Revolução na Busca por Voz: Conheça a Tecnologia Speech-to-Retrieval (S2R)

A busca por voz tem se tornado cada vez mais presente no cotidiano dos usuários, impulsionada pela popularização de assistentes virtuais e dispositivos conectados. No entanto, apesar dos avanços, a precisão e a velocidade das buscas ainda enfrentam desafios importantes. Pensando nisso, pesquisadores do Google Research desenvolveram uma abordagem inovadora chamada Speech-to-Retrieval (S2R), que promete transformar a forma como interagimos com a busca por voz.
O que é Speech-to-Retrieval (S2R)?
Tradicionalmente, sistemas de busca por voz funcionam em duas etapas principais: primeiro, a fala é convertida em texto por meio do reconhecimento automático de fala (ASR); em seguida, esse texto é utilizado para realizar a busca no banco de dados. Embora eficaz, esse processo pode introduzir atrasos e erros, especialmente quando o reconhecimento de fala não é perfeito.

A tecnologia S2R propõe uma abordagem diferente, que elimina a etapa intermediária de transcrição. Em vez disso, o sistema aprende a mapear diretamente a entrada de áudio para os documentos relevantes, otimizando a busca e reduzindo a latência. Isso significa que a busca é feita diretamente a partir do áudio, tornando o processo mais rápido e robusto.
Como funciona o Speech-to-Retrieval?
O S2R utiliza modelos avançados de aprendizado de máquina para criar representações vetoriais do áudio e dos documentos. Essas representações são comparadas em um espaço vetorial compartilhado para identificar os conteúdos mais relevantes para a consulta de voz.
Principais componentes da tecnologia:
- Codificação de áudio: O áudio da consulta é processado para extrair características relevantes que representam o conteúdo falado.
- Indexação dos documentos: Os documentos do banco de dados são convertidos em vetores que capturam seu significado semântico.
- Busca vetorial: O sistema realiza uma busca eficiente no espaço vetorial para encontrar os documentos mais próximos da consulta em áudio.
Essa abordagem elimina a necessidade de converter o áudio em texto, o que reduz erros causados por falhas no reconhecimento de fala e acelera o processo de recuperação da informação.
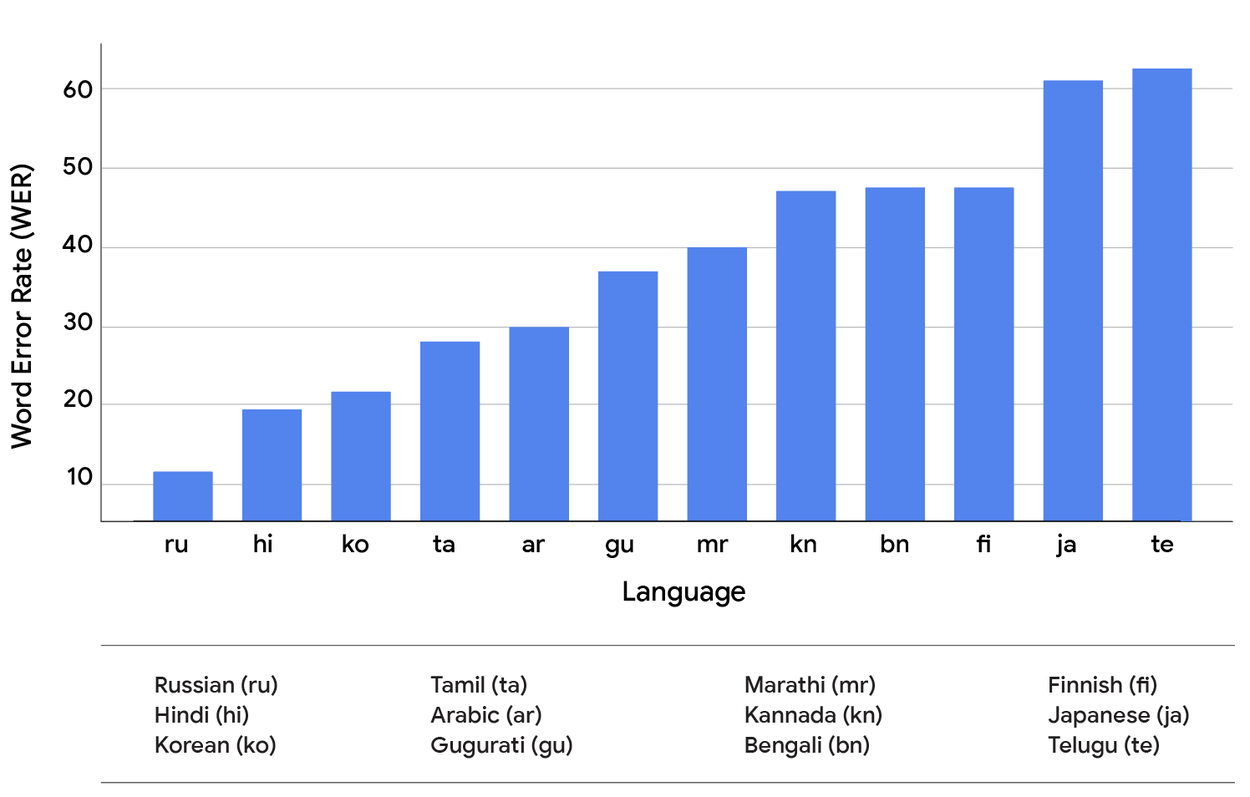
Vantagens do S2R para a busca por voz
- Maior velocidade: Ao eliminar a etapa de transcrição, o sistema responde mais rapidamente às consultas.
- Melhor precisão: A busca direta no áudio reduz a propagação de erros, aumentando a relevância dos resultados.
- Robustez a ruídos e variações: O modelo é capaz de lidar melhor com diferentes sotaques, entonações e ambientes ruidosos.
- Eficiência em dispositivos móveis: A redução de etapas permite uma experiência mais fluida em smartphones e assistentes domésticos.
Desafios e perspectivas futuras
Apesar das vantagens, o S2R ainda enfrenta desafios para ser amplamente adotado. A criação de modelos que compreendam nuances da fala e que sejam escaláveis para grandes volumes de dados é complexa. Além disso, a integração com sistemas existentes e a garantia de privacidade dos usuários são questões importantes a serem consideradas.
No entanto, a pesquisa continua avançando rapidamente, e a expectativa é que essa tecnologia seja incorporada em produtos comerciais em um futuro próximo, elevando a experiência da busca por voz a um novo patamar.
Conclusão
O Speech-to-Retrieval representa uma inovação significativa no campo da busca por voz, oferecendo uma solução mais rápida, precisa e eficiente ao eliminar a etapa intermediária de transcrição. Com o crescimento constante do uso de interfaces de voz, tecnologias como o S2R são essenciais para tornar a interação com dispositivos cada vez mais natural e satisfatória.
Fique atento às novidades e prepare-se para uma nova era na forma como buscamos informações usando apenas a nossa voz.