TurboQuant: Compressão Extrema que Revoluciona a Eficiência da IA

O desafio da eficiência em modelos de IA
Modelos de inteligência artificial, especialmente aqueles baseados em grandes vetores de alta dimensão, enfrentam um grande obstáculo: o consumo massivo de memória. Esses vetores são essenciais para representar informações complexas, como características de imagens, significados de palavras e propriedades de grandes conjuntos de dados. Porém, armazená-los e processá-los gera gargalos, especialmente na key-value cache, uma espécie de "memória rápida" que armazena dados usados com frequência para acelerar consultas.
O que é TurboQuant e como ele funciona
Desenvolvido pelo Google Research, o TurboQuant é um algoritmo de compressão avançado que permite uma redução extrema do tamanho dos modelos de IA, sem perda de precisão. Ele é especialmente eficaz para comprimir o cache de pares chave-valor e otimizar buscas vetoriais, acelerando processos e reduzindo custos de memória.

TurboQuant opera em duas etapas principais:
- PolarQuant: Primeiro, os vetores são rotacionados aleatoriamente para simplificar sua geometria. Depois, são convertidos do sistema cartesiano para coordenadas polares, transformando a representação em um formato mais compacto e eficiente. Essa técnica elimina a necessidade de normalização dispendiosa, reduzindo a sobrecarga de memória.
- Quantized Johnson-Lindenstrauss (QJL): Em seguida, um pequeno resíduo de erro gerado na primeira etapa é tratado com QJL, que usa um truque matemático para codificar os dados restantes em apenas 1 bit, sem custo adicional de memória e com alta precisão na recuperação das informações.
Resultados expressivos em benchmarks
O TurboQuant foi avaliado em benchmarks rigorosos como LongBench, Needle In A Haystack, L-Eval e RULER, utilizando modelos abertos como Gemma e Mistral.
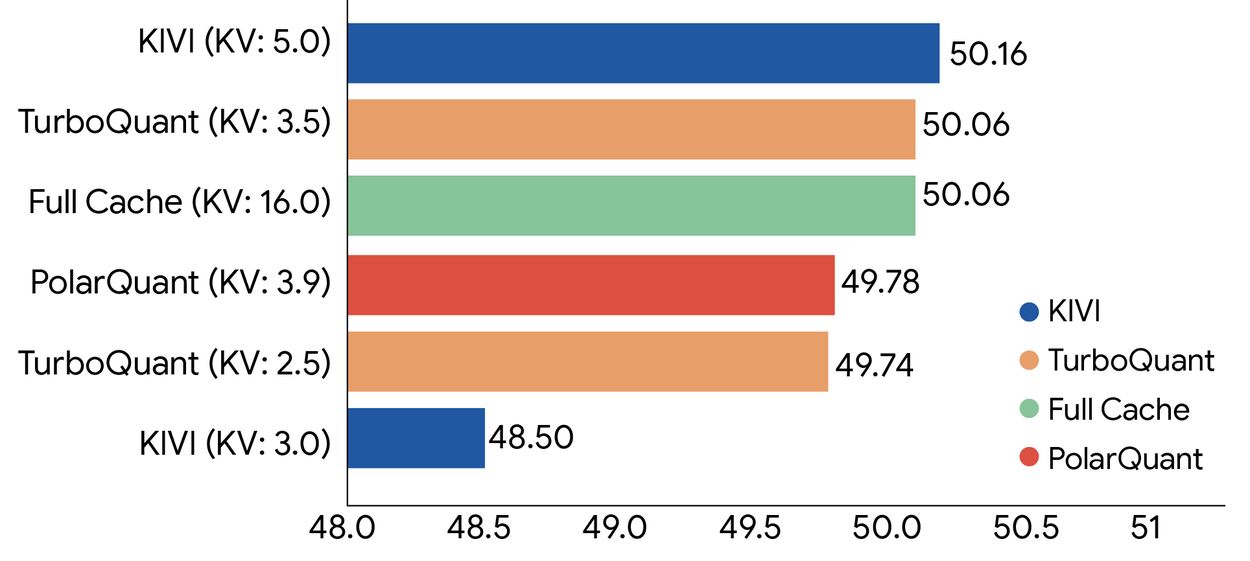
Os testes demonstraram que TurboQuant consegue comprimir o cache chave-valor em até 6 vezes, mantendo a precisão intacta. Em tarefas complexas de busca semântica, como encontrar informações específicas em grandes volumes de texto, o método alcançou resultados perfeitos, com desempenho superior a técnicas tradicionais que exigem ajustes específicos para cada conjunto de dados.
Além disso, o algoritmo oferece ganhos de velocidade notáveis, com até 8 vezes mais rapidez na computação dos scores de atenção em GPUs H100, comparado ao processamento padrão de 32 bits.
Limitações e avanços futuros
Embora TurboQuant apresente resultados impressionantes, sua aplicação ainda está focada em compressão de cache e buscas vetoriais. A pesquisa destaca que, apesar de não requerer treinamento adicional ou fine-tuning, a integração em sistemas diversos pode demandar adaptações específicas. O trabalho é um avanço teórico e prático, com garantias matemáticas de eficiência próximas aos limites teóricos, o que reforça sua robustez para sistemas em larga escala.
Além da compressão, a técnica tem grande potencial para melhorar buscas semânticas em escala massiva, um componente-chave da evolução das ferramentas de pesquisa modernas que vão além das palavras-chave para entender intenções e significados.
Por que essa pesquisa importa no mundo real
Com a crescente integração da IA em produtos cotidianos, desde grandes modelos de linguagem até mecanismos de busca semânticos, a eficiência no uso de memória e velocidade de processamento torna-se crítica. TurboQuant oferece uma solução que permite construir e consultar índices vetoriais gigantescos com baixa latência e alta precisão, reduzindo custos e aumentando a escalabilidade.
Isso significa respostas mais rápidas, menor consumo de energia e maior capacidade de lidar com volumes crescentes de dados, impactando diretamente a experiência do usuário e a sustentabilidade tecnológica.
Links úteis para aprofundamento
Leia também

Hugging Face lança simulação econômica com cinco modelos de IA para entender mercados emergentes
8 de junho de 2026
Projeto Amazing Digital Dentures: os desafios de criar aventuras digitais com IA
8 de junho de 2026
Her: a detetive que analisa suas sessões de Claude Code com inteligência e segurança
7 de junho de 2026