Treinamento Multi-GPU Eficiente com Accelerate ND-Parallel: Guia Completo

Com o crescimento exponencial dos modelos de inteligência artificial, a demanda por treinamento eficiente em múltiplas GPUs nunca foi tão alta. Para desenvolvedores e pesquisadores que buscam acelerar seus processos de treinamento, a HuggingFace apresenta o Accelerate ND-Parallel, uma ferramenta poderosa que simplifica e otimiza o uso de múltiplas GPUs.
O que é o Accelerate ND-Parallel?
O Accelerate ND-Parallel é uma abordagem desenvolvida para facilitar o treinamento distribuído de modelos de machine learning em ambientes com múltiplas GPUs. Ele permite que o trabalho seja dividido de forma inteligente entre os dispositivos, maximizando o uso dos recursos disponíveis e reduzindo o tempo necessário para o treinamento.
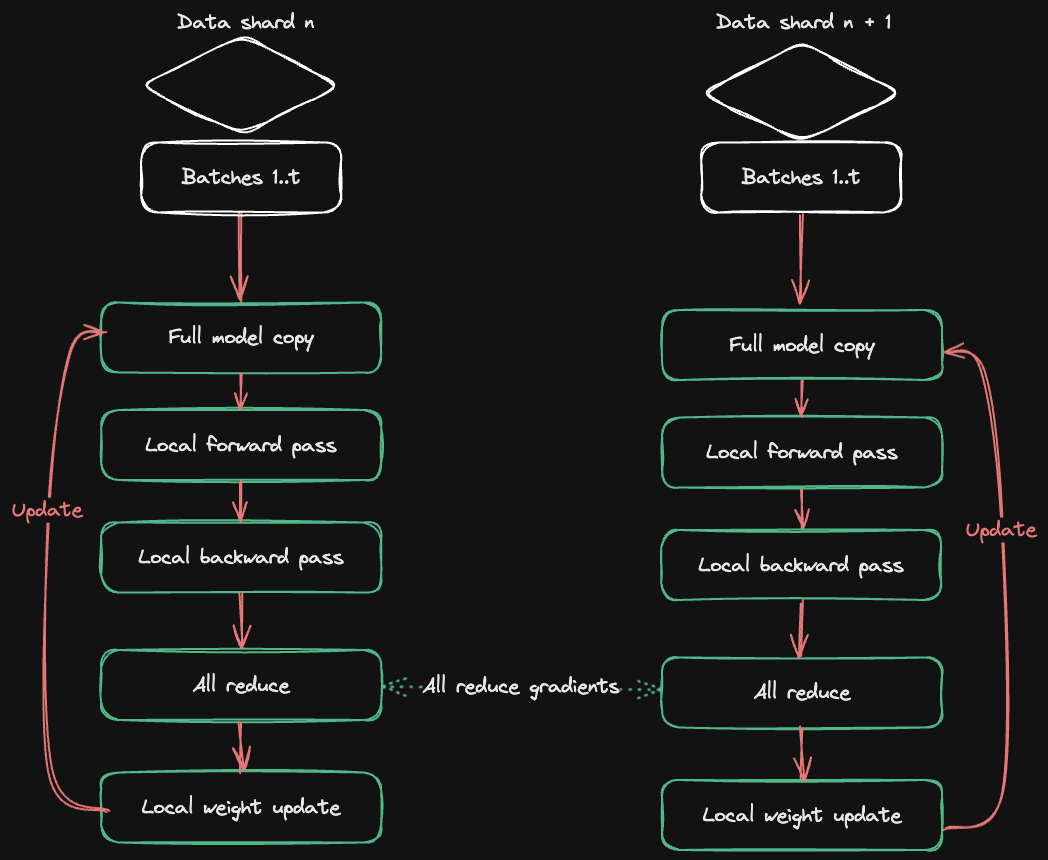
Por que usar múltiplas GPUs?
- Velocidade: Treinar modelos grandes em uma única GPU pode ser extremamente demorado. Utilizar múltiplas GPUs acelera esse processo.
- Escalabilidade: Conforme os modelos crescem em complexidade, a capacidade computacional de uma única GPU pode ser insuficiente.
- Eficiência: Distribuir o trabalho evita gargalos e otimiza o uso do hardware disponível.
Como o Accelerate ND-Parallel funciona?
O Accelerate ND-Parallel utiliza técnicas avançadas de paralelismo para dividir o treinamento do modelo em múltiplas GPUs, gerenciando a comunicação entre elas e garantindo que os dados sejam sincronizados corretamente. Ele oferece uma API simples que abstrai a complexidade do treinamento distribuído, permitindo que desenvolvedores foquem na construção do modelo sem se preocupar com a infraestrutura.
Principais características:
- Configuração simplificada: Com poucos comandos, é possível iniciar o treinamento distribuído.
- Compatibilidade: Suporte a diversos frameworks populares, como PyTorch e TensorFlow.
- Escalabilidade dinâmica: Ajusta automaticamente o uso das GPUs conforme a disponibilidade.
- Comunicação eficiente: Minimiza o overhead da sincronização entre dispositivos.
Passo a passo para iniciar com Accelerate ND-Parallel
Para quem deseja começar a utilizar o Accelerate ND-Parallel, seguem algumas etapas básicas:
1. Instalação
Primeiramente, instale a biblioteca Accelerate da HuggingFace via pip:
pip install accelerate2. Configuração do ambiente
Configure o ambiente para o treinamento distribuído com o comando:
accelerate configEsse comando guiará você por algumas perguntas para definir o número de GPUs, tipo de dispositivo e outras preferências.
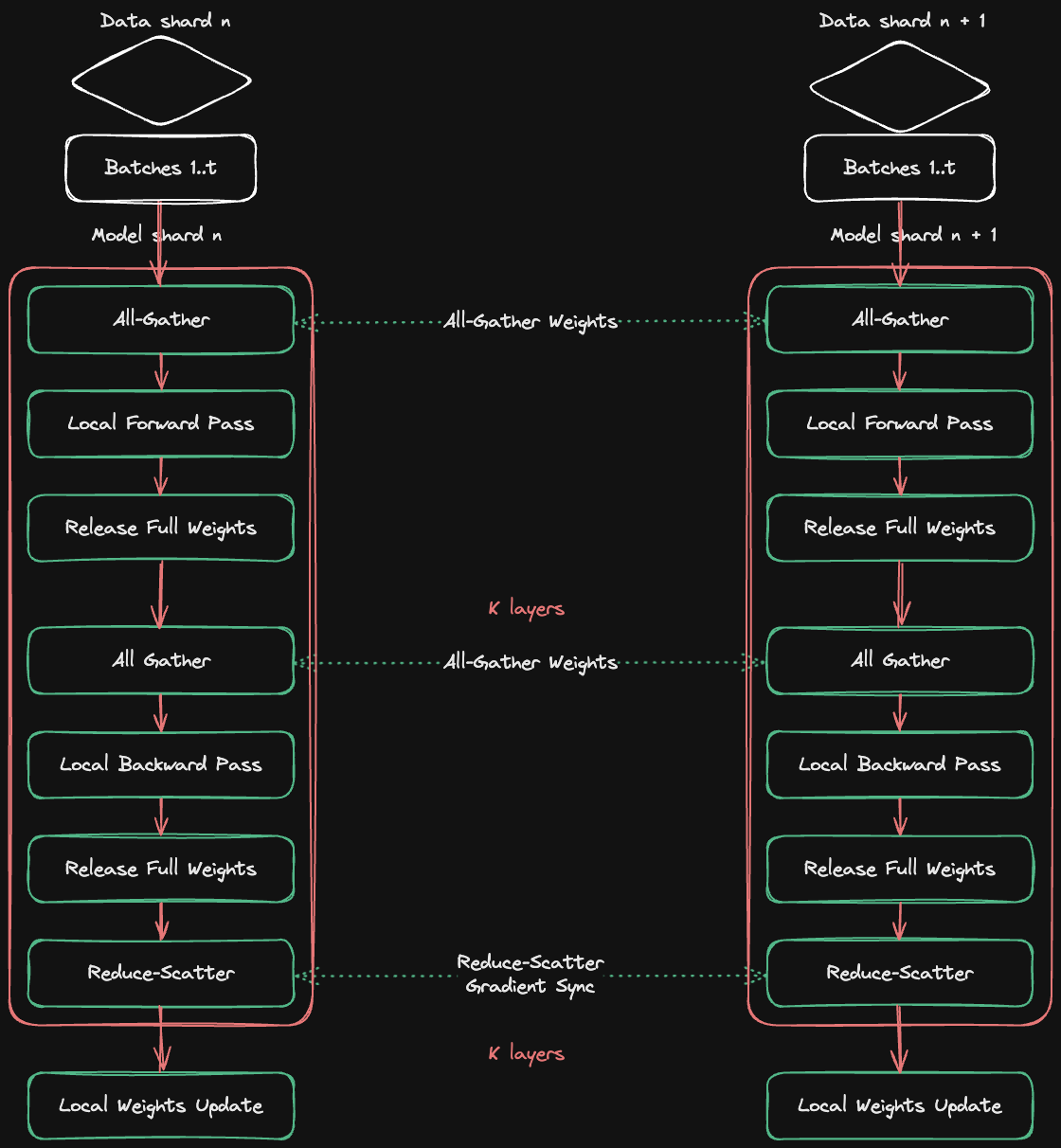
3. Modificação do código
Adapte seu script de treinamento para utilizar a API do Accelerate, que gerencia a distribuição do modelo e dos dados entre as GPUs.
4. Executar o treinamento
Finalmente, execute seu script com:
accelerate launch seu_script.pyBenefícios práticos para projetos de IA
Ao adotar o Accelerate ND-Parallel, equipes de desenvolvimento podem:
- Reduzir o tempo de treinamento drasticamente, permitindo ciclos de desenvolvimento mais rápidos.
- Economizar recursos ao utilizar múltiplas GPUs de forma otimizada, evitando ociosidade.
- Facilitar a escalabilidade de projetos, suportando modelos maiores e mais complexos.
- Diminuir a complexidade técnica do treinamento distribuído, tornando-o acessível mesmo para quem não é especialista em infraestrutura.
Conclusão
O Accelerate ND-Parallel representa um avanço significativo para o treinamento eficiente de modelos de IA em múltiplas GPUs. Com sua abordagem simplificada e poderosa, ele permite que desenvolvedores e pesquisadores acelerem seus projetos, aproveitando ao máximo o potencial do hardware disponível. Se você busca otimizar seu pipeline de treinamento e escalar seus modelos, essa ferramenta é uma excelente escolha.
Explore o Accelerate ND-Parallel e transforme a maneira como você treina seus modelos de inteligência artificial!