SmolVLA: O Novo Modelo Eficiente que Une Visão, Linguagem e Ação com Dados da Comunidade Lerobot

A inteligência artificial está avançando rapidamente, integrando diferentes modalidades para criar sistemas cada vez mais inteligentes e versáteis. Um dos grandes desafios atuais é desenvolver modelos que consigam interpretar imagens, compreender linguagem natural e ainda executar ações baseadas nessas informações. É nesse contexto que surge o SmolVLA, um modelo inovador e eficiente treinado com dados da comunidade Lerobot, que promete revolucionar a forma como máquinas entendem e interagem com o mundo.
O que é o SmolVLA?
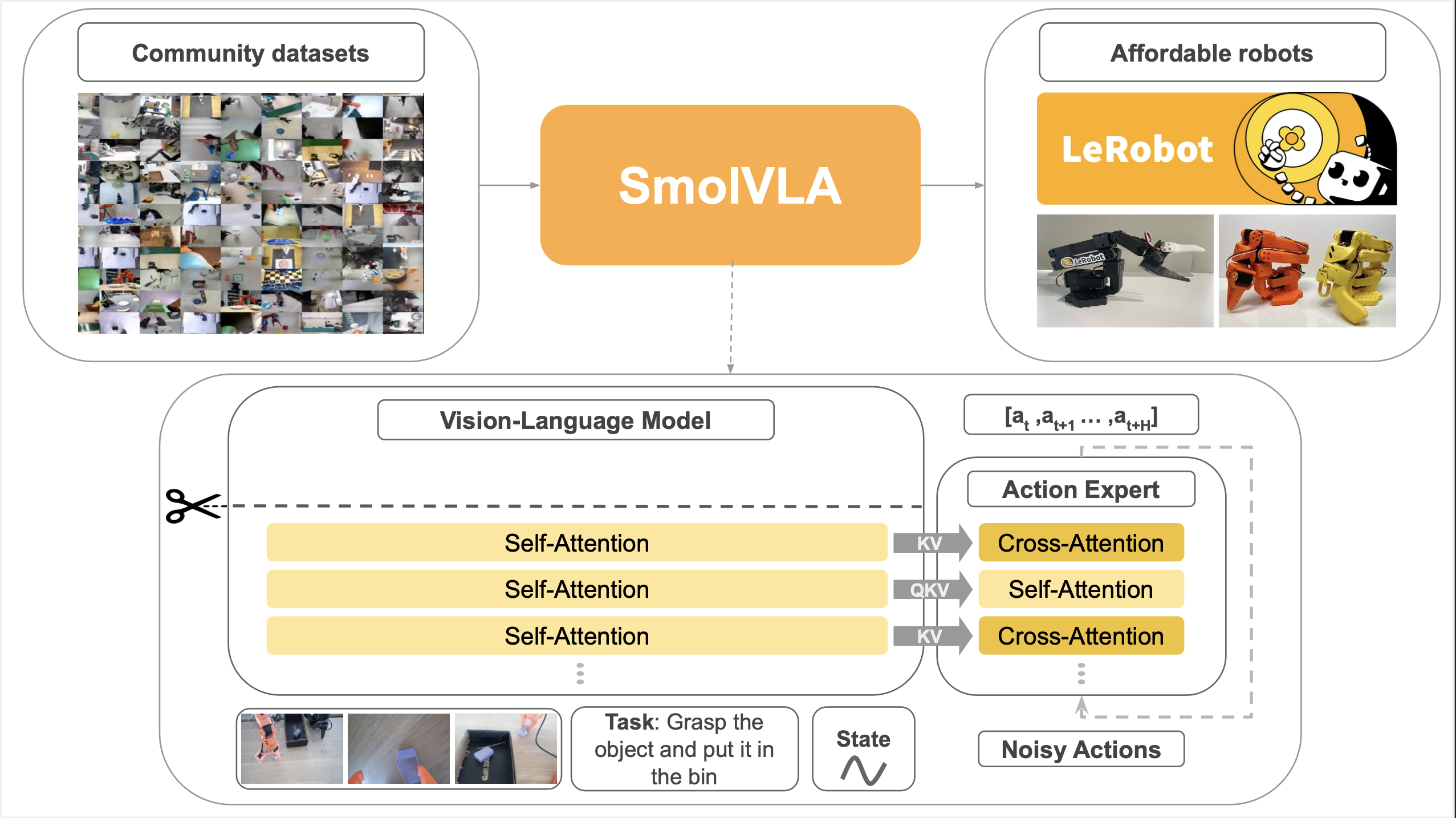
O SmolVLA é um modelo de inteligência artificial que combina visão, linguagem e ação em uma única arquitetura. Diferentemente de modelos tradicionais que focam apenas em uma dessas áreas, o SmolVLA integra essas três capacidades para oferecer uma compreensão mais completa e uma resposta mais precisa às tarefas propostas.

O nome SmolVLA vem da junção de "Smol" (uma gíria para algo pequeno ou eficiente) com "VLA" (Vision-Language-Action), destacando sua proposta de ser um modelo compacto, porém poderoso, capaz de lidar com múltiplas modalidades simultaneamente.
Treinamento com Dados da Comunidade Lerobot
Um dos diferenciais do SmolVLA é o seu treinamento baseado em dados coletados pela comunidade Lerobot, uma iniciativa colaborativa que reúne informações relevantes para o desenvolvimento de IA multimodal. Essa abordagem comunitária traz diversas vantagens:
- Diversidade de dados: A comunidade Lerobot contribui com uma ampla variedade de exemplos, incluindo imagens, textos e comandos de ação, o que enriquece o aprendizado do modelo.
- Atualização contínua: Como a comunidade está sempre ativa, o modelo pode ser constantemente aprimorado com novos dados e cenários.
- Transparência e colaboração: O uso de dados comunitários promove um ambiente mais aberto e colaborativo para o desenvolvimento da IA.
Como o SmolVLA Funciona?
O modelo utiliza técnicas avançadas de aprendizado profundo para processar e integrar informações visuais e textuais, além de gerar ações baseadas nesse entendimento. Seu funcionamento pode ser dividido em três etapas principais:
1. Processamento Visual
O SmolVLA analisa imagens ou vídeos para extrair características relevantes, como objetos, cenários e contextos. Essa etapa é fundamental para que o modelo compreenda o ambiente em que está inserido.
2. Compreensão da Linguagem
Paralelamente, o modelo interpreta comandos, descrições ou perguntas em linguagem natural, permitindo que ele entenda o que é solicitado ou descrito pelo usuário.
3. Geração de Ações
Com base na análise visual e na compreensão textual, o SmolVLA decide qual ação executar, seja responder a uma pergunta, realizar uma tarefa específica ou interagir com o ambiente de forma inteligente.
Aplicações Práticas do SmolVLA
As possibilidades de uso do SmolVLA são vastas e impactam diversos setores. Confira algumas aplicações promissoras:
- Robótica: Robôs equipados com SmolVLA podem interpretar comandos complexos, reconhecer objetos e agir de forma autônoma em ambientes dinâmicos.
- Assistentes virtuais: Sistemas que entendem imagens e textos simultaneamente podem oferecer respostas mais completas e contextuais aos usuários.
- Educação: Ferramentas educacionais interativas que combinam visão e linguagem para criar experiências de aprendizado personalizadas.
- Segurança: Monitoramento inteligente que interpreta cenas visuais e comandos para detectar situações de risco e agir rapidamente.
Por que o SmolVLA é um Marco na IA Multimodal?
O SmolVLA representa um avanço significativo por unir eficiência e capacidade multimodal em um único modelo. Enquanto muitos sistemas multimodais são pesados e complexos, o SmolVLA destaca-se por ser compacto e treinado com dados reais e diversificados da comunidade Lerobot, o que aumenta sua robustez e aplicabilidade.
Além disso, o modelo abre caminho para uma nova geração de IA que não apenas entende o que vê e lê, mas também age de forma inteligente, aproximando-se cada vez mais da cognição humana.
Conclusão
O SmolVLA é um exemplo claro de como a colaboração comunitária e a inovação tecnológica podem se unir para criar soluções de IA poderosas e eficientes. Ao integrar visão, linguagem e ação, esse modelo promete transformar o modo como máquinas interagem com o mundo, trazendo benefícios para robótica, assistentes virtuais, educação e muito mais.
À medida que a comunidade Lerobot continua contribuindo com dados e melhorias, podemos esperar que o SmolVLA evolua ainda mais, consolidando-se como uma ferramenta essencial no futuro da inteligência artificial multimodal.
Fique atento ao "IA em Foco" para mais novidades sobre o SmolVLA e outras inovações em inteligência artificial!