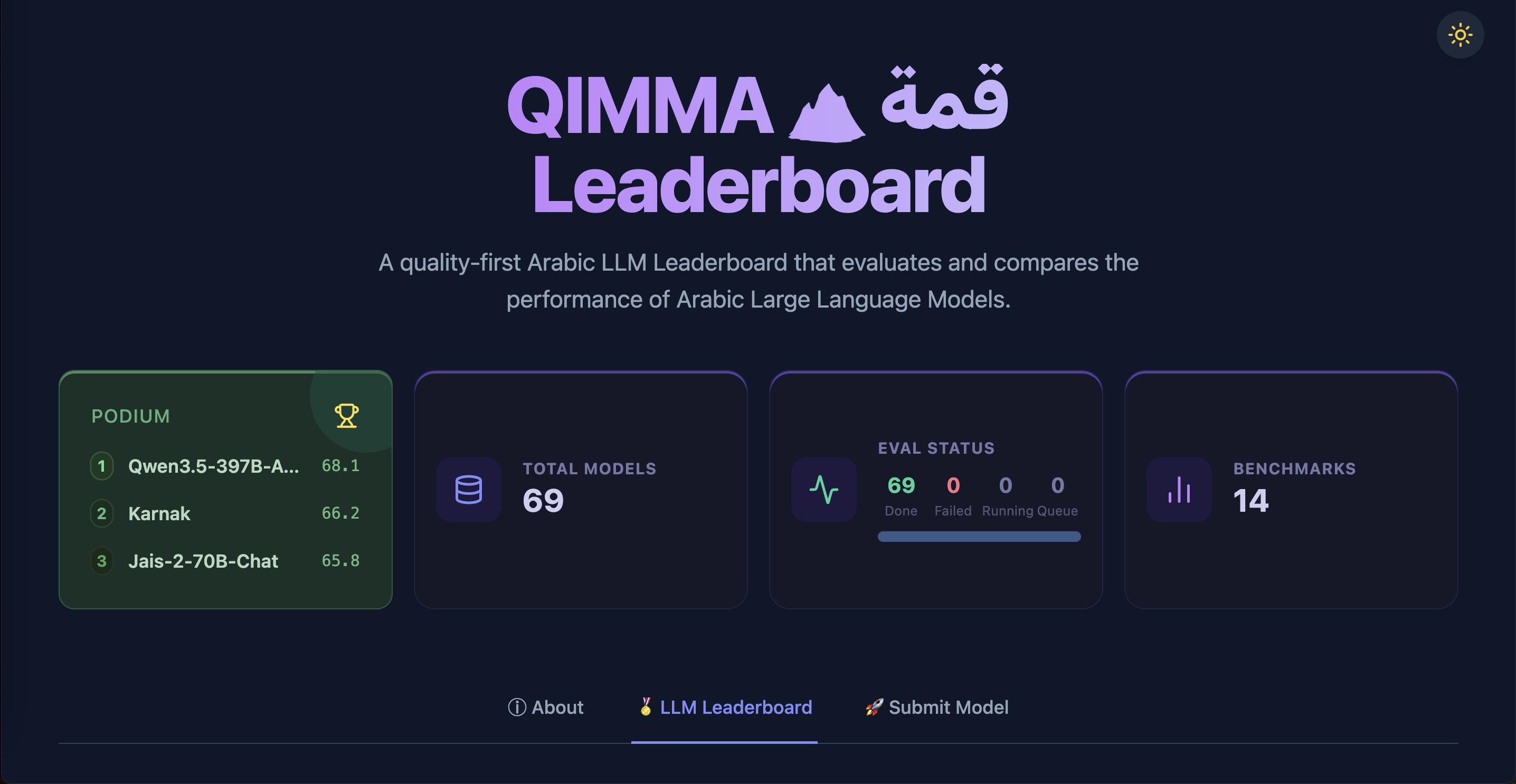
Resultados do Leaderboard
Foram avaliados 46 modelos open source, entre especializados em árabe e multilíngues, com tamanhos entre 1 bilhão e 400 bilhões de parâmetros. Destaques:
- Jais-2-70B-Chat: Líder geral e melhor em domínios cultural, STEM, legal e segurança.
- Qwen2.5-72B-Instruct: Segundo colocado, destaca-se em codificação e desempenho geral.
- Llama-3.3-70B-Instruct: Melhor no domínio médico, apesar de ser multilíngue.
- gemma-3-27b-it: Líder em poesia, demonstrando compreensão da linguagem literária árabe.
Observou-se que modelos multilíngues tendem a superar os especializados em árabe na codificação, indicando um desafio aberto para o treinamento focado em código com instruções em árabe. Além disso, há uma correlação geral entre tamanho do modelo e desempenho, mas com exceções relevantes, especialmente entre modelos especializados.
Por que o QIMMA é Diferente?
O diferencial do QIMMA está em sua abordagem quality-first, que assegura que a avaliação reflita a real capacidade dos modelos em árabe, combinando:
- Validação prévia dos dados, não posterior.
- Uso de múltiplos modelos para avaliação automática e revisão humana.
- Predominância de conteúdo nativo, minimizando traduções problemáticas.
- Avaliação multidomínio e multitarefa, incluindo código.
- Transparência total com dados e código abertos.
- Consciência dialetal e cultural no design dos prompts e rubricas.