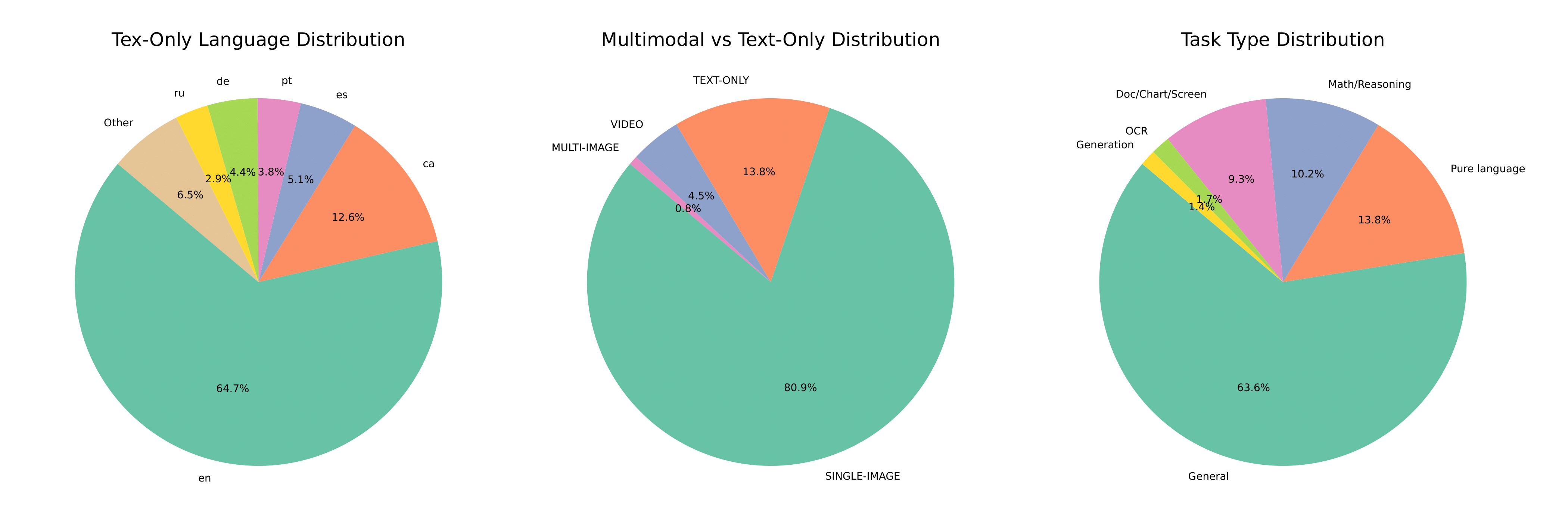
Visual Salamandra: Revolucionando a Compreensão Multimodal na IA

Nos últimos anos, a inteligência artificial (IA) tem avançado rapidamente, especialmente na capacidade de entender e integrar diferentes tipos de dados, como texto, imagem e som. Um dos desafios mais complexos é a compreensão multimodal, que busca combinar informações visuais e textuais para criar modelos mais ricos e precisos. Nesse cenário, o projeto Visual Salamandra, desenvolvido pela HuggingFace, surge como uma inovação que promete expandir os limites do que a IA pode realizar na interpretação multimodal.
O que é o Visual Salamandra?
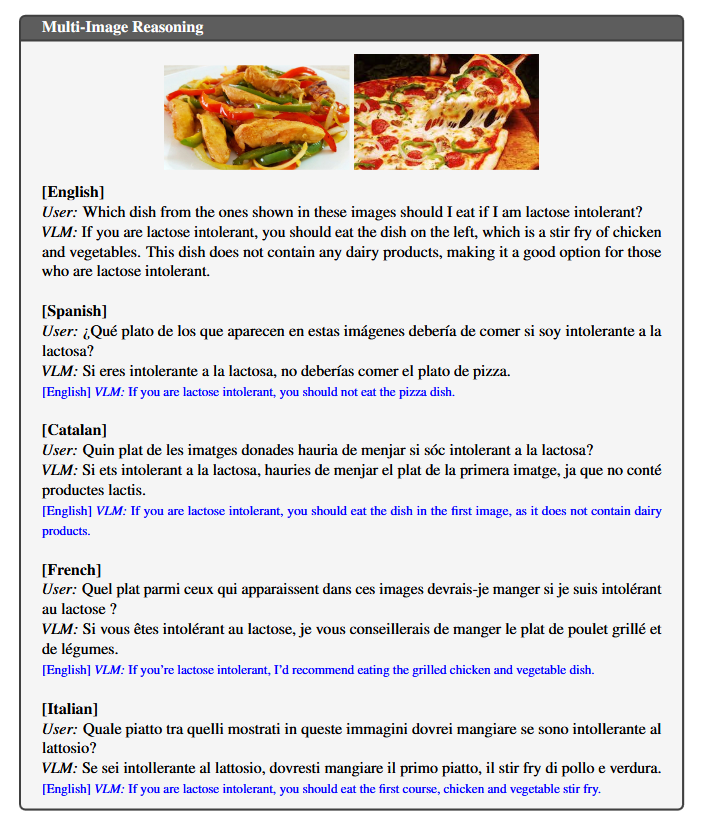
Visual Salamandra é um modelo de inteligência artificial multimodal que integra visão computacional e processamento de linguagem natural para interpretar e responder a dados visuais e textuais simultaneamente. Diferente dos modelos tradicionais que focam em apenas um tipo de dado, o Visual Salamandra é capaz de analisar imagens e texto em conjunto, proporcionando uma compreensão mais profunda e contextualizada.
Por que o nome "Salamandra"?
O nome faz alusão à capacidade de adaptação e regeneração da salamandra, simbolizando a flexibilidade e a robustez do modelo em lidar com diferentes modalidades de informação e aprender continuamente a partir delas.
Principais características do Visual Salamandra
- Integração multimodal avançada: O modelo combina dados visuais e textuais de forma simultânea, permitindo análises mais completas.
- Arquitetura inovadora: Utiliza técnicas modernas de aprendizado profundo para extrair e fundir características de imagens e textos.
- Alta capacidade de generalização: Pode ser aplicado em diversas tarefas, desde descrição automática de imagens até respostas a perguntas complexas envolvendo múltiplas modalidades.
- Treinamento eficiente: Aproveita grandes bases de dados multimodais para otimizar seu desempenho sem perder a escalabilidade.
Aplicações práticas do Visual Salamandra
A versatilidade do Visual Salamandra o torna ideal para diversas áreas, tais como:
- Assistentes virtuais multimodais: Capazes de entender comandos que envolvem imagens e texto simultaneamente.
- Ferramentas de acessibilidade: Que geram descrições detalhadas para pessoas com deficiência visual.
- Monitoramento e análise de mídias sociais: Interpretando imagens e textos para detectar tendências ou conteúdos sensíveis.
- Educação e treinamento: Criando materiais interativos que combinam imagens e explicações textuais.
Desafios e perspectivas futuras
Embora o Visual Salamandra represente um avanço significativo, ainda há desafios a serem superados. A complexidade do processamento multimodal exige grande poder computacional e algoritmos cada vez mais eficientes. Além disso, garantir a interpretação correta e ética dos dados visuais e textuais é fundamental para evitar vieses e erros.
Entretanto, a tendência é que modelos como o Visual Salamandra continuem evoluindo, tornando-se cada vez mais integrados e precisos. A HuggingFace, reconhecida por sua contribuição no desenvolvimento de ferramentas de IA, está na vanguarda dessa transformação, incentivando a comunidade a explorar novas possibilidades multimodais.
Conclusão
O Visual Salamandra representa um marco na inteligência artificial multimodal, abrindo portas para aplicações mais inteligentes e sensíveis ao contexto. Ao combinar visão e linguagem, ele amplia a capacidade das máquinas de entender o mundo de forma mais humana e integrada. Para desenvolvedores, pesquisadores e entusiastas de IA, acompanhar essa evolução é essencial para aproveitar todo o potencial das tecnologias emergentes.
Fique atento às novidades do Visual Salamandra e das inovações da HuggingFace para estar sempre na frente no universo da inteligência artificial multimodal.