Transcrições Ultrarrápidas com Whisper e Endpoints de Inferência da HuggingFace

Nos últimos anos, a transcrição automática de áudio tem se tornado uma ferramenta essencial para diversas aplicações, desde a acessibilidade até a análise de dados. A HuggingFace, referência em soluções de inteligência artificial, trouxe uma inovação que promete acelerar ainda mais esse processo: os Endpoints de Inferência para o modelo Whisper. Neste artigo, vamos explorar como essa tecnologia funciona, suas vantagens e como ela pode transformar a forma como lidamos com transcrições.
O que é o Whisper?
Whisper é um modelo de transcrição automática desenvolvido para converter áudio em texto com alta precisão. Ele é capaz de reconhecer múltiplos idiomas e sotaques, tornando-se uma solução robusta para diversas necessidades. Com a popularização dos modelos de linguagem e reconhecimento de fala, o Whisper se destacou por sua eficiência e qualidade.
Desafios das transcrições tradicionais
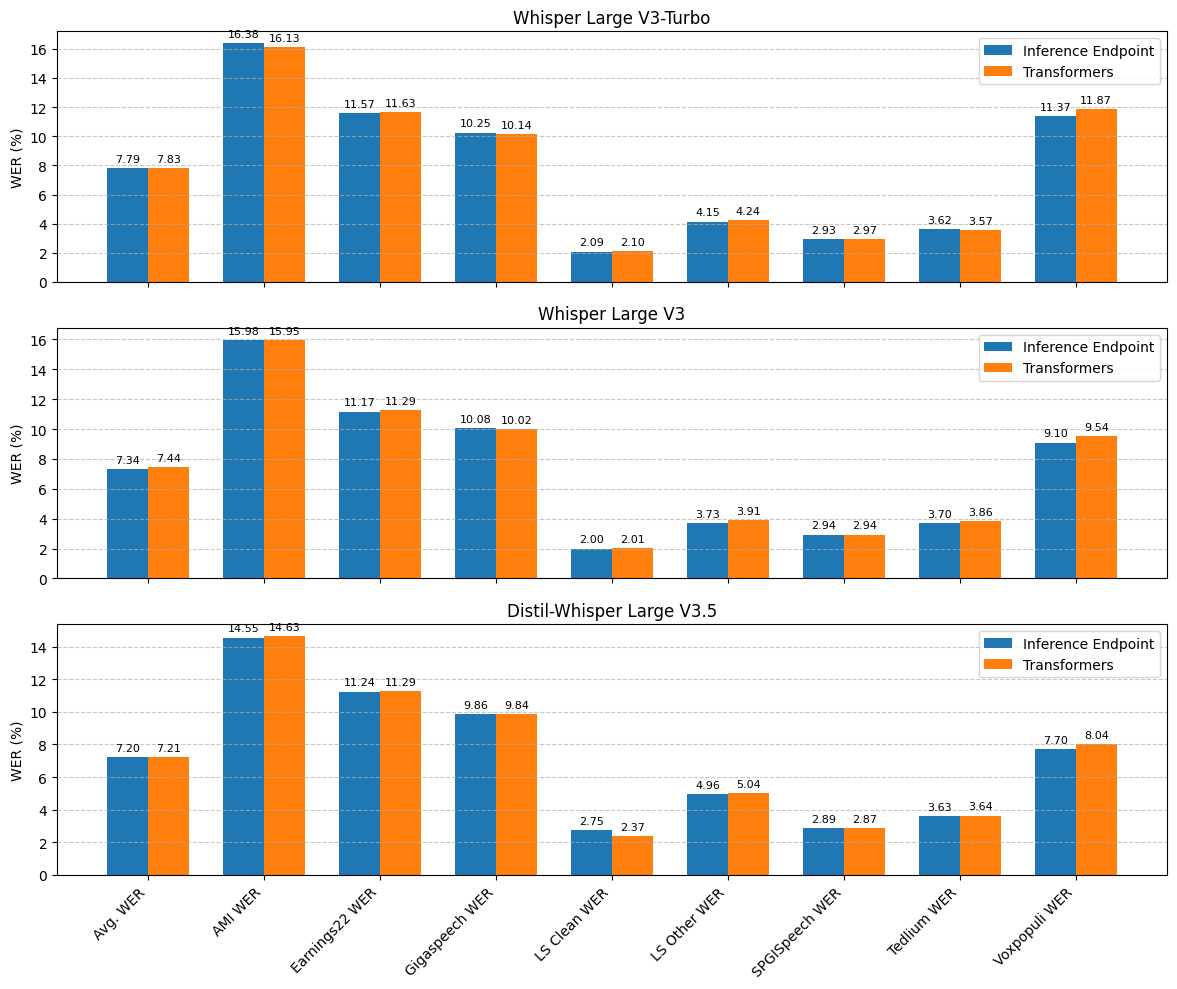
Apesar dos avanços, a transcrição automática ainda enfrenta desafios, principalmente relacionados à velocidade e escalabilidade. Processar grandes volumes de áudio pode ser demorado e exigir infraestrutura robusta, o que limita seu uso em tempo real ou em aplicações que demandam respostas rápidas.
Endpoints de Inferência: o que são e por que são importantes?
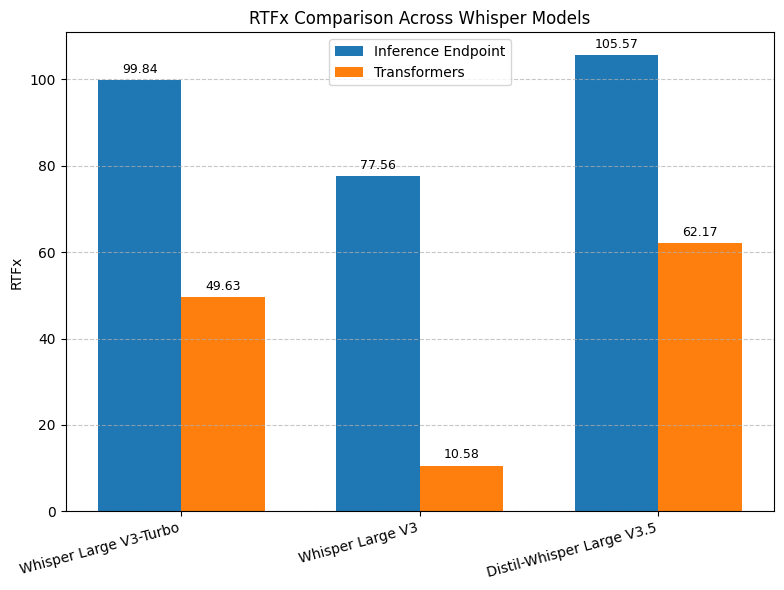
Os Endpoints de Inferência da HuggingFace são serviços gerenciados que permitem executar modelos de IA na nuvem de forma simples, rápida e escalável. Ao utilizar esses endpoints, desenvolvedores e empresas podem integrar modelos como o Whisper diretamente em suas aplicações, sem se preocupar com a complexidade da infraestrutura.
Principais benefícios dos Endpoints de Inferência para Whisper
- Velocidade: Processamento ultrarrápido que reduz o tempo de espera para transcrições.
- Escalabilidade: Capacidade de lidar com grandes volumes de dados simultaneamente.
- Facilidade de uso: Integração simples via API, sem necessidade de gerenciar servidores.
- Atualizações automáticas: Acesso imediato às melhorias do modelo sem esforço adicional.
Como funciona na prática?
Imagine que você tenha uma plataforma de podcasts e queira disponibilizar legendas automáticas para seus episódios. Com os Endpoints de Inferência para Whisper, basta enviar o arquivo de áudio para a API da HuggingFace e receber a transcrição em poucos segundos. Isso permite que o conteúdo seja acessível para pessoas com deficiência auditiva e melhora a experiência do usuário.
Exemplo de integração simples
Utilizando uma chamada HTTP POST para o endpoint, você envia o áudio e recebe a transcrição no formato JSON, pronta para ser exibida ou armazenada. Essa simplicidade acelera o desenvolvimento e reduz custos operacionais.
Impactos no mercado e no desenvolvimento de IA
Com essa tecnologia, empresas de diversos setores podem incorporar transcrição automática de alta qualidade em suas soluções, desde atendimento ao cliente até análise de reuniões e geração de conteúdo. Além disso, a democratização do acesso a modelos avançados como o Whisper estimula a inovação e o surgimento de novas aplicações.
Conclusão
A combinação do modelo Whisper com os Endpoints de Inferência da HuggingFace representa um avanço significativo na transcrição automática. A velocidade, escalabilidade e facilidade de uso tornam essa solução ideal para quem busca eficiência e qualidade. Se você trabalha com áudio, legendas ou análise de voz, vale a pena explorar essa tecnologia e transformar a forma como sua empresa lida com dados sonoros.
Fique atento às novidades do mundo da IA e continue acompanhando o blog "IA em Foco" para mais conteúdos exclusivos e atualizados.