VAKRA: Novo Benchmark da IBM para Avaliação Avançada de Agentes de IA em Ambientes Corporativos

A IBM Research, em parceria com a Hugging Face, lançou o VAKRA, um benchmark inovador que avalia a capacidade de agentes de inteligência artificial em realizar raciocínio composicional e uso de ferramentas em ambientes corporativos complexos. Diferentemente de benchmarks tradicionais, que focam em habilidades isoladas, o VAKRA testa a execução de fluxos de trabalho multi-etapas, integrando chamadas a APIs e recuperação de documentos em linguagem natural.
O que é o VAKRA e como funciona?
O benchmark VAKRA oferece um ambiente executável no qual agentes interagem com mais de 8.000 APIs localmente hospedadas, que acessam bancos de dados reais distribuídos em 62 domínios. As tarefas exigem cadeias de raciocínio entre 3 e 7 passos, combinando manipulação estruturada de APIs e recuperação não estruturada de informações, respeitando restrições de uso de ferramentas em linguagem natural.

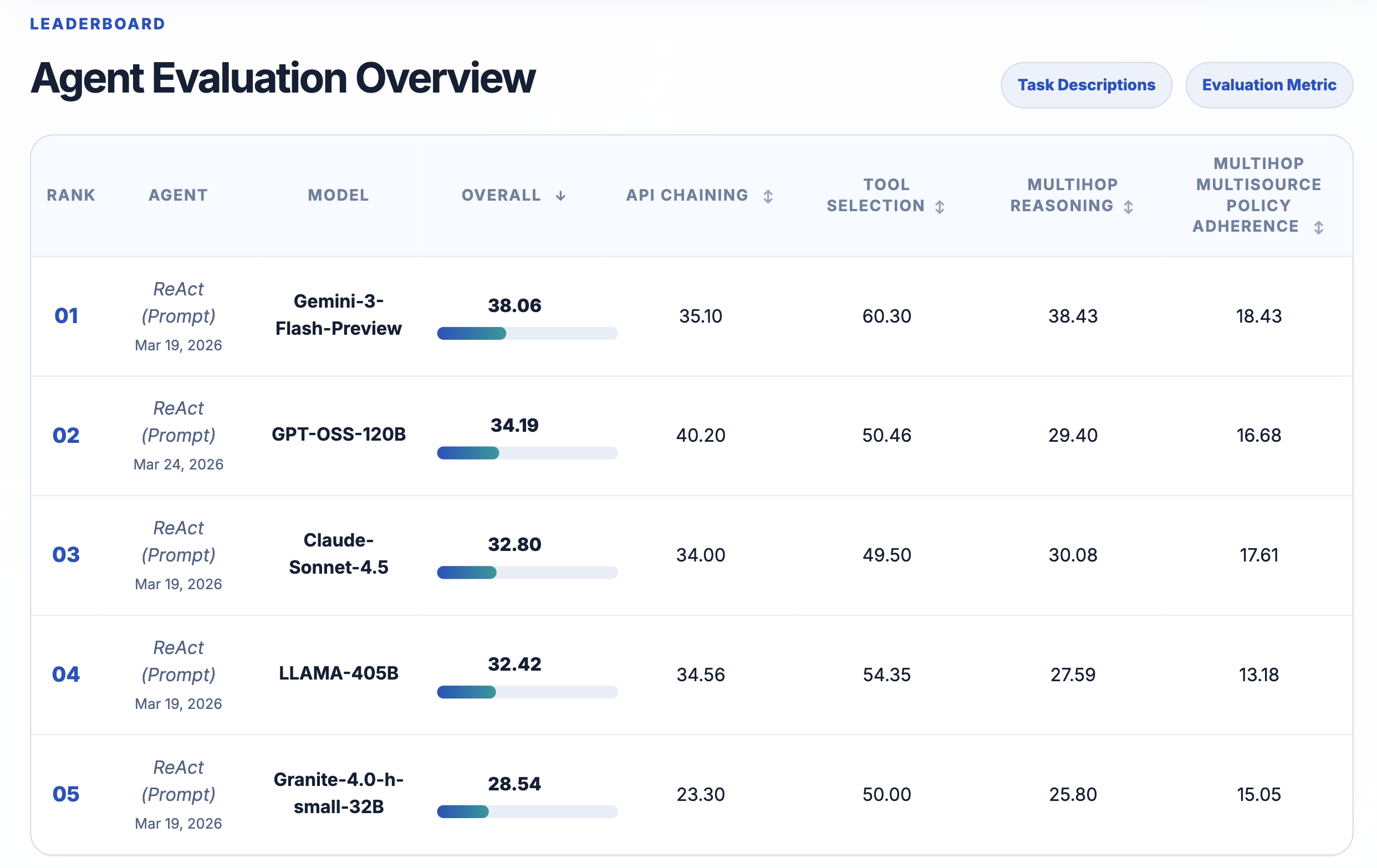
Quatro capacidades avaliadas
- API Chaining com APIs de Business Intelligence (BI): 2.077 instâncias que demandam encadeamento de 1 a 12 chamadas de ferramentas das coleções SLOT-BIRD e SEL-BIRD, abrangendo 54 domínios.
- Seleção de Ferramentas com APIs de Dashboard: 1.597 instâncias em 17 domínios, onde os agentes devem escolher corretamente APIs específicas de coleções REST-BIRD, com até 328 ferramentas por domínio.
- Raciocínio Multi-Hop com APIs de Dashboard: 869 instâncias em 38 domínios que exigem múltiplos saltos lógicos (1 a 5) para combinar evidências e responder consultas complexas.
- Raciocínio Multi-Hop Multi-Fonte e Adesão a Políticas: 644 instâncias em 41 domínios com consultas multi-turno, envolvendo fontes múltiplas (APIs e índices de documentos), e regras explícitas de uso de ferramentas que os agentes devem obedecer.
Framework de avaliação e métricas
O VAKRA adota uma avaliação focada na execução, que não apenas verifica a resposta final, mas também toda a trajetória de chamadas às ferramentas, seus parâmetros e resultados intermediários.
- Para a capacidade 4, a adesão às políticas de uso de ferramentas é verificada programaticamente.
- A sequência prevista de chamadas às ferramentas é comparada com a sequência correta, considerando execuções alternativas válidas.
- Apenas trajetórias válidas seguem para avaliação da resposta final, que é julgada por um modelo de linguagem para garantir consistência factual e fundamentação nas saídas das ferramentas.
Essa avaliação em cascata assegura que agentes sejam recompensados não só por respostas corretas, mas por raciocínios completos e válidos.
Quem pode usar o VAKRA e como acessá-lo?
O VAKRA destina-se a pesquisadores e desenvolvedores que trabalham com agentes de IA avançados, especialmente aqueles focados em ambientes empresariais que demandam integração de múltiplas APIs e fontes de dados.
O benchmark, incluindo o dataset, o leaderboard e o código do avaliador, está disponível gratuitamente no GitHub:
- Repositório oficial no GitHub
- Blog oficial da Hugging Face com análise detalhada
- Instruções para submissão ao leaderboard
Não há custos para acessar ou participar do benchmark.
Impacto prático para desenvolvedores e empresas
O VAKRA oferece uma plataforma robusta para testar agentes em cenários realistas de negócios, onde o sucesso depende da capacidade de integrar múltiplas ferramentas e fontes de dados, respeitando políticas específicas. Isso é crucial para aplicações em análise de dados, atendimento automatizado, gestão empresarial e outras áreas que demandam raciocínio complexo e uso criterioso de recursos.
Além disso, a análise detalhada de falhas disponível no benchmark, como erros na seleção de ferramentas, preenchimento incorreto de parâmetros ou respostas inconsistentes, permite que desenvolvedores aprimorem seus agentes de forma direcionada.
Desempenho dos modelos testados e insights
Entre os modelos avaliados, o GPT-OSS-120B se destacou, especialmente por sua robustez na seleção correta de parâmetros e compreensão das estruturas das ferramentas, superando significativamente outros concorrentes. Modelos que erraram na nomeação de argumentos ou na escolha das ferramentas tiveram desempenho inferior, evidenciando a complexidade do problema.