TurboQuant: Compressão Avançada da Google para Cache KV em Modelos de Linguagem Extensos
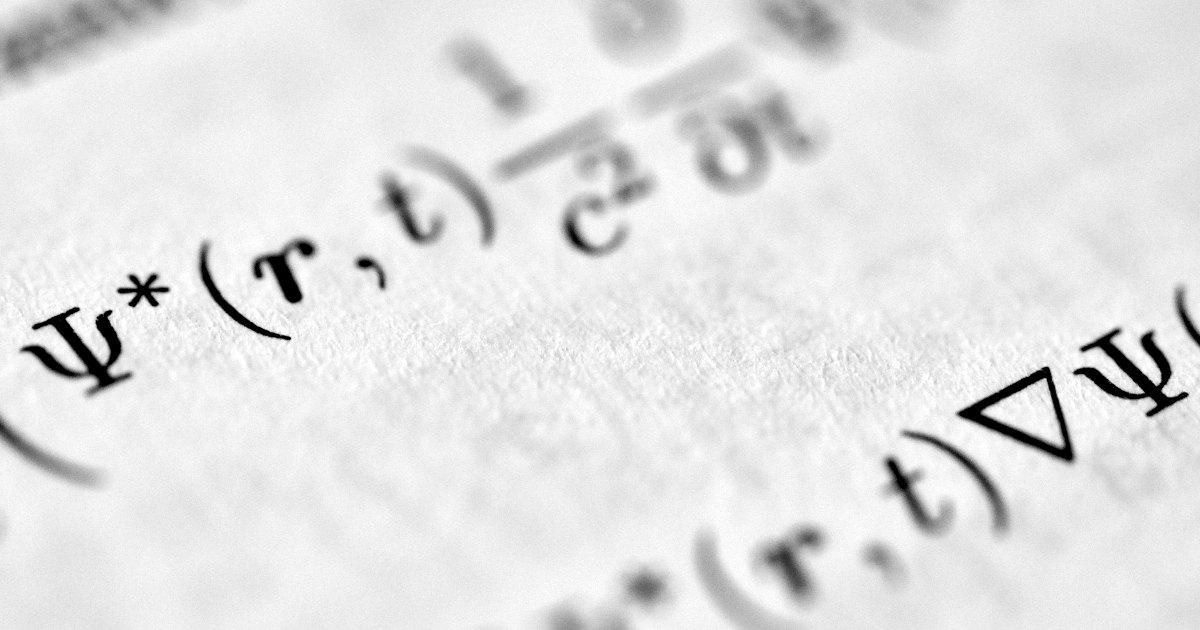
Desafio da Memória em Modelos de Linguagem com Janelas de Contexto Longas
O avanço dos modelos de linguagem de grande porte (LLMs) tem impulsionado aplicações cada vez mais complexas, que demandam janelas de contexto extensas para processar grandes volumes de texto, código ou multimídia. Essa ampliação do contexto, no entanto, traz um desafio técnico significativo: o cache das chaves e valores (Key-Value cache, ou KV cache) cresce linearmente com o número de tokens, consumindo uma enorme quantidade de memória de vídeo (VRAM) durante a inferência.
Por exemplo, pesquisadores da Amazon estimam que executar o modelo Llama 70B com uma janela de contexto de um milhão de tokens requer cerca de 328 GB de VRAM apenas para o KV cache, superando em muito os 140 GB necessários para armazenar os pesos do modelo em BF16. Essa demanda obriga a utilização de configurações multi-GPU caras e complexas, limitando o acesso a essas capacidades.

TurboQuant: Uma Nova Abordagem de Quantização para Compressão do KV Cache
Para enfrentar esse problema, o Google Research lançou o TurboQuant, um algoritmo inovador de quantização que reduz o tamanho do KV cache em até 6 vezes, comprimindo os valores para cerca de 3,5 bits por elemento. A técnica mantém a precisão da inferência praticamente intacta e dispensa o retraining do modelo, facilitando a adoção.
O TurboQuant utiliza uma abordagem em duas etapas:
- Transformação Randomizada de Hadamard: Essa rotação dos vetores mantém propriedades euclidianas essenciais, como distâncias, enquanto distribui os valores de maneira mais uniforme, eliminando a concentração de outliers que prejudicam a quantização em baixa bitagem.
- Transformação Quantizada de Johnson-Lindenstrauss (QJL): Técnica consolidada há mais de uma década, aplicada para remover o viés introduzido pela primeira etapa, garantindo que os produtos internos entre vetores quantizados sejam estimadores não viesados e eficientes dos valores originais.
Resultados e Benchmarks com TurboQuant
Testes iniciais em benchmarks padrão como LongBench e Needle in a Haystack demonstraram que a implementação do TurboQuant em 3,5 bits alcança desempenho equivalente ao de precisão de 16 bits em modelos como Gemma e Mistral, com quase nenhuma perda de acurácia.
Análises da comunidade, como a do repositório PyTorch dedicado, apontam ganhos reais mais conservadores, na faixa de 30% a 40% de redução de memória e aumento de velocidade de processamento. Embora os ganhos máximos não sejam garantidos para todos os casos, a técnica já representa uma melhoria substancial para aplicações que lidam com contextos extensos, como análise de documentos volumosos, filmes ou grandes bases de código.
Implicações Práticas e Limitações do TurboQuant
Uma das dificuldades técnicas enfrentadas pelo TurboQuant é a enorme variação na magnitude dos valores no KV cache durante a inferência. Em modelos como LLaMA-2-7B, os 1% maiores valores podem ser até 100 vezes maiores que a mediana, tornando a quantização linear de 4 bits inviável sem técnicas especializadas, pois os outliers distorcem a grade de quantização e comprometem a precisão dos valores mais comuns.
Ao reduzir a bitagem para 3,5 bits por valor, o TurboQuant possibilita que modelos com janelas muito longas sejam executados em hardware significativamente mais modesto, por exemplo, permitindo que o KV cache do Llama 70B caiba em uma única GPU H100 de 80 GB, ao invés de múltiplas GPUs com configurações complexas.
Por fim, é importante destacar que a compressão do KV cache é um passo fundamental para otimizar a inferência de LLMs, especialmente porque o gargalo de memória cresce com o contexto, enquanto o aumento da velocidade dos dispositivos de memória não acompanha o avanço da capacidade computacional.