Simula: Como o Google está revolucionando a geração de dados sintéticos para IA especializada

O desafio dos dados especializados para IA
O avanço acelerado dos modelos de IA generalistas tem sido impulsionado pela enorme quantidade de dados disponíveis na internet. Entretanto, para que a IA seja integrada em aplicações especializadas, incomuns ou que envolvem dados sensíveis, é necessário lidar com a escassez ou inacessibilidade desses dados no mundo real. Criar datasets especializados manualmente é caro, demorado e sujeito a erros, além de dificultar ciclos de desenvolvimento ágeis.
Nesse contexto, a geração de dados sintéticos surge como uma alternativa promissora, permitindo workflows programáveis onde os dados são tratados como código — versionáveis, reprodutíveis e auditáveis. Além disso, possibilita a geração proativa de casos extremos para testar a robustez dos sistemas antes que falhas aconteçam no ambiente real.
Limitações das abordagens atuais e a necessidade de uma nova perspectiva
Métodos tradicionais de geração sintética costumam depender de prompts manuais, algoritmos evolutivos ou dados iniciais da distribuição alvo, o que limita a escalabilidade, o controle e a explicabilidade do processo. Além disso, a maioria desses métodos opera no nível de amostras individuais, sem considerar o design do dataset como um todo.
Para superar essas limitações, pesquisadores do Google propõem reformular a geração sintética como um problema de design de mecanismos, focando em controlar independentemente variáveis como cobertura, complexidade e qualidade do conjunto de dados.
Simula: framework de geração de dados sintéticos baseado em raciocínio
O artigo "Reasoning-Driven Synthetic Data Generation and Evaluation" apresenta o Simula, um framework que constrói datasets sintéticos a partir de princípios fundamentais, sem depender de dados iniciais (seedless) e que evolui conforme as capacidades de raciocínio dos modelos subjacentes avançam.
Controle das dimensões da geração de dados
- Diversificação Global: Utiliza modelos de raciocínio para mapear o espaço conceitual do domínio em taxonomias hierárquicas profundas, que servem como "andaimes" para amostragem. Esse processo iterativo de "propor e refinar" gera uma taxonomia densa sem depender de dados humanos iniciais, garantindo cobertura ampla, incluindo a cauda longa do domínio.
- Diversificação Local: Para evitar repetições idênticas, o Simula cria "meta-prompts" a partir dos nós das taxonomias e gera múltiplas instâncias distintas para cada cenário, promovendo variedade dentro de conceitos específicos.
- Complexificação: Uma etapa que aumenta a dificuldade ou sofisticação de uma fração configurável dos meta-prompts, permitindo ajustar a distribuição de complexidade do dataset sem alterar sua cobertura semântica.
- Verificação de Qualidade: Emprega um ciclo de dupla avaliação (dual-critic) que verifica se as respostas geradas estão corretas, minimizando o viés de concordância com saídas plausíveis (sifonofania) e assegurando rótulos de alta qualidade sem intervenção humana.
Desafios e métricas para avaliação de dados sintéticos
A avaliação de dados sintéticos é complexa, já que métricas tradicionais, como distância de cosseno entre embeddings, oferecem sinais superficiais e pouco úteis para ajustes práticos. O Simula propõe métricas baseadas em raciocínio, como Taxonomic Coverage (cobertura da taxonomia) e Calibrated Complexity Scoring (pontuação calibrada de complexidade), que utilizam comparações em lote feitas por grandes modelos de linguagem para atribuir classificações ao estilo "Elo" para cada ponto de dado.
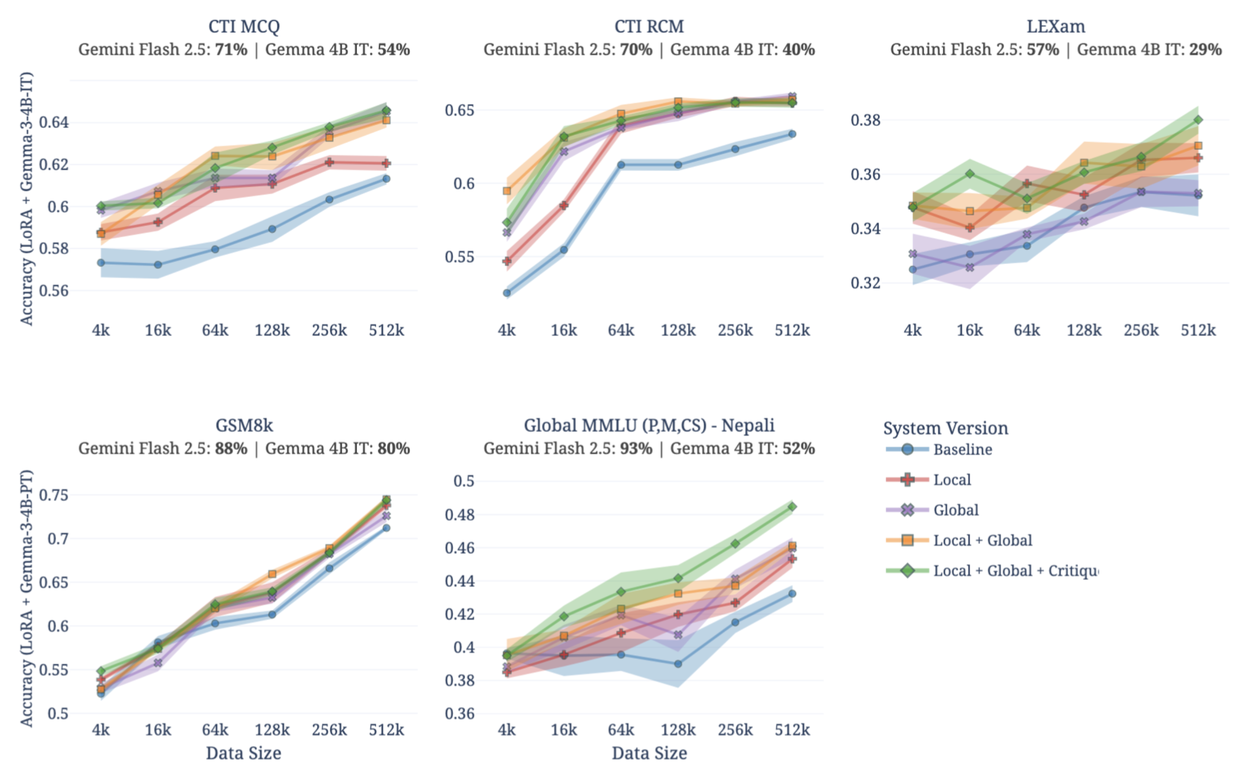
Resultados da aplicação do Simula em múltiplos domínios
O Simula foi avaliado usando o modelo Gemini 2.5 Flash como professor e o Gemma-3 4B como aluno, em cinco domínios diversos: segurança cibernética (CTI-MCQ, CTI-RCM do CTIBench), raciocínio jurídico (LEXam), matemática escolar (GSM8k) e conhecimento acadêmico multilíngue (Global MMLU). Foram gerados datasets com até 512 mil exemplos para cada domínio.
- Design de mecanismo é essencial: A combinação completa do Simula (cobertura global, diversidade local e avaliação crítica) superou consistentemente abordagens mais simples.
- Contexto importa: Não existe uma receita única. Por exemplo, maior complexidade melhorou 10% a acurácia em matemática, mas prejudicou o desempenho no raciocínio jurídico, onde o modelo professor era mais fraco.
- Qualidade supera quantidade: Dados melhores escalam melhor. O Simula alcançou performance superior com menos amostras, confirmando que as leis de escala dependem da qualidade dos dados e não apenas do volume.
Impacto real e aplicações práticas do Simula
O Simula não foi criado apenas para otimizar benchmarks acadêmicos, mas serve como motor de dados para aplicações críticas dentro do Google. Ele é a base sintética para o ecossistema Gemma, que inclui modelos especializados como ShieldGemma, FunctionGemma e MedGemma, além de sistemas de segurança para classificação e filtragem em dispositivos e servidores.
Além disso, o Simula tem sido fundamental para recursos de proteção de usuários, como detecção de golpes em chamadas no Android e filtragem de spam no Google Messages. A pesquisa também impulsiona avanços em segurança empresarial e no ensino de IA para interpretar mapas através de geração estruturada e guiada por raciocínio.
Por que essa pesquisa importa para o futuro da IA
O progresso da IA especializada depende da disponibilidade de dados que dificilmente podem ser gerados em escala por humanos. A geração sintética rigorosa, como a proposta pelo Simula, é crucial para criar datasets de alta fidelidade que atendam às demandas da próxima geração de modelos, seja para dispositivos de ponta, aprendizado por reforço ou exploração sistemática de casos extremos complexos.
Links úteis
- Artigo original do Google Research sobre Simula
- Democratize ML for Enterprise Security (paper relacionado)
- GSM8k - Dataset de matemática escolar
- CTIBench - Benchmark de inteligência contra ameaças cibernéticas
- LEXam - Benchmark para raciocínio jurídico
- FunctionGemma - ferramenta do ecossistema Gemma
- MedGemma - modelo especializado em saúde