SigLIP 2: Avanços na Codificação Multilíngue para Visão e Linguagem

Nos últimos anos, a integração entre visão computacional e processamento de linguagem natural tem impulsionado a evolução da inteligência artificial (IA). Modelos que conseguem interpretar imagens e textos simultaneamente são essenciais para aplicações que vão desde assistentes virtuais até sistemas de busca visual e tradução automática. Nesse contexto, o SigLIP 2 surge como uma inovação promissora, trazendo melhorias significativas para codificadores multilíngues de visão e linguagem.
O que é o SigLIP 2?
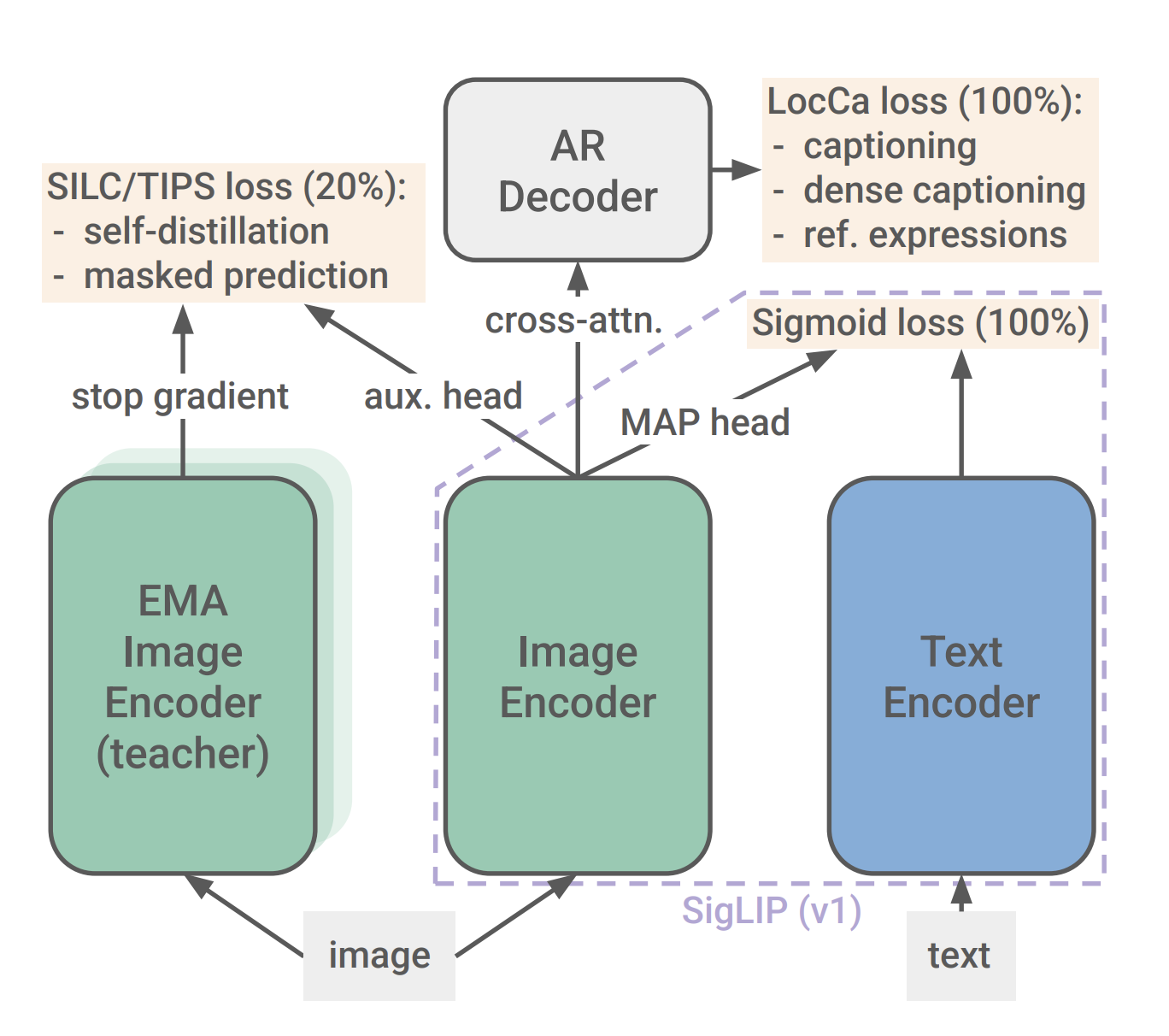
SigLIP 2 é a segunda versão de um codificador multimodal desenvolvido para entender e relacionar informações visuais e textuais em múltiplos idiomas. Diferente de modelos anteriores que focavam principalmente em uma única língua, o SigLIP 2 foi projetado para oferecer uma representação mais robusta e precisa, independentemente do idioma do texto associado à imagem.
Por que a multilíngue é importante?
Vivemos em um mundo globalizado onde o conteúdo digital é produzido em diversas línguas. Ter um modelo que compreenda imagens associadas a textos em diferentes idiomas é fundamental para democratizar o acesso à informação e melhorar a experiência do usuário em aplicações que envolvem múltiplas culturas e idiomas.
Principais avanços do SigLIP 2
- Melhoria na precisão: O SigLIP 2 apresenta uma arquitetura otimizada que aumenta a capacidade do modelo de correlacionar imagens e textos, resultando em uma melhor compreensão contextual.
- Suporte ampliado a idiomas: Enquanto a versão anterior tinha limitações em idiomas menos comuns, o SigLIP 2 amplia o suporte para dezenas de línguas, incluindo aquelas com estruturas linguísticas complexas.
- Treinamento eficiente: Utilizando técnicas avançadas de aprendizado, o modelo consegue ser treinado com menos dados e recursos computacionais, tornando-o mais acessível para pesquisadores e desenvolvedores.
- Aplicações versáteis: O modelo é capaz de ser aplicado em diversas áreas, como sistemas de recomendação, tradução automática multimodal, análise de conteúdo em redes sociais e muito mais.
Como o SigLIP 2 funciona?
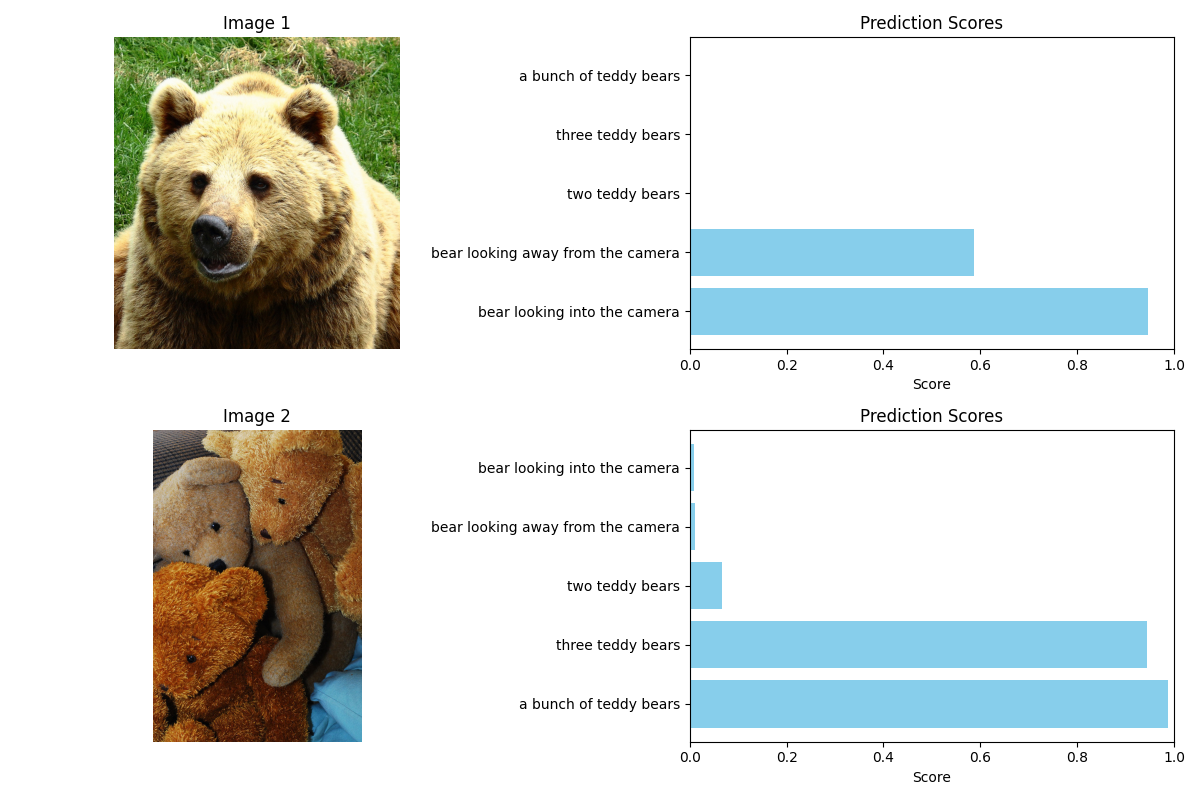
O modelo combina redes neurais convolucionais para processar imagens com transformadores para entender textos. A inovação está na forma como essas duas modalidades são integradas e alinhadas semanticamente, permitindo que o sistema compreenda o significado compartilhado entre a imagem e o texto, mesmo quando o texto está em idiomas diferentes.
Além disso, o SigLIP 2 utiliza uma técnica chamada "aprendizado contrastivo", que ajuda o modelo a distinguir entre pares correspondentes e não correspondentes de imagens e textos, aprimorando a qualidade das representações geradas.
Impactos e aplicações práticas
Com a capacidade multilíngue aprimorada, o SigLIP 2 pode revolucionar diversos setores:
- Educação: Ferramentas educacionais podem oferecer conteúdos visuais acompanhados de explicações em diferentes idiomas, facilitando o aprendizado global.
- Comércio eletrônico: Plataformas podem apresentar descrições de produtos e imagens de forma mais precisa para clientes de várias regiões.
- Assistentes virtuais: Melhor compreensão multimodal permite interações mais naturais e contextuais com usuários multilíngues.
- Monitoramento de redes sociais: Análise de imagens e textos em múltiplos idiomas ajuda a identificar tendências, sentimentos e conteúdos relevantes.
Conclusão
O SigLIP 2 representa um avanço significativo na área de IA multimodal, especialmente no que diz respeito ao suporte multilíngue. Ao melhorar a integração entre visão e linguagem em diversos idiomas, o modelo abre portas para aplicações mais inclusivas e eficientes, capazes de atender a uma audiência global. Para desenvolvedores e pesquisadores, essa inovação traz novas oportunidades para criar soluções inteligentes que entendem o mundo visual e textual de forma integrada e multicultural.
Fique atento às próximas atualizações do SigLIP 2 e acompanhe como essa tecnologia pode transformar a maneira como interagimos com a informação no dia a dia.