Revolução no Treinamento de IA: Reduzindo Dados em 10.000x com Rótulos de Alta Fidelidade

Nos últimos anos, o avanço da Inteligência Artificial (IA) tem sido impulsionado por grandes volumes de dados de treinamento. No entanto, coletar e rotular esses dados é uma tarefa custosa e demorada. Recentemente, pesquisadores do Google Research apresentaram uma abordagem inovadora que promete reduzir em até 10.000 vezes a quantidade de dados necessários para treinar modelos de IA, mantendo a alta qualidade dos rótulos. Este avanço pode transformar a forma como desenvolvemos e aplicamos IA, tornando o processo mais eficiente e acessível.
O desafio dos dados em IA
O desempenho dos modelos de IA depende diretamente da qualidade e da quantidade dos dados utilizados em seu treinamento. Tradicionalmente, para alcançar resultados robustos, é necessário dispor de grandes bases de dados, muitas vezes contendo milhões de exemplos. Além do volume, a fidelidade dos rótulos — ou seja, a precisão com que os dados são classificados ou anotados — é crucial para garantir que o modelo aprenda corretamente.
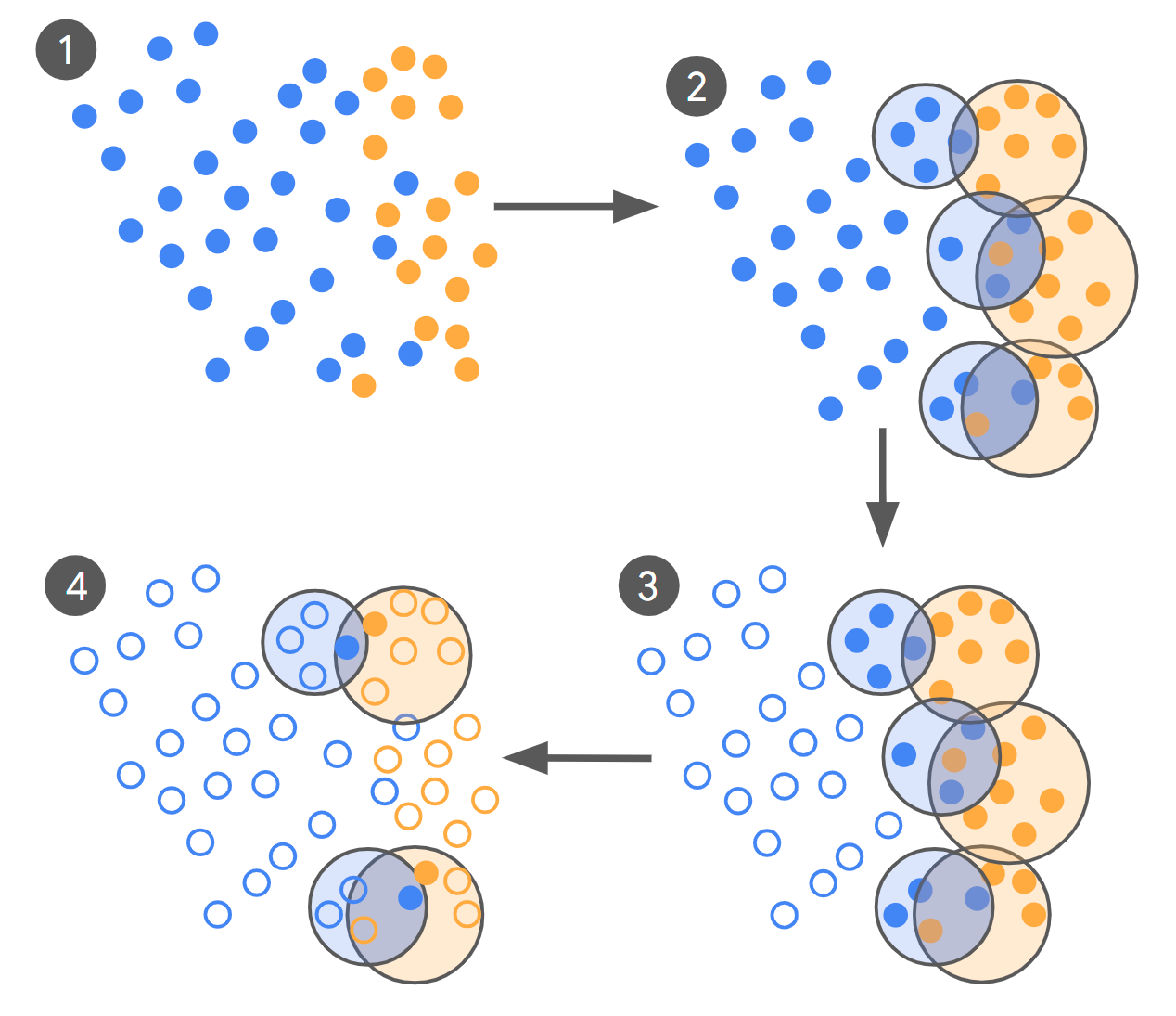
Porém, essa abordagem apresenta limitações significativas:
- Custo elevado: A coleta e anotação de dados exigem recursos humanos e financeiros consideráveis.
- Tempo: O processo pode levar meses ou até anos, dependendo da complexidade da tarefa.
- Escalabilidade: Grandes volumes de dados dificultam a adaptação rápida a novos domínios ou tarefas específicas.
A inovação do Google Research
Para superar esses obstáculos, o Google Research desenvolveu uma metodologia que utiliza rótulos de alta fidelidade para reduzir drasticamente a quantidade de dados necessários. A ideia central é que, ao melhorar a qualidade da informação fornecida ao modelo, é possível diminuir o volume de exemplos sem comprometer a performance.
Essa abordagem envolve técnicas avançadas de interação humano-computador e visualização, que facilitam a criação de rótulos mais precisos e confiáveis. Além disso, o método incorpora mecanismos para garantir segurança, privacidade e prevenção de abusos, aspectos essenciais em aplicações reais de IA.
Como funciona na prática?
- Rótulos de alta fidelidade: Em vez de simplesmente classificar dados, os especialistas fornecem anotações detalhadas e contextualizadas, enriquecendo o aprendizado do modelo.
- Interação eficiente: Ferramentas interativas permitem que humanos e máquinas colaborem de forma mais produtiva, acelerando o processo de rotulagem.
- Visualização avançada: Técnicas visuais ajudam a identificar rapidamente inconsistências e áreas que necessitam de maior atenção, otimizando a qualidade dos dados.
Impactos e benefícios
Essa redução massiva na quantidade de dados de treinamento traz uma série de benefícios para o desenvolvimento de IA:
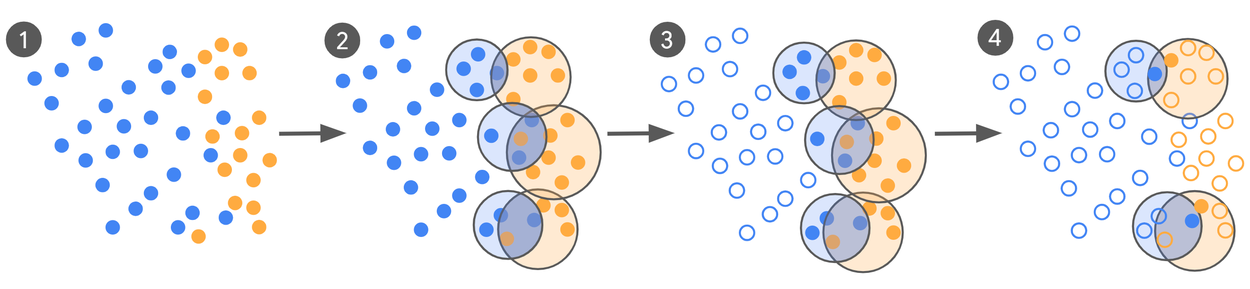
- Economia de recursos: Menos dados significa menos tempo e dinheiro gastos em coleta e anotação.
- Agilidade: Modelos podem ser treinados e atualizados mais rapidamente, acelerando a inovação.
- Personalização: É possível adaptar modelos para nichos específicos com menos esforço, ampliando o alcance da IA.
- Privacidade reforçada: Com menos dados necessários, há menor exposição de informações sensíveis.
Desafios e perspectivas futuras
Apesar dos avanços promissores, a implementação dessa técnica ainda enfrenta desafios, como a necessidade de especialistas qualificados para fornecer rótulos de alta fidelidade e a complexidade das ferramentas de visualização e interação. No entanto, com o contínuo progresso em interfaces intuitivas e automação assistida, espera-se que essas barreiras sejam superadas.
O futuro da IA pode ser marcado por treinamentos mais eficientes e éticos, onde a qualidade dos dados prevalece sobre a quantidade. Essa mudança de paradigma abre portas para aplicações mais rápidas, seguras e acessíveis, beneficiando tanto pesquisadores quanto a indústria e a sociedade.
Conclusão
A pesquisa do Google Research demonstra que é possível revolucionar o treinamento de modelos de IA ao focar em rótulos de alta fidelidade, reduzindo drasticamente a necessidade de grandes volumes de dados. Essa abordagem não só diminui custos e tempo, mas também fortalece aspectos cruciais como segurança e privacidade. Para o ecossistema de IA, trata-se de um passo importante rumo a soluções mais eficientes e responsáveis, que podem acelerar a adoção da inteligência artificial em diversas áreas.
Fique atento ao "IA em Foco" para mais novidades e análises sobre as tecnologias que estão moldando o futuro da inteligência artificial!