SmolVLM: Modelos Compactos que Revolucionam a IA Multimodal

A inteligência artificial multimodal está em constante evolução, e a busca por modelos mais eficientes e acessíveis nunca foi tão intensa. Recentemente, a HuggingFace apresentou uma novidade que promete transformar a forma como desenvolvedores e pesquisadores lidam com modelos de linguagem visual: os novos SmolVLM de 256M e 500M parâmetros. Neste artigo, vamos explorar o que são esses modelos, suas vantagens e o impacto que podem trazer para o ecossistema de IA.
O que é o SmolVLM?
SmolVLM é uma família de modelos de linguagem visual (Visual Language Models) desenvolvida para oferecer alta performance em tarefas multimodais, como interpretação de imagens e textos simultaneamente, mas com uma pegada muito mais leve em termos de tamanho e recursos computacionais.
Tradicionalmente, modelos multimodais robustos exigem bilhões de parâmetros, o que limita seu uso a grandes centros de pesquisa e empresas com infraestrutura robusta. O SmolVLM, por outro lado, propõe uma abordagem minimalista, mantendo a qualidade sem sacrificar a eficiência.
Novidades: Modelos de 256M e 500M Parâmetros
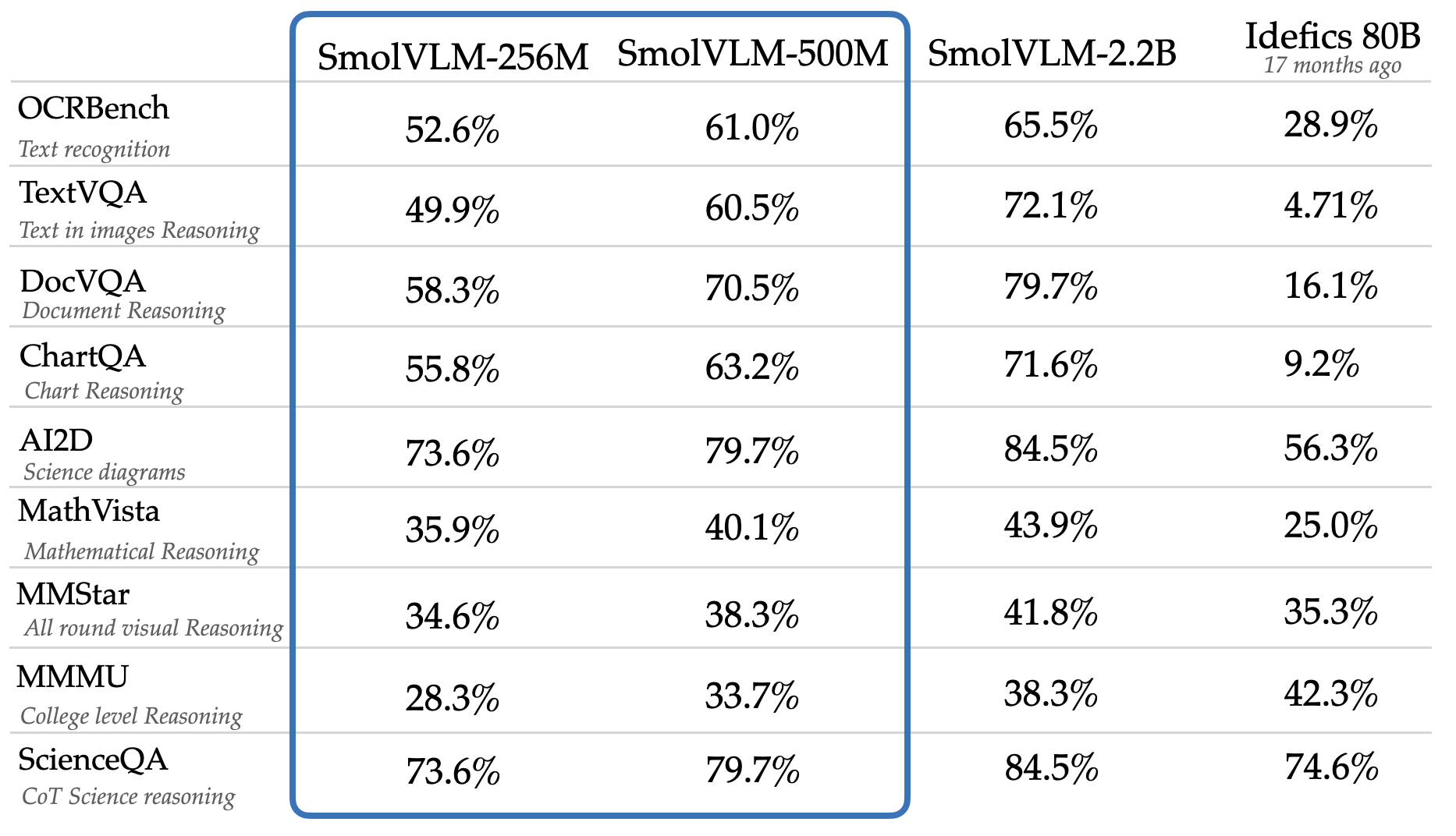
A grande novidade apresentada pela HuggingFace são os dois novos tamanhos para o SmolVLM: 256 milhões e 500 milhões de parâmetros. Para se ter uma ideia, esses modelos são consideravelmente menores do que muitos concorrentes no mercado, que frequentemente ultrapassam a casa dos bilhões de parâmetros.
Essa redução drástica no tamanho traz benefícios diretos:
- Menor custo computacional: menos memória e processamento são necessários para treinar e executar os modelos.
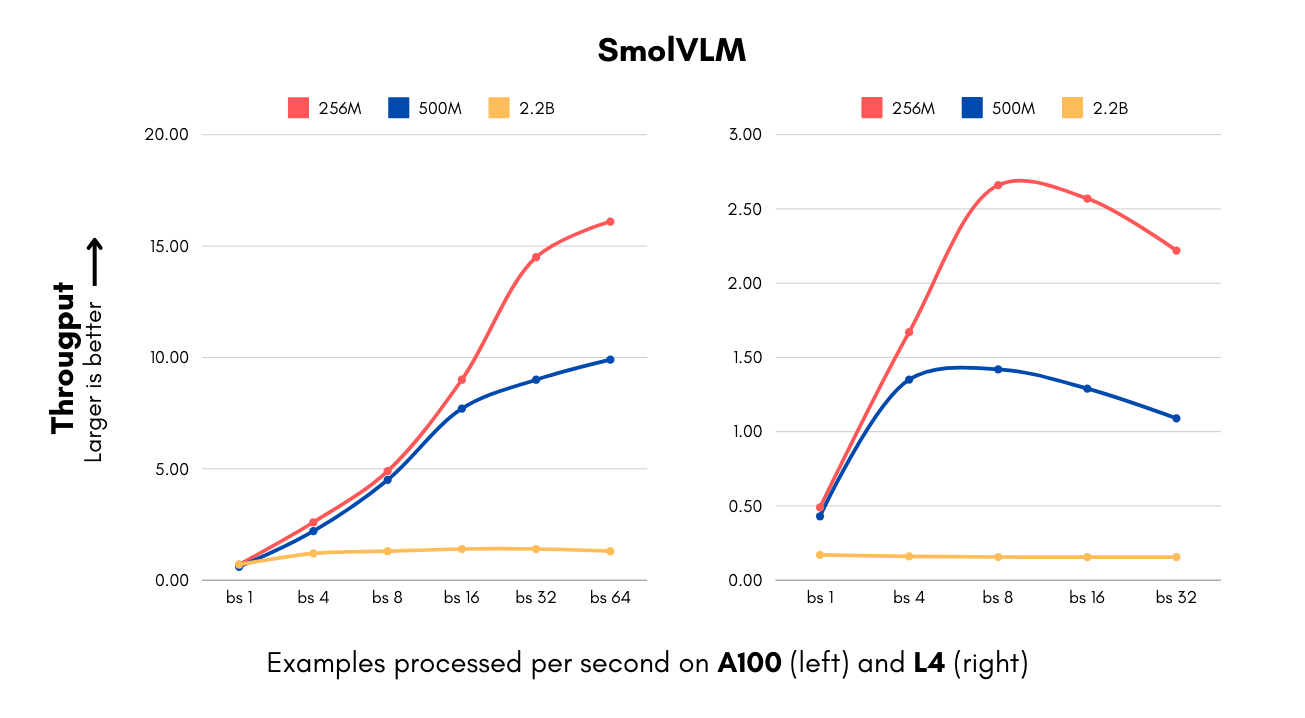
- Velocidade: inferências mais rápidas, essenciais para aplicações em tempo real.
- Acessibilidade: desenvolvedores com hardware limitado podem experimentar e implementar soluções multimodais.
Desempenho e Aplicações
Apesar do tamanho reduzido, os SmolVLM 256M e 500M não deixam a desejar em desempenho. Eles são capazes de realizar tarefas complexas como:
- Reconhecimento e descrição de imagens;
- Geração de legendas automáticas;
- Respostas a perguntas baseadas em imagens;
- Classificação multimodal;
- Entre outras aplicações que combinam texto e visão computacional.
Esses modelos são ideais para startups, pesquisadores acadêmicos e entusiastas que buscam explorar IA multimodal sem a necessidade de grandes investimentos em infraestrutura.
Por que Modelos Menores São o Futuro?
O avanço em modelos compactos como o SmolVLM reflete uma tendência importante no campo da inteligência artificial: a democratização do acesso à tecnologia. Modelos menores e eficientes permitem que mais pessoas e organizações possam inovar, criar e aplicar IA em diferentes contextos.
Além disso, a sustentabilidade é uma preocupação crescente. Modelos gigantescos demandam enorme consumo de energia, o que impacta o meio ambiente. Modelos menores ajudam a reduzir essa pegada, promovendo uma IA mais verde.
Como Acessar e Utilizar os SmolVLM?
A HuggingFace disponibiliza esses modelos em sua plataforma, facilitando o acesso para desenvolvedores e pesquisadores. Com uma comunidade ativa e ferramentas integradas, é possível experimentar, ajustar e implementar os SmolVLM em projetos reais com relativa facilidade.
Para quem deseja iniciar, recomenda-se:
- Explorar a documentação oficial da HuggingFace;
- Testar os modelos em notebooks interativos;
- Participar da comunidade para trocar experiências e obter suporte.
Conclusão
Os novos SmolVLM de 256M e 500M parâmetros representam um passo significativo rumo a uma IA multimodal mais acessível, eficiente e sustentável. Eles oferecem uma excelente oportunidade para ampliar o uso da inteligência artificial em diferentes setores, desde educação até negócios e pesquisa.
Se você é entusiasta ou profissional na área, vale a pena ficar de olho nessas novidades e experimentar o potencial dos modelos compactos da HuggingFace. O futuro da IA passa por soluções inteligentes que combinam alta performance com baixo custo e impacto ambiental reduzido — e o SmolVLM está na vanguarda dessa transformação.