SmolAgents agora com suporte a Modelos Visuais e Linguísticos: uma revolução na IA multimodal

Nos últimos anos, a inteligência artificial tem avançado rapidamente, especialmente na integração de múltiplas modalidades de dados, como texto e imagem. Um dos grandes desafios tem sido desenvolver agentes inteligentes capazes de compreender e interagir com diferentes tipos de informação simultaneamente. É nesse contexto que a novidade anunciada pela HuggingFace se destaca: o suporte a Modelos Visuais e Linguísticos (VLMs) no framework SmolAgents.
O que são SmolAgents e por que eles importam?
SmolAgents é uma biblioteca leve e flexível desenvolvida para facilitar a criação de agentes inteligentes que podem executar tarefas complexas usando modelos de linguagem. Seu foco principal é permitir que desenvolvedores construam agentes personalizados, que interajam com APIs, bases de dados e outras ferramentas, de forma simples e eficiente.
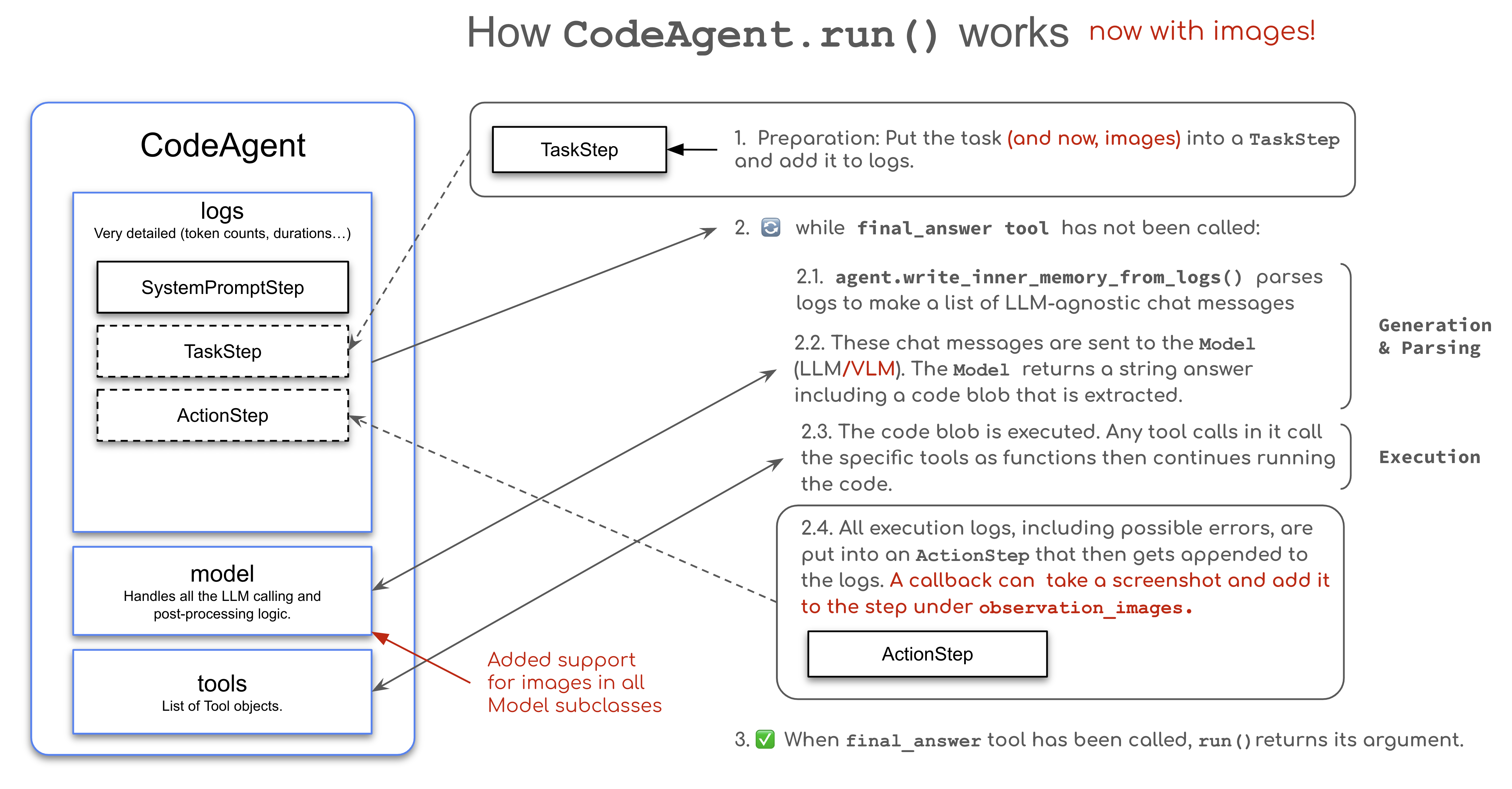
Antes do suporte a VLMs, SmolAgents trabalhava principalmente com modelos baseados em texto, limitando sua capacidade de interpretar dados visuais ou realizar tarefas multimodais. Com a crescente demanda por soluções que combinem visão computacional e processamento de linguagem natural, essa limitação se tornou um ponto a ser superado.
O que são Modelos Visuais e Linguísticos (VLMs)?
Modelos Visuais e Linguísticos, ou VLMs, são sistemas de inteligência artificial treinados para entender e relacionar informações visuais (imagens, vídeos) e linguísticas (texto, fala). Exemplos populares incluem CLIP, BLIP e Flamingo, que conseguem associar descrições textuais a imagens, responder perguntas sobre imagens e até mesmo gerar legendas automáticas.
Esses modelos são fundamentais para aplicações que exigem uma compreensão multimodal, como assistentes virtuais que interpretam fotos enviadas pelos usuários, sistemas de busca por imagens ou robôs que navegam em ambientes reais.
O que muda com o suporte a VLMs no SmolAgents?
Integrar VLMs ao SmolAgents significa ampliar significativamente as capacidades dos agentes criados com essa ferramenta. Agora, os agentes podem:
- Interpretar imagens e vídeos: analisar conteúdo visual para extrair informações relevantes.
- Responder a perguntas multimodais: combinar dados visuais e textuais para fornecer respostas precisas.
- Executar tarefas complexas: como descrever imagens, classificar objetos ou realizar buscas visuais.
- Interagir de forma mais natural: entendendo contextos que envolvem múltiplas fontes de informação.
Essa evolução abre portas para aplicações inovadoras em áreas como educação, saúde, comércio eletrônico, entretenimento e muito mais.
Como funciona a integração técnica?
A HuggingFace implementou um suporte robusto para VLMs dentro do SmolAgents, garantindo que os desenvolvedores possam facilmente conectar modelos visuais e linguísticos às suas pipelines de agentes. Isso inclui:

- Interfaces simplificadas para carregar e utilizar VLMs.
- Compatibilidade com diversos modelos disponíveis na HuggingFace Hub.
- Ferramentas para pré-processamento e pós-processamento de dados multimodais.
- Documentação detalhada e exemplos práticos para acelerar o desenvolvimento.
Além disso, a integração mantém a leveza e a flexibilidade características do SmolAgents, possibilitando a criação de agentes eficientes mesmo em ambientes com recursos limitados.
Impactos e possibilidades futuras
Com o suporte a VLMs, SmolAgents se posiciona como uma solução poderosa para desenvolvedores que buscam criar agentes inteligentes multimodais. As possibilidades incluem:
- Assistentes pessoais mais completos: capazes de interpretar imagens enviadas pelo usuário para fornecer suporte contextualizado.
- Ferramentas educacionais interativas: que combinam texto e imagens para melhorar o aprendizado.
- Sistemas de atendimento ao cliente: que entendem fotos de produtos ou documentos enviados para agilizar processos.
- Robótica e automação: agentes que interpretam o ambiente visual para tomar decisões mais inteligentes.
Essa integração também incentiva a comunidade a explorar novas formas de combinar visão e linguagem, impulsionando a inovação no campo da inteligência artificial.
Conclusão
A adição do suporte a Modelos Visuais e Linguísticos no SmolAgents representa um avanço significativo para o desenvolvimento de agentes inteligentes multimodais. Essa novidade da HuggingFace não só amplia o leque de aplicações possíveis, como também simplifica o processo de criação de agentes que entendem e interagem com o mundo de forma mais rica e natural.
Para desenvolvedores e entusiastas de IA, essa é uma oportunidade imperdível para explorar o potencial dos VLMs em projetos inovadores. A combinação de texto e imagem em agentes inteligentes promete transformar a maneira como interagimos com a tecnologia, aproximando-a cada vez mais da complexidade e riqueza da comunicação humana.
Fique atento às atualizações do SmolAgents e comece a experimentar as novas funcionalidades para levar seus projetos de inteligência artificial a um novo patamar!