ReasoningBank: Aprendizado Contínuo para Agentes Inteligentes a partir de Experiências

O desafio do aprendizado contínuo em agentes inteligentes
Agentes baseados em inteligência artificial têm se tornado cada vez mais fundamentais para a execução de tarefas complexas no mundo real, como navegação web e suporte em grandes bases de códigos de engenharia de software. No entanto, um desafio crítico persiste: esses agentes geralmente não conseguem aprender com suas experiências passadas, sejam elas de sucesso ou fracasso, após sua implantação. Sem um mecanismo de memória eficiente, eles tendem a repetir os mesmos erros estratégicos e a desperdiçar oportunidades valiosas de aprendizado.
O que é o ReasoningBank?
Para superar essa limitação, pesquisadores do Google Research desenvolveram o ReasoningBank, um framework inovador de memória para agentes que extrai e estrutura aprendizados a partir de experiências bem-sucedidas e fracassadas. Publicado no artigo "ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory", o sistema permite que agentes evoluam continuamente durante o uso, melhorando sua eficácia e eficiência.
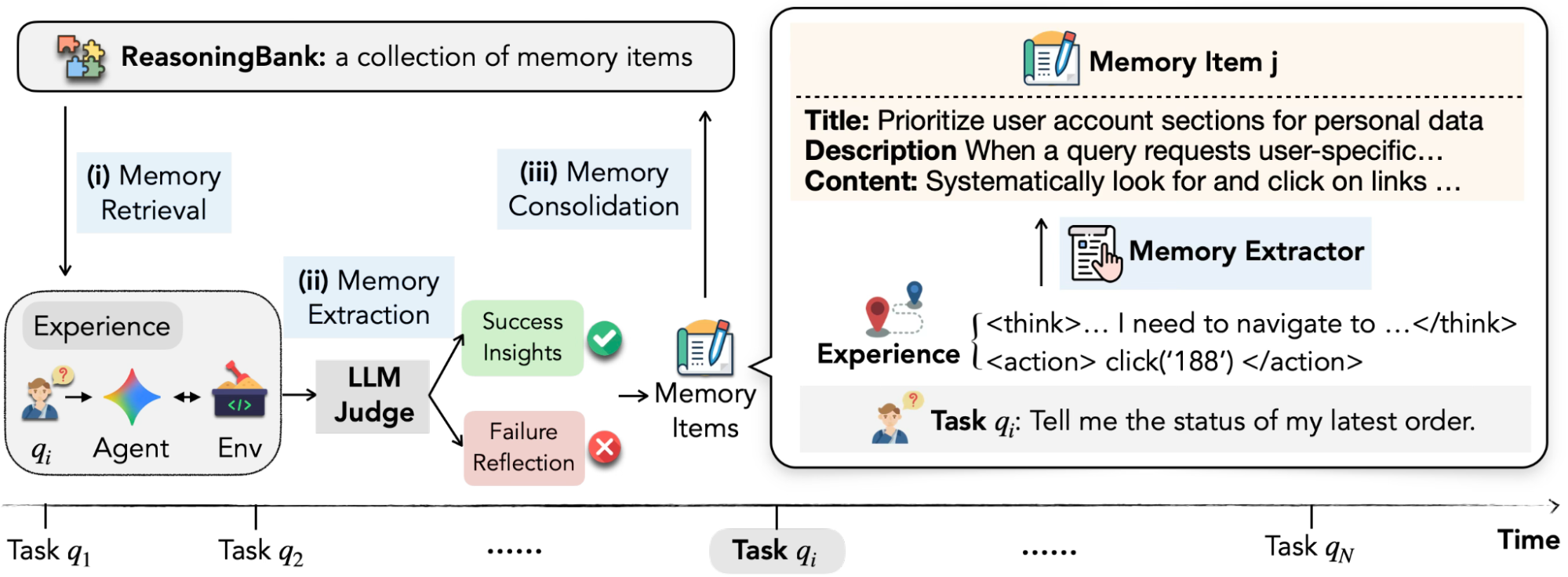
Como funciona o framework?
- Memórias estruturadas: Cada item armazenado contém um título resumido, uma descrição breve e o conteúdo que representa os passos de raciocínio, justificativas de decisão e insights operacionais derivados das experiências anteriores.
- Loop contínuo de aprendizado: Antes de agir, o agente recupera memórias relevantes do ReasoningBank para contextualizar suas decisões. Após a interação, ele usa um modelo de linguagem grande (LLM) como juiz para autoavaliar a trajetória, extraindo aprendizados tanto de sucessos quanto de falhas.
- Incorporação de falhas: Ao contrário de abordagens anteriores que focam apenas em experiências bem-sucedidas, o ReasoningBank também analisa erros para criar lições preventivas, ajudando a evitar armadilhas futuras.
Memória e escalabilidade: a técnica Memory-aware Test-time Scaling (MaTTS)
O artigo também introduz o conceito de Memory-aware Test-time Scaling (MaTTS), que integra a memória do ReasoningBank com técnicas de escala computacional durante a inferência, potencializando o aprendizado do agente. Essa abordagem explora dois modos:
- Escalabilidade paralela: o agente gera múltiplas trajetórias distintas para a mesma tarefa, comparando-as para refinar estratégias e gerar memórias mais robustas.
- Escalabilidade sequencial: o agente melhora iterativamente seu raciocínio dentro de uma única trajetória, capturando insights intermediários para aprimorar a memória.
Essa sinergia entre memória e escalabilidade permite que o agente direcione suas explorações para estratégias mais promissoras, acelerando o aprendizado.
Resultados práticos e avanços observados
O ReasoningBank foi avaliado em benchmarks desafiadores, como WebArena (navegação web) e SWE-Bench-Verified (engenharia de software), utilizando o modelo Gemini-2.5-Flash. Os resultados demonstraram:

- Melhora significativa nas taxas de sucesso: aumento de 8,3% no WebArena e 4,6% no SWE-Bench-Verified em comparação com agentes sem memória.
- Ganho de eficiência: redução de quase 3 passos de execução por tarefa, graças ao acesso ativo a raciocínios anteriores.
- Potencial ampliado com MaTTS: combinação que elevou a taxa de sucesso em 3% e reduziu ainda mais os passos necessários.
Além disso, observou-se uma evolução da maturidade estratégica do agente, que passou de regras simples para estruturas lógicas preventivas e composicionais, refletindo aprendizado contínuo e refinamento progressivo.
Limitações e perspectivas futuras
Embora o ReasoningBank apresente avanços notáveis, a consolidação das memórias ainda é feita de forma simples, com a adição direta de novos aprendizados. Estratégias mais sofisticadas para organizar e priorizar memórias estão previstas para pesquisas futuras. Além disso, o sistema depende da autoavaliação feita pelo LLM, que, apesar de não exigir precisão perfeita, pode influenciar a qualidade do aprendizado.
Por que essa pesquisa importa no mundo real?
O ReasoningBank representa um passo fundamental para agentes autônomos que precisam operar por longos períodos em ambientes dinâmicos, aprendendo e adaptando-se de forma contínua. Isso é crucial para aplicações práticas como assistentes virtuais personalizados, sistemas de navegação automatizados, ferramentas de desenvolvimento de software e muito mais, onde a capacidade de aprender com experiências anteriores — especialmente com erros — é vital para a robustez e eficiência.